By: Burt King | Comments | Related: > Fragmentation and Index Maintenance
Problem
I have SQL Server 2014 Enterprise edition and the online reindex process sometimes blocks other processes because the reindex process needs to take SCH-S locks and then a SCH-M lock at the end of the process which blocks subsequent processes. The SCH-M lock isn’t compatible with other locks and therefore blocks all other processes from being granted a lock on the table causing a slowdown in the system. In a highly transactional, 7x24 environment this isn’t acceptable. In this tip we will look at a new option available with SQL Server 2014 Enterprise edition, managed lock priority, a mechanism which allows the DBA to better manage the locks inherent with online reindexing.
Solution
SQL Server 2014 introduces a new mechanism to the online reindex process reducing the lock priority of the index rebuild process. When this is in place it allows other processes to proceed past the online reindex rather than waiting behind it for the reindex to complete. This feature, Managed Lock Priority, is available in the Enterprise edition which targets highly transactional and large systems. Microsoft has taken this feature a step further by introducing three options to what happens after a time period expires which is set by the DBA. After that period SQL Server can kill the blocking process the online reindex is waiting for, abort the online rebuild, or jump into the normal priority queue as SQL Server has always done in the past.
Simulating the old behavior
To demonstrate this behavior let’s start by creating a table with some random data we can work with. Since this is an Enterprise edition feature we will need to be working with Enterprise edition or Developer edition of SQL Server 2014. To start we’re going to create a testdb with one table and then populate it with some random data. Create a test database and then run the following script to create a table and populate it.
-- Create a table with primary key create table randomdata ( id int identity, randomNumeric numeric (18,12), randomDatetime datetime2, randomVarchar varchar(100) ); create clustered index cl_idx_id on randomdata(id) --fill the table with data--on my machine this took just under 2 minutes. set nocount on declare @loopcounter int = 1 declare @randomNumeric numeric(18,12) declare @randomDatetime datetime2 declare @randomVarchar varchar(1000) declare @randomString VARCHAR(1000) set @randomString = 'zi g upi vsm trsf yjod o jsbr vpmvrtmd eoyj jpe ;pmh upi br nrrm eptlomh pm upit vp,[iyrt/ [rtsj[d oyd yo,r pgt s bsvsyopm/ mpy vtoyovodomh/ kidy pbrtdtbomh js[[u gsvr' while @loopcounter < 1000000 begin set @randomNumeric = round(rand() * 100,10) set @randomDatetime = dateadd(minute,@randomnumeric,getdate()) set @randomVarchar = SUBSTRING(@randomString,convert(int,@randomNumeric),100 ) insert randomdata ( randomNumeric, randomDatetime, randomVarchar) values (@randomNumeric, @randomDatetime, @randomVarchar) set @loopcounter = @loopcounter + 1 end
Now that we have a table we’re going to simulate how a typical online reindex behaves. In SQL Server Management Studio open three different windows and add the following scripts.
--Window 1 begin transaction select top 1000 * from randomdata with (holdlock) --commit --Commented out on purpose so the transaction holds a lock on the table
--Window 2 alter index cl_idx_id on randomdata rebuild with (ONLINE = ON, fillfactor = 70)
--Window 3 select top 10 * from randomdata
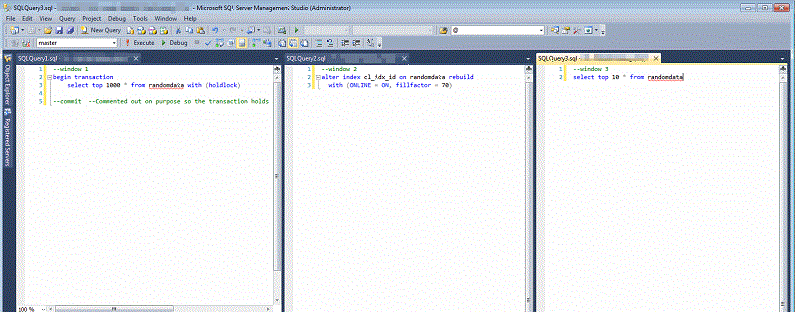
In Window 1 start the script which begins the transaction and selects data. The commit statement is commented out to help demonstrate locking behavior. Start Window 3 --we’ll get back to window 2 in a few moments. What you should see is that Window 3 is able to retrieve data despite Window 1 having an uncommitted transaction. Behind the scenes you can run sp_lock with the SPID from Window 1 and see that the transaction has grabbed many IS and S locks --all of which allow the Window 3 select statement to proceed.
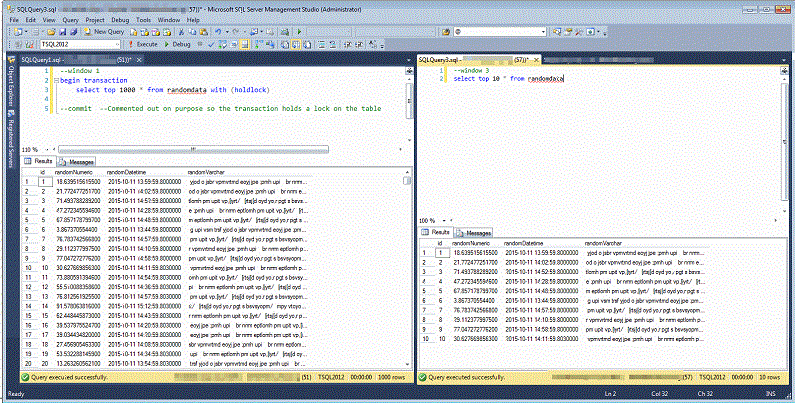
Now we’re ready to start Window 2 --the online reindex. Recall that Window 1 still has the uncommitted transaction. Start Window 2 and let the online reindex run for about a minute and then run sp_lock with the SPID for the Window 2 session. If we’ve waited long enough you’ll see that the online reindex has acquired a number of schema locks, but one is waiting to be converted. Since that lock can't be converted the online reindex is held up from proceeding.
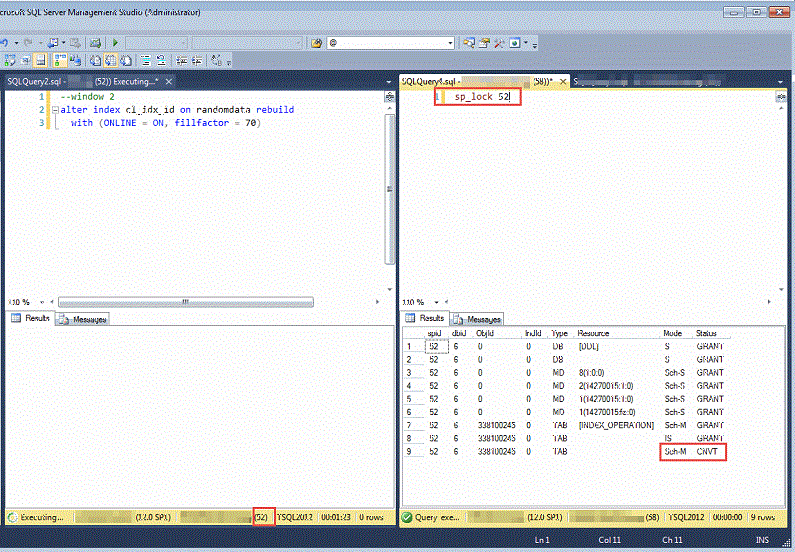
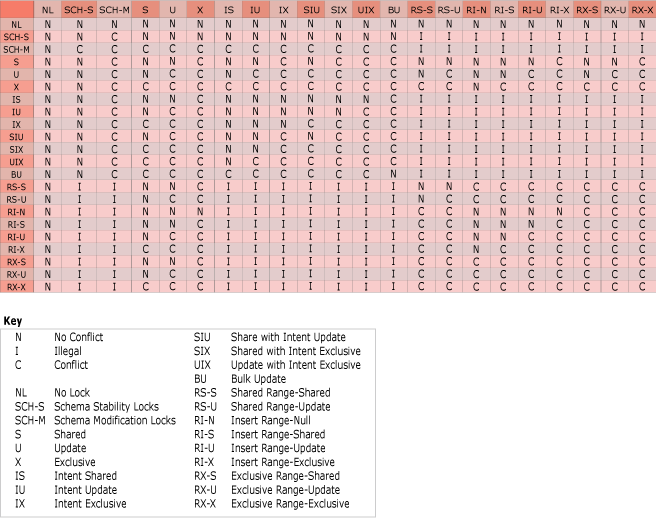
SQL Server maintains SCH-S lock and others as it goes through the process of rebuilding the index and then needs to acquire a SCH-M lock at the end of the operation as the old index is swapped with the new. In our example the online reindex is held up because a SCH-M needs to be converted and Window 1 still holds locks on the table. Since a SCH-M lock is not compatible with any other locks, SQL Server must enter the normal lock queue and wait its turn. At this point DML operations which need access to the randomdata table start to back up in the lock queue. Window 2 has been granted a number of SCH-M locks and anything that follows will need to wait for Window 2 to proceed. A copy of the lock compatibility matrix is shown below from Microsoft’s website.
Window 1 is running with a hold lock. Window 2 has proceeded and acquired a number of SCH-M locks at the end of the online reindex and cannot proceed with its final SCH-M lock until Window 1 commits. Now let’s start Window 3 again. We see that Window 3 starts, but unlike previously, it is seen as executing in SQL Server Management Studio, but at this point has not retrieved any data. When we run an sp_who2 with the SPID for Window 3 we observe that it is blocked by the Window 2 SPID. In our example SPID 57 is blocked by SPID 52 --the online reindex.
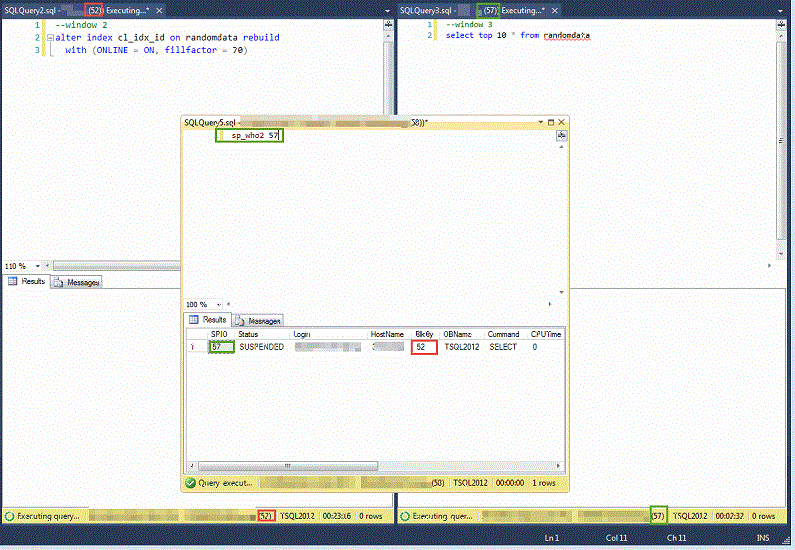
Before running a commit on Window 1 make sure all the result panes are visible. Run the commit statement on Window 1 and the other two scripts will proceed and finish probably before your eyes can pick up on which finishes first. The reason is that the online reindex has already made a copy of the index, but was waiting to make the logical switch to the new index with its final SCH-M lock and then release the table. Even though we were rebuilding a large index it had already done most of the work. The final step takes place in milliseconds.
Using Managed Lock Priority in SQL Server 2014 Enterprise Edition
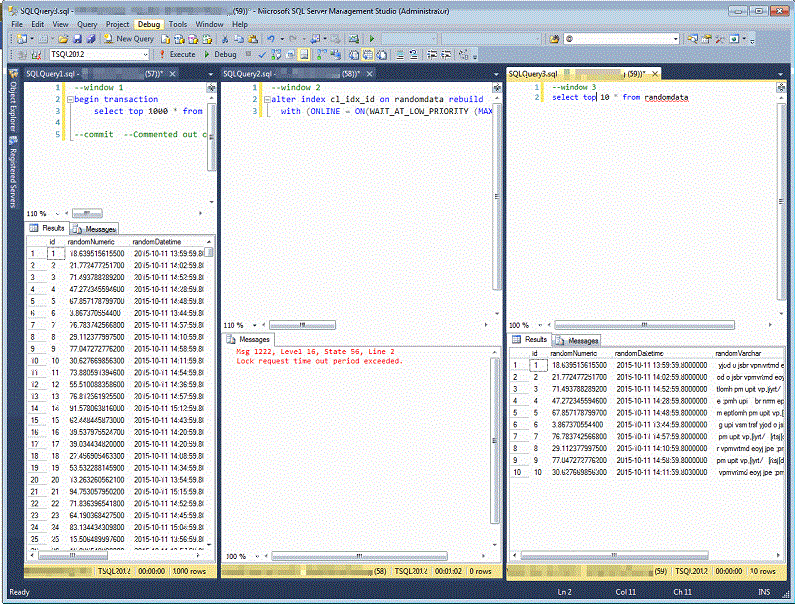
Now that we’ve seen what happens without the managed lock priority enhancement in SQL Server 2014 let’s take a look at the online reindex using the new managed lock priority. Add the following script to Window 2 replacing the previous example.
alter index cl_idx_id on randomdata rebuild with (ONLINE = ON(WAIT_AT_LOW_PRIORITY (MAX_DURATION = 1 MINUTES , ABORT_AFTER_WAIT = SELF )), fillfactor = 80)
This script introduces the new rebuild options available with Enterprise Edition. These options are:
- WAIT_AT_LOW_PRIORITY --The online reindex will wait at a lower priority than other lock requests
- MAX_DURATION --Amount of time to wait expressed in minutes. In my testing running at zero minutes introduces unexpected behavior which I'll mention at the end of this tip.
The declaration ABORT_AFTER_WAIT determines what action to take after the MAX_DURATION is met. The following table outlines the expected behavior.
| ABORT_AFTER_WAIT Options | Results |
|---|---|
| None | Follow the old behavior and enter the lock queue |
| Self | Abort the online reindex process |
| Blockers | Kill the blocking spid and proceed with the online reindex |
When the scripts are run again in the order, Window 1, Window 2, Window 3 we see a different behavior than previously. With the new lock priority set on Window 2 we find that Window 3 is no longer held up by Window 2. Window 2 was running at a lower lock priority and SQL Server detected this and Window 3 proceeded past that request and was able to complete. The second thing to note is that after a one minute wait Window 2 errors out with a message like the one below.
Now edit the script in Window 2 to force blockers to be killed.
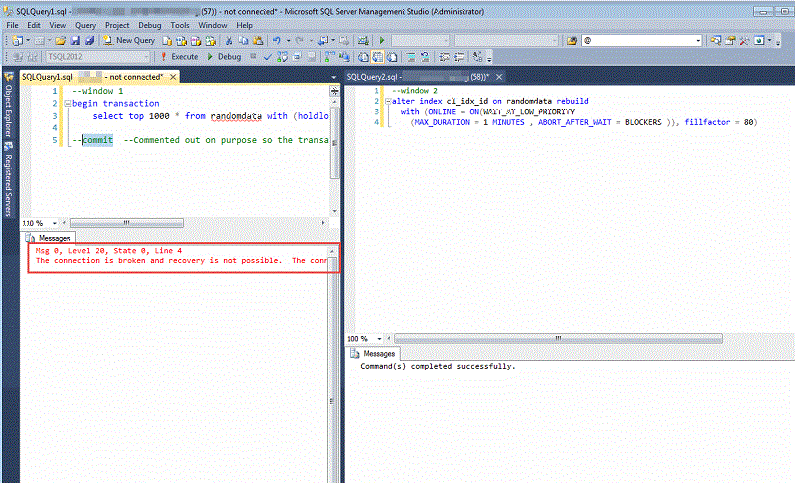
alter index cl_idx_id on randomdata rebuild with (ONLINE = ON(WAIT_AT_LOW_PRIORITY (MAX_DURATION = 1 MINUTES , ABORT_AFTER_WAIT = BLOCKERS )), fillfactor = 80)
Run Window 1 and Window 2 again. After 1 minute you'll see that Window 2 proceeds successfully. Go back to Window 1 and try to run the commit statement. You'll receive a message that the connection is broken and cannot proceed.
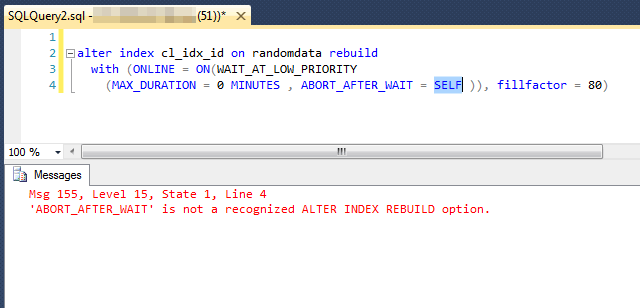
Zero Minutes
I mentioned earlier that setting the MAX_DURATION to 0 minutes introduced unexpected behavior in my testing. Specifically, when I've run tests with MAX_DURATION set to 0 minutes and ABORT_AFTER_WAIT set to 'SELF' I receive an error message like the one below. I have not been able to determine if this is by design or a flaw, but thought it worth noting in this tip.
Summary
For highly transactional systems Managed Lock Priority is an important advance for SQL Server. When used the option allows other locks to proceed past it because it waits at a lower priority. When the MAX_DURATION is reached SQL Server can be told how to proceed by killing blocking spids, aborting, or jumping into the normal lock queue. When an appropriate MAX_DURATION value is set the online reindex process now offers a maintenance task with much less risk for blocking other processes than what was previously possible. This feature is only available with Enterprise Edition of SQL Server 2014 and is in the release notes for SQL Server 2016.
Next Steps
- Review the official Microsoft blog for further information here.
- Review this MSSQLTips on Index rebuilds written by Ben Snaidero
- Test online index rebuilds in your own environment
- Check out all of the SQL Server index maintenance tips on MSSQLTips.com.






About the author
 Burt King is Senior Database Administrator at enservio with more than 15 years experience with SQL Server and has contributed to MSSQLTips.com since 2011.
Burt King is Senior Database Administrator at enservio with more than 15 years experience with SQL Server and has contributed to MSSQLTips.com since 2011.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
