By: Aaron Bertrand | Comments (1) | Related: > TSQL
Problem
In my last tip, I showed the impact of persisting a computed column to individual data and index pages. At the end of the tip, I posed the following questions for these same operations at scale:
- Does the operation cause a significant increase in pages or a large number of page splits?
- Does the operation create fragmentation?
- Does the operation block other queries?
- Does the operation generate significant log activity?
- Does it make more sense to create an index *after* a computed column has been persisted?
- Are these observations consistent when a persisted computed column is later made to be *not* persisted?
Today I'm going to deal with a few of those questions, using a table with 2.5 million rows.
Solution
First, we need a template for a table that we're going to create, with a few extra columns just to make sure each row takes up some legitimate space on a page:
CREATE TABLE dbo.Comp ( id INT IDENTITY(1,1), some_big_int BIGINT, some_filler CHAR(255) NOT NULL DEFAULT 'a', comp AS (100-id), CONSTRAINT pkComp PRIMARY KEY CLUSTERED (id) );
Then a script that would fill this table up with 2.5 MM rows:
INSERT dbo.Comp(some_big_int)
SELECT TOP (2500000) o2.[object_id]
FROM master.sys.all_objects AS o
CROSS JOIN master.sys.all_objects AS o2;
Next, we have to figure out exactly what we're going to be testing. I came up with the following six scenarios to test the impact of performing, in different sequences, the operations required to make a computed column persisted and indexed:
- Test 1: Populate the above table with 2.5 MM rows, persist the column, create the index
- Test 2: Populate the above table with 2.5 MM rows, create the index, persist the column
- Test 3: Create the table *without* the computed column, fill it with 2.5 MM rows, create the computed column, persist the column, create the index
- Test 4: Create the table *without* the computed column, fill it with 2.5 MM rows, create the computed column persisted, create the index
- Test 5: Create the table with the computed column already persisted, fill it with 2.5 MM rows, create the index
- Test 6: Create the table with the computed column already persisted, create the index, then fill it with 2.5 MM rows
For each test, we're going to re-create a database from scratch, and allocate 3 GB immediately for data and 6 GB for log (to prevent unexpected growth operations from interfering with our observations). Then we're going to measure the following:
| Metric | Method |
|---|---|
| Duration of each operation in the sequence | Simple delta in SYSDATETIME() |
| Resulting size of the table | page_count, avg_fragmentation_in_percent
from
sys.dm_db_index_physical_stats() |
| Level of fragmentation | |
| Number of "bad" page splits generated | Event counts from Jonathan Kehayias' Extended Event session |
| Net impact to the transaction log |
DBCC SQLPERF(LOGSPACE); |
And for tests where the table or any index ends up being severely fragmented, we're going to add an online rebuild operation (and time that too) to make sure the end result is optimal.
The test scripts are rather long and tedious, and I will likely blog about them separately. In the meantime, I am just going to share the results, because those are more interesting anyway.
Results
I ran all 6 tests 10 times, and took down the averages. I've rounded in most cases for simplicity, particularly in cases where the numbers for any given test were exactly the same every time.
Tests 1 through 4
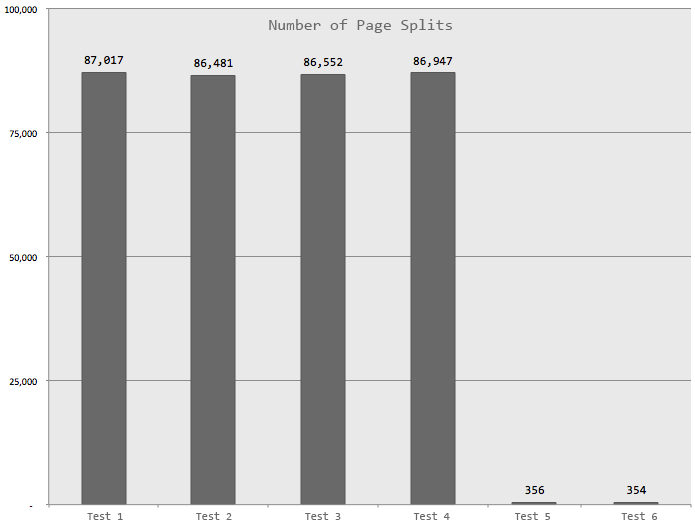
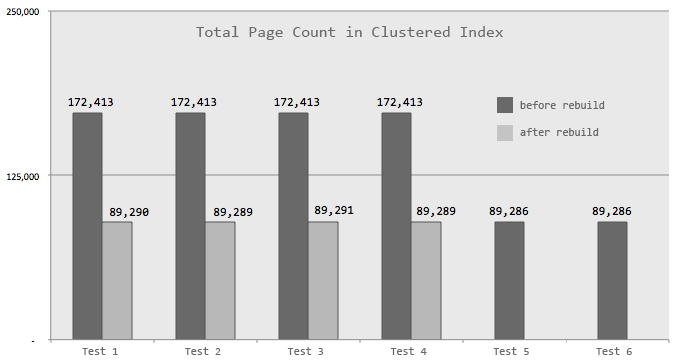
These tests all yielded about 99.2% fragmentation in the clustered index after the column was made persisted, and an initial page count of over 172,000 (both of these before the rebuild, of course). They all used about 69.3% of the transaction log (0.693 * 6 GB = ~4.2 GB), and each test yielded over 86,000 page splits. The average duration for the first four tests was roughly the same, ranging from 49 to 55 seconds. In almost all cases, more than half of this time was taken by the clustered index rebuild.
Tests 5 and 6
Both of these tests already had the column marked as persisted before a single
row was added to the table, so SQL Server was able to organize the clustered
index in such a way that very few page splits occurred, virtually no fragmentation
was present, and no rebuild was required. Test 5 was almost 50% faster; it seems
that creating the index after populating the data made much better use of I/O
than maintaining the index during the insert. (Next time I'll test with
TABLOCKX).
Charts showing the results for a few metrics follow.
Duration
This chart simply shows total duration, and also duration without any rebuilds:
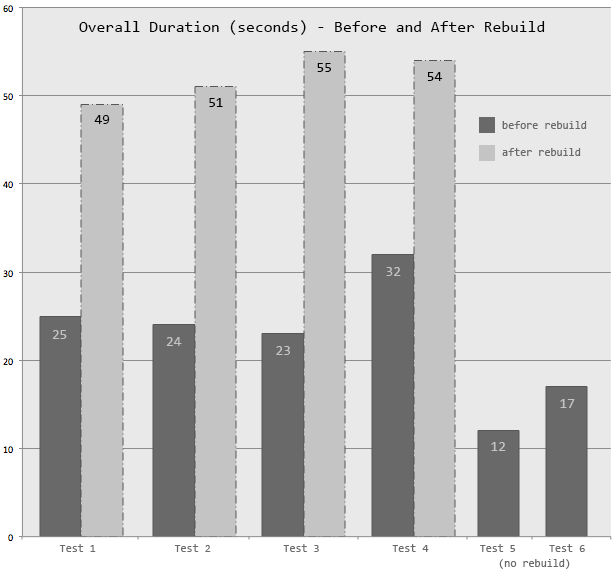
Duration Breakdown
I stacked each test using a timeline-style chart so that you could see both how long each test took in whole, and where time was spent in each case.
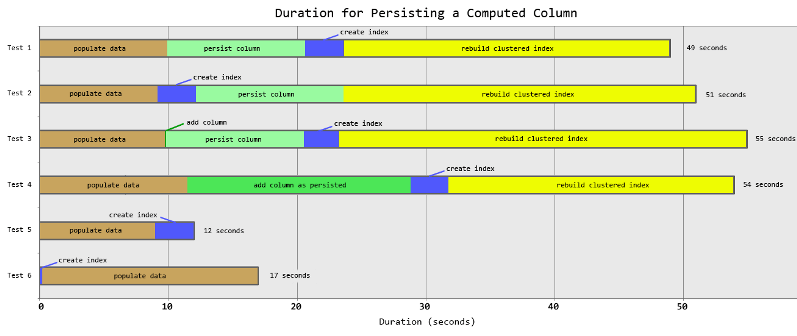
"Bad" Page Splits
This chart demonstrates the number of bad page splits that were caused in each test, mostly by persisting the computed column (a quite small number of page splits occur during other operations, such as initial data population and index creation and/or rebuild):
Page Count
The total number of pages in the clustered index as a result of persisting the computed column. This chart also shows the result after the rebuild for tests 1 through 4:
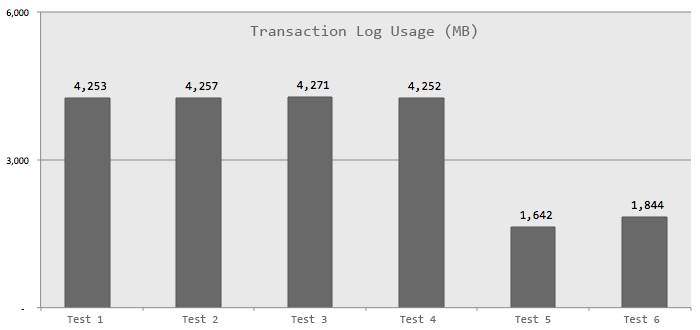
Transaction Log Usage
Based on
DBCC SQLPERF(LOGSPACE);, this chart shows how much log was used in
the user database during each test (while the tempdb log was used, it was negligible
- at most 1.768 MB). It is interesting to note - while not broken down this
way on the chart - the index rebuild was only 21% of the log usage in the first
four tests, so it is not solely responsible for the difference:
Conclusion
Based on these results, it is clear that much less work is required when the computed column is persisted up front (but not indexed until after population). If you can, you would get the job done quickest if you can take a maintenance window, create a new version of the table with the persisted column already defined, populate that table, and create the index (then swap the new table into the old table's spot by renaming or transferring schemas).
I did not get around to test locks and blocking (for the index-related operations,
Enterprise customers can get around any blocking using ONLINE = ON),
and I'm going to leave the less common operation of un-persisting a computed column
for another day (or as another exercise for the reader).
Next Steps
- Review the following tips and other resources:
- Change All Computed Columns to Persisted in SQL Server
- What Happens When a Computed Column is Persisted in SQL Server?
- Using Computed Columns in SQL Server with Persisted Values
- How to create indexes on computed columns in SQL Server
- Getting creative with Computed Columns in SQL Server
- Deterministic and Nondeterministic Functions (MSDN)
- COLUMNPROPERTY (Transact-SQL) (MSDN)
- Indexes on Computed Columns (MSDN)
- Guidelines for Online Index Operations (MSDN)
- Tracking Problematic Pages Splits in SQL Server 2012 Extended Events (Jonathan Kehayias)






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
