By: Matteo Lorini | Comments (7) | Related: > Performance Tuning
Problem
Have you ever come across a situation where a query will perform well most of the time, but as soon as you change the predicate value, the same query is 10 to 30 times slower?
Solution
In my opinion, one of the goals of writing tips for MSSQLTips.com is to share valuable information with the community. Not long ago, I came across a valuable webcast about query tuning and optimization. I found it so useful that I decided to share a little bit of it in this tip.
All the examples below have been taken with the permission of the author from www.sqlworkshops.com and in order to make it work you must run on this on SQL Server 2008 64bit edition.
Let's create our sample table:
create table tab7 (c1 int primary key clustered, c2 int, c3 char(2000))
go
begin tran
go
declare @i int
set @i = 1
while @i <= 200000
begin
insert into tab7 values (@i, rand() * 200000, replicate('a', 2000))
set @i = @i + 1
end
commit tran
go
Let's update the statistic with a full scan to make the optimizer work easier:
update statistics tab7 with fullscan go
Let's set statistics time on and execute the following query:
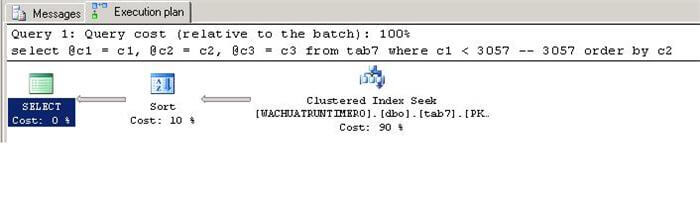
set statistics time on go declare @c1 int, @c2 int, @c3 char(2000) select @c1 = c1, @c2 = c2, @c3 = c3 from tab7 where c1 < 3057 -- 3057 order by c2
The is the time it took to run on my machine: CPU time = 16ms, elapsed time = 15ms
The query ran fine. It only took 15ms (milliseconds) of elapsed time. If we check the actual execution plan we can see that 90% of the cost is spent on the clustered index seek.
Let's change the predicate value to 3058 and run the same query again.
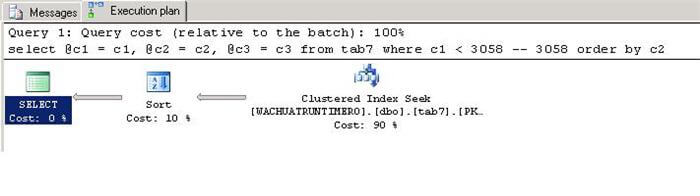
declare @c1 int, @c2 int, @c3 char(2000) select @c1 = c1, @c2 = c2, @c3 = c3 from tab7 where c1 < 3058 -- 3058 order by c2
The is the time it took to run on my machine: CPU time = 16ms, elapsed time = 207ms
Wow, the query now takes 207ms of elapsed time. The query with predicate 3058 is now 13 times slower than the same one with predicate 3057. Why? If we take a look at the new execution plan, we can see that it has not changed. The optimizer is using the same plan for both queries.
Someone may think that adding an index on c1 would speed up our query, but the answer is no, because c1 is not using an equal (=) predicate but a range predicate (<).
So, why is the second query much slower?
Let's take a look at tempDB activity. Let's run the following query and take note of the results. (Note: I have only 1 tempDB file on my computer)
select num_of_reads, num_of_bytes_read,
num_of_writes, num_of_bytes_written
from sys.dm_io_virtual_file_stats(db_id('tempdb'), 1)
This is the output:
num_of_reads = 5643 num_of_bytes_read =361488384 num_of_writes 5434 num_of_bytes_written =353394688
Let's run the second query again:
declare @c1 int, @c2 int, @c3 char(2000) select @c1 = c1, @c2 = c2, @c3 = c3 from tab7 where c1 < 3058 -- 3058 order by c2
and monitor tempDB again:
select num_of_reads, num_of_bytes_read,
num_of_writes, num_of_bytes_written
from sys.dm_io_virtual_file_stats(db_id('tempdb'), 1)
This is the output:
num_of_reads =5740 num_of_bytes_read =367755264 num_of_writes =5530 num_of_bytes_written =359661568
When the query runs with predicate 3057 there is no activity on tempDB, but when it runs with predicate 3058 we can see tempDB activity.
Let's do another test.
Let's start SQL Server Profiler and monitor "Sort Warnings". If we run the query with predicate 3057 we do not see any Sort Warnings however, we can see they exist if we run the query with predicate 3058.

We can now conclude that the query with a predicate greater and equal to 3058 is slower than the one with predicate equal to or less than 3057, because SQL Server executes the sort operation in tempDB and not in memory.
Of course, if we eliminate the order by clause, the query will perform well, however our goal is to make the query perform well in spite the order by clause.
Let's run the following query in a loop and take note of the SPID number. In my case it is 60.
while 1=1 begin declare @c1 int, @c2 int, @c3 char(2000) select @c1 = c1, @c2 = c2, @c3 = c3 from tab7 where c1 < 3057 -- 3057 order by c2 end
In another query window let's run the following:
select granted_memory_kb, used_memory_kb, max_used_memory_kb from sys.dm_exec_query_memory_grants where session_id = 60
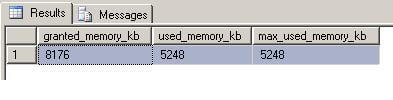
We can see that the above query was granted 8176KB of memory and used only 5248KB. Enough memory was granted by SQL to execute the sort operation in memory.
Now, let's repeat the above steps using the same query with predicate 3058
while 1=1 begin declare @c1 int, @c2 int, @c3 char(2000) select @c1 = c1, @c2 = c2, @c3 = c3 from tab7 where c1 < 3058 order by c2 end
In another query window let's run the following :
select granted_memory_kb, used_memory_kb, max_used_memory_kb from sys.dm_exec_query_memory_grants where session_id = 60
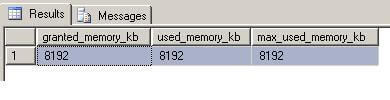
Now, we can see that the query used all the granted memory and because it was not enough to successfully execute the sort operation in memory, SQL had to use tempDB to complete the sort.
To make the query run consistently fast in spite of the sort operation, we need to trick SQL and let it allocate more memory for our query, but how do we do it?
Simply by increasing the estimated row size, SQL will allocate more memory to the query allowing it to execute the sort in memory.
Let's rewrite the query as follows:
declare @c1 int, @c2 int, @c3 varchar(4500) select @c1 = c1, @c2 = c2, @c3 = convert(varchar(4500),c3) from tab7 where c1 < 3058
Now, let's include the execution plan and run it.
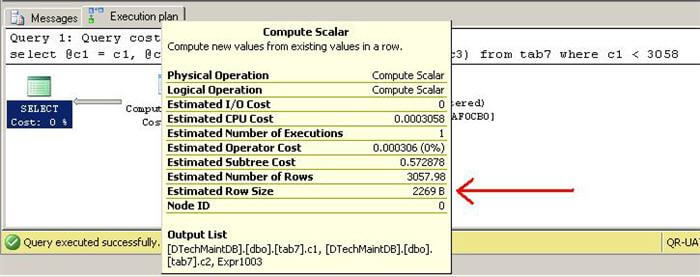
Much to our surprise, we can see that the introduction of a compute scalar has made SQL think that the estimated row size is 2269 and therefore it allocated more memory to the query allowing the sort operation to be executed in memory.
Next Steps
- Play around with above query and make some changes to see how SQL behaves with different predicate values.
- Review these other SQL Server tuning tips






About the author
 Matteo Lorini is a DBA and has been working in IT since 1993. He specializes in SQL Server and also has knowledge of MySQL.
Matteo Lorini is a DBA and has been working in IT since 1993. He specializes in SQL Server and also has knowledge of MySQL.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
