Problem
I have read the previous tips on Big Data Basics series of tips and have an overview of Big Data, Hadoop, and the related concepts. My current employer is more of a Microsoft shop and we use Microsoft technologies day-in and day-out. My employer is planning to implement one of our upcoming projects using Hadoop. So I would like to know about Microsoft’s Hadoop offering and get prepared before the start of the project.
Solution
In this tip, we will take a look at Microsoft’s Hadoop offering and get an overview of Microsoft’s Hadoop Distribution.
Microsoft has a Hadoop Distribution known as HDInsight. Like other distributions available in the market, HDInsight contains Apache Hadoop as its core engine.
Hadoop vs. HDInsight Architecture
Typical Hadoop Architecture
As we have seen in the Big Data Basics Tip Series, here is a typical architecture of Apache Hadoop.
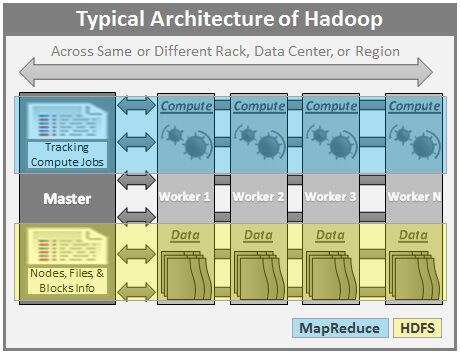
Source – Big Data Basics – Part 3 – Overview of Hadoop
Here are few highlights of Apache Hadoop Architecture:
- Hadoop works in a master-worker / master-slave fashion.
- HDFS (Hadoop Distributed File System) offers a highly reliable storage and ensures reliability, even on commodity hardware, by replicating the data across multiple nodes.
- MapReduce offers an analysis system which can perform complex computation on large datasets.
- Master contains the Namenode and Job Tracker components.
- Namenode holds the information about all the other nodes in the Hadoop Cluster, files present in the cluster, constituent blocks of files and their locations in the cluster, and other information useful for the operation of Hadoop Cluster.
- Job Tracker keeps track of the individual tasks/jobs assigned to each of the nodes and coordinates the exchange of information and results.
- Each Worker / Slave node contains the Task Tracker and Datanode components.
- Task Tracker is responsible for running the task assigned to it.
- Datanode is responsible for holding the data.
- The nodes present in the cluster can be present in any location and there is no dependence on the location of the physical node.
- Apache Hadoop is at the core of various Hadoop Distributions available on the market.
Source – Big Data Basics – Part 3 – Overview of Hadoop
Typical HDInsight Architecture
Here is a typical architecture of Microsoft HDInsight.
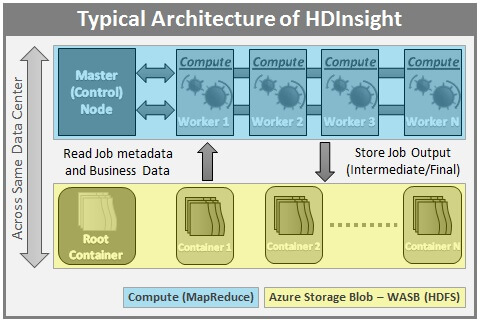
Here are the highlights of Microsoft HDInsight Architecture:
- HDInsight is built on top of Hortonworks Data Platform (HDP).
- HDInsight is 100% compliant with Apache Hadoop.
- HDInsight is offered in the cloud as Azure HDInsight on Microsoft’s Azure Cloud.
- HDInsight is tightly integrated with Azure Cloud and various other Microsoft Technologies.
- HDInsight can be installed on the Windows operating system unlike the majority of the distributions which are based on the Linux operating system.
- HDInsight also works in a master-slave fashion. Master / Control Node (Head node) controls the overall operation of the Cluster. A Secondary Head node is also included as part of Azure HDInsight deployments.
- HDInsight can be configured to store the data either on HDFS within HDInsight cluster nodes or on Azure Blob Storage. The most common approach is to use Azure Storage to store the data, intermediate results, and the output and not store data on individual nodes.
- User data (Data to be processed) and job metadata resides in Windows Azure Storage – Blob (WASB). WASB is an implementation of HDFS on Azure Blob Storage.
- Individual nodes of the cluster offer MapReduce functionality.
- The Master node reads the job metadata and the user data from Blob Storage and uses it to do the processing. The intermediate and the final results are stored in the Blob Storage.
Storing Data on Azure Blob Storage – Few Highlights
This unique architecture of HDInsight, which stores the data on Azure Blob Storage, offers various advantages over other Hadoop distributions. Here are few highlights of this unique architecture:
- Cluster can be provisioned and destroyed as and when required and the data is still available on the Blob Storage even after the cluster is destroyed. This is highly cost effective as we don’t need to keep the cluster active to access the data.
- Storing the data on Blob Storage, which is a common storage, allows other tools/processes to access/use this data for other processing, reporting, etc.
- Azure Storage Account (associated with the Cluster) and the HDInsight Cluster (to be created) should be located in the same data center.
- Microsoft implements Azure Flat Network Storage technology to offer a high speed connectivity between WASB and compute nodes.
Different ways of deploying Hadoop on Microsoft’s Azure Cloud
There are couple of different ways to deploy HDInsight in Microsoft Azure Cloud.
Manual Deployment
We can manually deploy and configure Hadoop on Microsoft’s Azure Cloud. Here are few highlights of this approach:
- Provision Virtual Machines on Azure (IaaS). VMs with any kind of operating system, depending upon the Hadoop distribution, can be provisioned.
- Install Hadoop on those virtual machines. Core Hadoop or other Hadoop distributions can be installed.
- Configure those VMs as a Hadoop cluster.
- This manual process of deploying Hadoop involves a lot of time and effort and is prone to errors unless worked on by experienced Hadoop Administrators.
Deployment using Azure HDInsight
We can deploy Hadoop as Azure HDInsight in a few simple, proven, and tested steps defined by Microsoft, which takes care of all the necessary configurations, Hadoop version management, etc. Here are few highlights of this approach:
- Easy to Deploy – We can deploy the cluster in less time with tested and proven methods / steps defined by Microsoft (via the Azure portal or through Windows PowerShell).
- Provision a cluster with the required number of nodes, depending upon processing needs, and destroy the cluster when you are done. This way, you pay only for what you use.
- By using Azure Storage to store the data, one can retain the data even after the cluster is destroyed unlike the other distributions where the data resides on the data nodes and cluster should be available to access that data.
- The data stored in Azure storage can be accessed / used by other processes / applications as appropriate.
- With Azure’s flexibility, one can easily scale up / down the resources depending upon the usage / need.
Now that we have built the foundation by understanding the basics of Microsoft HDInsight offering, we will start exploring other aspects of this distributions in the next tips in this series. Stay tuned!
Next Steps
- Check out the tips on Big Data
- Check out the tips on Microsoft Azure
- Check out my previous tips
- Stay tuned for the next tip in this series!

Dattatrey Sindol (aka Datta) is a Business Intelligence enthusiast, passionate developer, and blogger. He started his career in November 2006 and since then has worked on various technologies including SQL Server BI, Power BI, Microsoft Azure, & Azure HDInsight within Microsoft Stack and other Cloud & Big Data technologies outside Microsoft Stack. Currently, he is working as an Associate BI Architect at a leading IT Services company in India (Bangalore). Datta also is a Microsoft Certified IT Professional (MCITP) in SQL Server Business Intelligence 2008.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2014 | Author Contender – 2014