By: Siddharth Mehta | Comments (6) | Related: > Reporting Services Dynamic Reports
Problem
Reports designed using SQL Server Reporting Services, have parameters and report data as the two major entities which generally fetch data from database. This is generally facilitated by datasets that fetch data through the medium of a stored procedure. This makes the database logic arguably tightly coupled with the report design and it can be quite problematic when there is a change in the name or location of database objects connected to the report or when the same report needs to be used with context specific logic.
In this tip, we look at a design that would help to decouple the regular implementation approach of a report design. Be advised that this article assumes that the reader has some basic working knowledge of SQL Server Reporting Services 2005 / 2008.
Solution
By creating a facade (interface) implemented in the form of a stored procedure that returns data by executing context specific logic, report design can be decoupled from implementation logic.
Let's consider a scenario, where we have to display a simple report that displays the address of employees, and takes two parameters Location and City. This report is to be developed for a parent organization and sub-companies under this parent organization may use the same report, but with their own data and/or logic implementation.
The script to create the data, objects and the report that is developed in the below exercise can be downloaded here.
Follow the below steps to create the base for testing of our design for the above mentioned scenario.
1) Create a new database called TestDB which would contain tables and stored procedures that we would use in our report.
2) Create two tables called Location and City.
- Location table should have two fields: LocationID, LocationName. Insert few test values like India, UK and SEAsia for example.
- City table would should have CityID, CityName, LocationID. Insert 2 records for each record in Location table.
3) Create three different schemas called India, UK and SEAsia
- Create a stored procedure in each schema with the name as SelectLocation which should select records from City table for the respective region. For eg. UK.SelectLocation stored procedure should select City having the LocationID of UK.
4) Create a stored procedure called SelectCompanyLocation in the dbo schema (interface SP hereafter) which is generally the default schema with the code shown below. This SP would take Location as the input parameter, and execute the SelectLocation SP based on the input value.
In a real-world scenario, there would be a foreign key between the two tables we just created, and the logic to select records from the City table would be implemented in a more intelligent way. To keep focus on the design, the database objects are developed with minimum complexity.
Here is the complete script:
CREATE DATBASE TestDBS GO USE TestDBS GO CREATE TABLE Location (LocationID int, LocationName varchar(50)) insert into Location values (1,'India') insert into Location values (2,'UK') insert into Location values (3,'SEAsia') CREATE TABLE City ( CityID int, CityName varchar(50), LocationID int) insert into City values (1,'Mumbai',1) insert into City values (2,'London',2) insert into City values (3,'Singapore',3) insert into City values (4,'Delhi',1) insert into City values (5,'Birmingham',2) insert into City values (6,'KualaLumpur',3) GO CREATE SCHEMA UK GO CREATE SCHEMA India GO CREATE SCHEMA SEAsia GO CREATE PROC India.SelectCompanyLocation As Select CityName from City where LocationID = 1 GO CREATE PROC UK.SelectCompanyLocation As Select CityName from City where LocationID = 2 GO CREATE PROC SEAsia.SelectCompanyLocation As Select CityName from City where LocationID = 3 GO CREATE PROC SelectCompanyLocation (@Location varchar(50)) As Declare @StrSQL Nvarchar(50) SET @StrSQL = @Location + N'.SelectCompanyLocation' EXECUTE sp_ExecuteSQL @StrSQL |
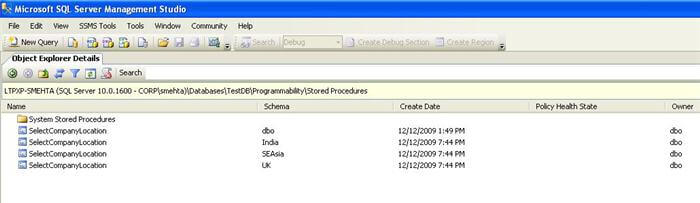
5) Create a new report using Business Intelligence Development Studio (BIDS)
- Create a new report and name it "MyTestReport"
- Setup up a shared datasource and call it "TestDB"
- Create a new dataset and name it "LocationDS" and populate the query with "SELECT LocationName FROM Location"
- Create another dataset and name it "CityDS" and populate the query with "EXEC SelectCompanyLocation @Location = @Location"
- Add a new field to your CityDS dataset called "City" and populate the database field with "CityName"
- Create report parameters Location and City.
- The Location parameter should be setup already. This should be changed to use a query. Select LocationDS as the dataset and LocationName for both the value and label.
- Add parameter "City" and change the prompt to "City". Also make this from a query and select CityDS as the dataset and City for both the value and the label.
If all the steps above are followed as expected, the report should look as shown in the below figure.
Select each different value in the Location parameter and the City parameter values should change. For each different selected value in the Location parameter, a call is made to its corresponding SP.
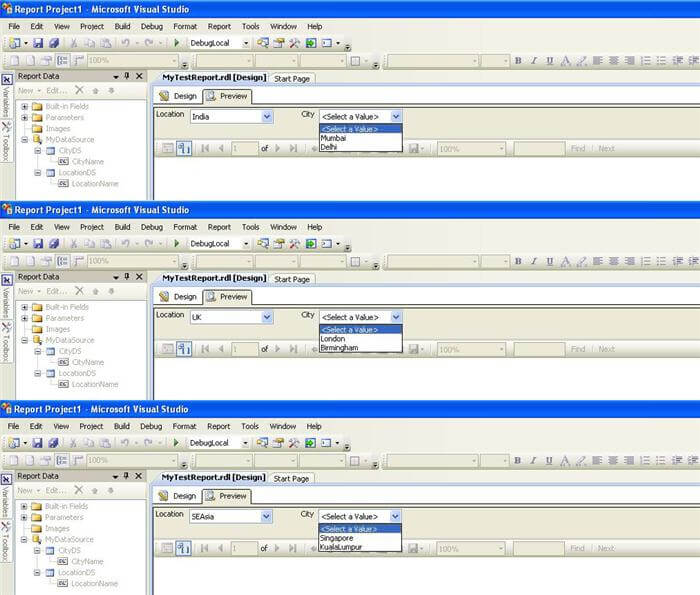
We can make it out that we have decoupled the logic from the report design using the intermediate SP as the interface. Now I would try to answer all the questions that I can think of hitting on this design approach, which should help to clarify the idea and advantages behind using this design.
1) Why should I create 4 stored procs when this can be done using a single stored proc with conditional logic?
At the first glance this would definitely seem that way, but consider the scenario where there are 8 - 10 such sub companies. And all of them have different criteria for evaluating the branch in a city and then deciding whether to allow City for reporting. In that case that single SP would grow too complex. Also due to single SP all the sub-companies would be required to work on the same piece of code.
Secondly, consider a company which is a service provider to its own clients. So each client would be provided the same report design, but would be given the flexibility of implementing its own logic in their own database. In that case this decoupling would be one of the best design options and would work equally well in that scenario too. A single SP in this case would not be an option at all.
2) Why so many schemas have been created and why same SP name is given in each schema?
To have the discreteness of logic, we created three different schemas to draw a boundary. In real time, if the database is shared between all companies, schema would be one of the options to create boundaries. Another option can be different databases on the same server.
The intention of a facade i.e. an interface based design is to publish a common interface to which each logic provider should comply. Consider a new company has been added to the organization, what it would require to get its reporting would be to create its own flavor of stored proc, and the only modification required to the existing system would be a record entry into the City and/or Location table.
3) Is this design performance efficient?
The answer is it really depends on how it is implemented. One complex stored proc may be a little more performance optimized than two SPs in this design. But this design is completely scalable. Also as the logic would be divided into chunks, the performance delta between one single complex SP and two relatively lesser complex SP would be quite little in my viewpoint.
4) What if any sub-company already has an SP with the name that interface requires?
The real elegance of this design lies here. When you use a single SP and bind it directly with the report, its name cannot be changed as the report expects its datasets to get populated from that SP. In this design, only the interface SP gets bound with the report, and all the logic providers can have any name they like. We just need to create a table to list down SP name for each City or Location. Else it can also be hard-coded in the interface SP thru a conditional logic. The only change would always be at Interface SP and the rest gets managed.
5) How many SPs we end up creating by this design? If we have 10 parameters and 4 sub-companies which all use the same logic and data, we still end up with 40 SPs instead of 10?
As I explained above, it depends upon how it is implemented. You can bind all parameters with a single interface SP and incorporate conditional logic within it to route request to the correct SP to pass values back depending upon the parameter from which it is called. The interface SP needs to have a input parameter to recognize which parameter gave a call, and each parameter needs to send its flag to the interface SP. Also with a simple table that manages parameter to SP mapping, same design can be used with just 10 SPs plus one interface SP. I hope one won't mind creating an additional SP considering the advantages it brings to the table. Also for 10 parameters we don't need to create 10 SPs, the same SP can be used for parameters that share the same structure.
6) Are there any other advantages of this design?
The main advantages of this design are as follows:
- It keeps the solution scalable and provides flexibility in implementation
- As all calls from reports are routed thru the interface, all calls can be intercepted for purposes like audit trial, profiling and others.
- It keeps the changes to a minimal, and provides a standard mechanism for future database plugins to the report design.
- This design can handle and well as provides avenues for cross-database or even cross-server environment to use the report design with same ease as any logic contained in the local database.
I hope this tip helps to envision a different angle of development in the database design and development for reporting solutions using SQL Server Reporting Services.
Next Steps
- Create stored procs to return data for the body of the report, based on the selected parameters.
- Create two new database and move stored procs from different schemas in different database and modify the interface stored proc to execute those stored proc from different database using SP_EXECUTESQL command.
- Download the report project for Visual Studio 2008
- Download the report project for Visual Studio 2005






About the author
 Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.
Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
