Problem
As a database or business intelligence developer I would like to get some understanding of Data Wrangling without learning the specialist languages like Python or R.
Solution
The solution is to understand the basics of Data Wrangling by running some SQL examples revolving around a very small dataset starting from a simple use case and improving your understanding with more practice runs.
About Data Wrangling
Let us get familiar with data wrangling by going through some definitions and simple examples in this tutorial.
What is Data Wrangling?
According to Wikipedia, data wrangling, sometimes referred to as data munging, is the process of transforming (parsing, validating, enriching, structuring, etc.) and mapping data from one "raw" data source data form into another format with the intent of making it more appropriate and valuable for a variety of downstream purposes such as analytics.
We can simply say that the data wrangling process is a method of data cleaning and data preparation by converting it from one form to a more understandable form mainly for preliminary data analytics.
Who is a Data Wrangler?
According to Wikipedia, the term "Data Wrangler" was also suggested as the best analogy to a coder for someone working with data.
Which field does it belong to?
Currently, data wrangling is a standard practice of preparing raw data (also known as dataset) for analysis and visualization which is commonly used in the field of Data Science although its use is not strictly limited to this discipline.
Whose Job is to do Data Wrangling?
Most commonly Data Scientists carry out the professional work of analyzing complex data which includes many different things (methodologies) including data wrangling.
Can a SQL / BI Developer do Data Wrangling?
Yes, a SQL Server Developer, Business Intelligence Developer or Data Analysts can also perform data wrangling as long as he/she has the basic knowledge of the data wrangling steps and this what we are going to learn in this tutorial.
What is a Dataset?
The data being analyzed in some form (such as unstructured or structured) is referred to as Dataset which gets more and more refined after going through different processes including data wrangling.
A semi or fully populated SQL table can also be called a Dataset from a data analysis (data wrangling) perspective.
Data Wrangling Walkthrough in SQL to handle invalid values
We are going to walk through a real-world example of data wrangling from a very basic point of view with help of some simple SQL examples, but before that it is also important to get familiar with your data structures and dataset which is a table of a sample database that we are going to create.
Prerequisites
This tip assumes that the readers are familiar with the basics of databases. Can comfortably write and run T-SQL scripts using the compliant tools such as SQL Server Management Studio (SSMS) or Azure Data Studio and a local or remote instance of SQL Server is installed.
Please note that Azure Data Studio is used in this tutorial as our data wrangling tool to setup and run queries against a sample database installed on a locally hosted SQL Server instance (developer version), but you can follow the same examples using any other compliant database management tool such as SQL Server Management Studio (SSMS).
This tip is an inspiration of the work by Antonio Emilio Badia, Assoc. Professor, CSE department, U. of Louisville.
About the Datset (WatchesDWR)
Our dataset is a SQL database which contains a partially populated single table about watches and that is our subject of interest for data wrangling.
The Watch table has the following columns of interest:
- WatchId: This column uniquely identifies one watch from other
- Color: This gives us the information about the color of the watch
- Case Width: This is the width of the dial of watch
- Case Depth: This is the depth of the dial of watch
- Price: The value / worth of the watch
The overall picture of the Dataset can be visualized as follows:

Setup Datset (WatchesDWR)
We are going to setup a Dataset in the form of creating and populating a SQL database WatchesDWR as follows:
-- Create a new database called 'WatchesDWR'
-- Connect to the 'master' database to run this snippet
USE master
GO
-- Create the new database if it does not exist already
IF NOT EXISTS (
SELECT [name]
FROM sys.databases
WHERE [name] = N'WatchesDWR'
)
CREATE DATABASE WatchesDWR
GO
-- Switch to the WatchesDWR database (created locally)
USE WatchesDWR
-- Creating a watch table
CREATE TABLE [dbo].[Watch]
(
[WatchId] [int] IDENTITY(1,1) NOT NULL,
[Color] [varchar](20) NULL,
[Case Width] INT NULL,
[Case Depth] INT NULL,
[Price] [decimal](10, 2) NULL,
CONSTRAINT [PK_WatchType] PRIMARY KEY CLUSTERED
(
[WatchId] ASC
)
)
-- Insert rows into table 'Watch' in schema '[dbo]'
INSERT INTO [dbo].[Watch]
( -- Columns to insert data into
Color,[Case Width],[Case Depth], Price
)
VALUES
(
'Black',49,20,200.00
),
(
'Blue',45,18,150.00
),
(
'Green',50,15,NULL
),
(
NULL,55,15,170.50
),
(
'-1',NULL,NULL,NULL
),
(
'-2',NULL,20,300
)
Dataset Check
Please do a quick check of your Dataset (sample database) by running the following script against WatchesDWR:
-- View Watch table
-- Select rows from a Table or View '[Watch]' in schema '[dbo]'
SELECT w.WatchId,w.Color,w.[Case Width],w.[Case Depth],w.Price FROM [dbo].[Watch] w
GO
The output is as follows:

Dataset Quick Analysis (Manual)
Now if we quickly look at the Dataset we can clearly see something is missing from the table and that is not complete.
In other words the table is partially populated with some missing data which makes it an excellent case for data wrangling because we must clean the data to analyze it properly as the missing values are more or less time-consuming in the data analysis process to make better decisions.
Data wrangling by grouping data into Null Values and Non-Nulls Values
The first method used in data wrangling is to sort (not to be confused with sort by in SQL) or arrange the data into two meaningful forms:
- Initialized Data (valid values)
- Uninitialized Data (indicated by Nulls in SQL)
Now anything that is not NULL and does not make sense is what you have to look for in this method of data wrangling because that invalid data has to be consolidated (joined) in either initialized form or uninitialized form.
As we can see from the output that the Color column has been initialized with two odd values:
- -1 (row 5)
- -2 (row 6)
Find the invalid values by executing the following SQL script:
-- Get both numeric and negative Color column values from Watch table
SELECT *, ISNUMERIC(Color)
FROM Watch
WHERE ISNUMERIC (Color)=1 AND CAST(Color AS INT)<1
The result set is as follows:
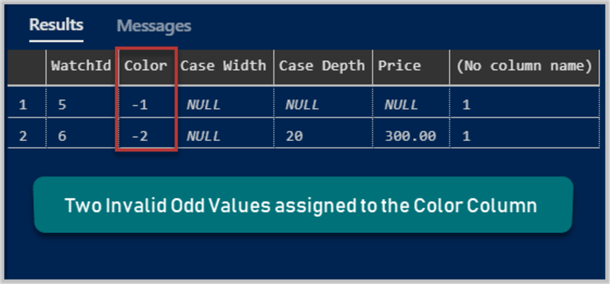
Now we need to move the above odd values (invalid values) to Nulls to improve the Dataset for analysis.
That is if we can search for all the colors where color is denoted by a negative value and change it to NULL by the help of the following SQL script:
-- Data wrangling by grouping data into Null and Non-Nulls by initializing all numeric negative color values with NULLS
UPDATE Watch
SET Color=NULL
WHERE ISNUMERIC
(Color)=1 AND CAST
(Color AS INT)<1
Now let us see the Dataset after we have removed the invalid values with NULLs:
--View Watch table after initializing invalid values with Nulls
SELECT w.WatchId, w.Color, w.[Case Width], w.[Case Depth], w.Price
FROM [dbo].[Watch] w
GO
The results are as follow:

As we can see, the Dataset has been cleaned by using one of the techniques of data wrangling in which we have removed the negative numeric color values and initialized them with NULLs as if they were never assigned.
Data Wrangling by Eliminating Problematic Nulls
We can call those Nulls problematic nulls if they are not important from an analysis point of view.
Although we have now narrowed down the Dataset into Nulls and Non-Nulls we can however remove the rows with Nulls to improve the data analysis further by only focusing on the data which is actually provided rather than left uninitialized.
One way to do this is to look for all the rows where Color is Null and if they are 2-3 percent of the total records then we can remove them rather than keeping them.
However, let us add Case Width and Case Depth columns as well in the data wrangling to understand the bigger picture.
Run the following SQL query to look for problematic Nulls in some of the important columns of the Watch table:
-- look for all the rows where Color is Null
SELECT * FROM dbo.Watch
where COLOR IS NULL
-- look for all the rows where Case Width is Null
SELECT *
FROM dbo.Watch
where [Case Width] IS NULL
-- look for all the rows where Case Depth is Null
SELECT *
FROM dbo.Watch
where [Case Depth] IS NULL
The output is as follows:

Now we can remove any one or all of these problematic rows with Nulls associated with these columns but then this may be a lot of loss of data because we only have 6 rows in total.
However, the fifth row in the above figure has no assigned value for all the columns except the primary key which must exist for the reliability of the table and this is the easy looking target for us to eliminate for better analysis. This takes us to another technique of data wrangling where we remove the rows with Nulls provided those Nulls are very small portion of the main table else this should be avoided.
Please eliminate problematic nulls by the following script:
--Eliminate problematic nulls (excessive nulls) from the Watch table (Dataset)
DELETE FROM dbo.Watch
WHERE Color is NULL
AND [Case Depth] IS NULL
AND [Case Width] IS NULL
AND Price IS NULL
Let us view the refined Dataset now:
-- View Watch table (Dataset) after removing problematic nulls
SELECT w.WatchId, w.Color, w.[Case Width], w.[Case Depth], w.Price
FROM [dbo].[Watch] w
GO
The output is as follows:

We can see the refined Dataset after the problematic nulls row have been removed from it, but please remember we can also remove Nulls for any one column which is not important in the analysis or which is important but has very less number of Nulls as compared to the total records.
Congratulations, you have successfully learned the basics of data wrangling in SQL with the help of some simple examples.
Please stay in touch as more interesting methods and techniques of data wrangling are yet to come.
Next Steps
- Please add more records to the Dataset (Watch table) such as by adding Yellow, Brown, White and Red Colors but leaving rest of the columns as Nulls except the id and see how you can apply data wrangling in this scenario.
- Please setup the sample database OfficeSuppliesSampleV2_Data referenced in this tip and try data wrangling techniques after replacing columns OrderType and Customer with Nulls for all the orders more than OrderId 10.
- Please create a sample database OfficeSuppliesSample by referring to the tip and replace half of the rows of both Quantity and Price column as -1 in the Product table to apply data wrangling in the light of this tip.

Haroon Ashraf’s deep interest in logic and reasoning at an early age of his academic career paved his path to become a data professional.
He holds BSc (Gold Medal) and MSc Degrees in Computer Science and also received the OPF merit award.
His programming career began in 2006 working on his first data venture to migrate and rewrite a public sector database driven examination system from IBM AS400 (DB2) to SQL Server 2000 using VB 6.0 and Classic ASP along with developing reports and archiving many years of data.
His work and interest revolves around Business Intelligence and Database Centric Architectures and his expertise include database and reports design, development, testing, implementation and migration.
He has recently earned “Knowledge Management and Big Data in Business” certificate from The Polytechnic University of Hong Kong.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2020 | Author of the Year Contender – 2018-2020


