Problem
This is the third and final part of our ongoing series on SQL Server Database Change Management with Liquibase. In the last two posts (tip 1 and tip 2) we saw how to install and configure Liquibase and rolled out a few database changes with it. We also learned how Liquibase can conditionally apply database changes and how to rollback those changes. Although our examples have been around SQL Server, the concepts remain the same for any supported database platform.
Solution
In this tip, we will talk about some use cases for SQL Server Database Change Management with Liquibase.
Documenting Database Changes
Browsing through the DATABASECHANGELOG table is one way of looking at your database change history. Another method is to run the dbDoc command. With dbDoc, Liquibase will look through the DATABASECHANGELOG table and changelog file and generate a JavaDoc style html document. This file will show when each database component was created or changed, what changes were made to those components and who made those changes.
In the code sample below, we are running the dbDoc against our liquibase_test database. Note how we have to specify the original changelog file and the path where the document has to be created:
liquibase --driver=com.microsoft.sqlserver.jdbc.SQLServerDriver --classpath="..\\Program Files\\Microsoft JDBC Driver 4.0 for SQL Server\\sqljdbc_4.0\\enu\\sqljdbc4.jar" --url="jdbc:sqlserver://<SQL Server name or IP>:1433;databaseName=liquibase_test;integratedSecurity=false"; --changeLogFile="D:\\Liquibase\\databaseChangeLog\\dbchangelog.xml" --username=liquibase --password=liquibase dbDoc D:\\Liquibase\\dbDoc
If we browse to the target directory, we will see a number of files:

Opening the index.html file in a browser will load the whole documentation. In the image below, we are looking at the history of changes made to the customer table. We can see there are two pending changes here. Note the left side of the page is a navigation pane with links to different objects from the database:

Liquibase and Version Control
For a database under development, the changelog file can change frequently. It thus makes sense to save the changelog in a version control system like Git, TFS or Subversion. Basically you treat the changelog file like any other application source code. With a version control system, you can track what changes were made to the changelog file over time. Note that we are tracking the file’s changes here, not the database’s changes. The file may have been changed a few times over the last few check-ins, but none of those changes may have been applied to the database. Where the database currently stands can be seen from the DATABASECHANGELOG table.
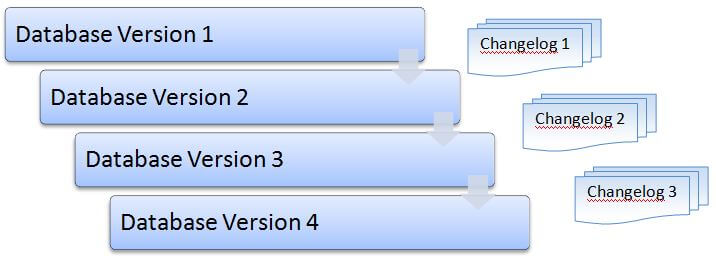
So how does Liquibase integrate database changes from a version control system? If you are considering a linear process where there are no code branches for the changelog file, it’ fairly simple. In the following image, we are seeing a database starting with version 1. Database changelog version 1 upgrades the database to version 2, database changelog version 2 upgrades it to version 3 and so on. This works well when there is only one branch for the code (master branch) and developers are working on its features in a linear fashion. That is, developer A develops database changelog version 1, checks it into the version control system (VCS) and applies to the database, then developer B develops changelog version 2 and applies and so on.
In practice though, the picture will be more like this:
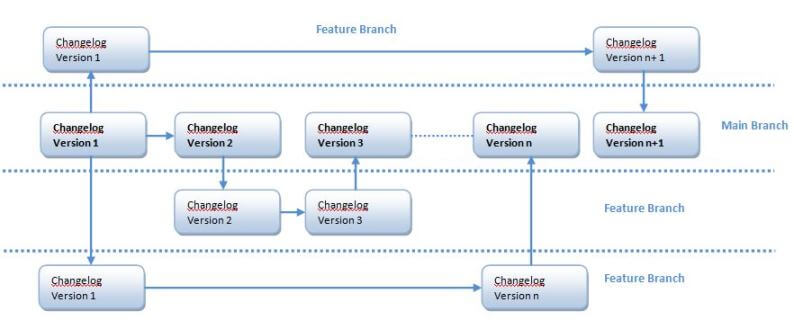
Here, we have a number of “feature branches” sprouting from the master branch. Each of these features branches start with a copy of the changelog from the master branch. These branches live inside the developers’ workstations as they work on the changelog file. When the changelog is ready to be integrated into the master branch, the local feature branch is “pushed” to the remote version control system server. From there, the master branch can “pull” the changes in. In other words, the changes in the feature branch are now part of the original changelog.
When complex databases are being developed, there can be any number of feature branches in flight at any time. Possibly none of those branches would be merged back at the same time. Developers A, B and C could be working on version 2.5 of the changelog and developers D, E and F could be working on version 4.
When it’s time to run the merged code from the master branch, how does Liquibase know the merged changesets from different branches will not conflict with one another when they try to modify the same object?
Again, the answer lies in the way Liquibase checks changesets for uniqueness. Each changeset has an author and id attribute and each changelog file has a name and path. Together, these three items make a changeset unique. When it comes to execution, Liquibase runs the changesets from the master branch, and for each changeset merged into the master branch, it compares that against what’s stored in the DATABASECHANGELOG table. If the changeset has not been applied, Liquibase will apply it.
Automating Liquibase Runs
So far we have been running Liquibase from the command the prompt only. In the first part of this series, we had added the Liquibase directory to our PATH environment variable. If that has not been set up, Liquibase can be called from a java command with the -jar option. Since Liquibase itself is contained within a .jar file, the command will be like this:
java -jar path-to-liquibase-directory\liquibase.jar <options> <command><command parameters>
Again, this is a manual process. The command prompt invocation can be somewhat automated by:
- Creating a .bat, .cmd or PowerShell script that runs Liquibase with the correct parameters and options
- Calling the script file either on-demand or from a scheduled SQL Server Agent Job.
Since Liquibase is available for both Windows and *nix operating systems, same principles apply for Linux and Mac OS X; we can create shell scripts that call Liquibase and use that shell script from cron jobs.
Tools like Maven or Ant can also be used to automate Liquibase runs. We won’t go into the details here.
Most IT shops with a DevOps workflow would perhaps want to invoke Liquibase from a Continuous Integration (CI) server as part of a nightly build process. In this scenario, Developers would work on the database changelog during the day and check it in to the version control system (VCS) once they are happy. During nightly builds, the CI server would invoke Liquibase which will apply the latest database changes from the master branch to a target environment. Application code can then be deployed in the same environment and a set of basic integration tests can be performed.
Popular CI servers include Atlassian Bamboo or Jenkins (free). Other tools are available from IBM, Microsoft or CA. Although Liquibase has an active community and there is a Jenkins plugin available for Liquibase, it’s far better when you consider Datical DB, Liquibase’s commercial version. With Datical DB, you get commercially supported plugins like DaticalDB4Jenkins or DaticalDB4Bamboo.
Keeping Changelog Files in Order
As the database goes through its lifecycle, more and more changesets will be added to the changelog file. When you write your changelogs in XML, even simple changes can take multiple lines. With all the changes being heaped into one file, eventually the file becomes unmanageable. It can take longer and longer to load it in editor, it can seem so complex that you would not know if your changes are going to break anything. Moreover, every time Liquibase runs the changelog, it has to work on every changeset from the beginning: something that will take longer and longer.
Fortunately, just like code refactoring, Liquibase changelogs can be refactored in a hierarchical fashion. That means we can have a single “master” changelog file which can include pointers to a number of “child” changelog files, which in turn can point to more changelog files and so on. With this approach, changelog files can have a relationship like this:
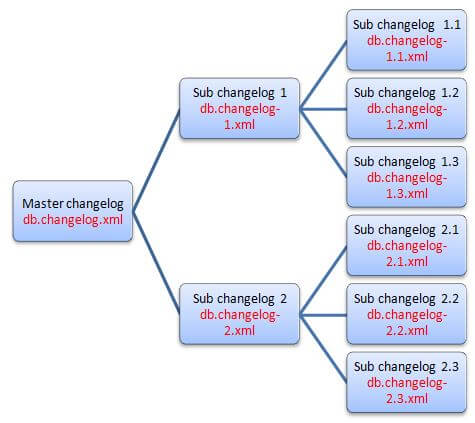
As an example, the following code block shows how we have refactored the original changelog file for our liquibase_test database (you can go through the previous two posts for reference). As you can see, we have included reference to three different XML files and one SQL file here. Each file is a changelog that takes care of a discreet change. When Liquibase starts running this changelog, it runs each included changelog in order.
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog xmlns_xsi="http://www.w3.org/2001/XMLSchema-instance" xsi_schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.1.xsd"> <preConditions onFail="HALT" onFailMessage="This changelog needs to run under the liquibase user account"> <runningAs username="liquibase"/> </preConditions> <include file="create_table_customer.xml"/> <include file="create_table_products.xml"/> <include file="create_table_orders.xml"/> <include file="dbchangelog_sp.sql"/> </databaseChangeLog>
If we want to make further changes to the database, we can create another changelog file and include its reference to the master changelog file.
Liquibase Directory Structure
Related to keeping changelogs in order, there is the question of arranging changelogs in the file system. This is a question often asked by developers and project teams when they first start using Liquibase. The official website shows a sample directory structure. In our opinion, it’s best to create a directory for each database release. The master directory will have the “root” changelog file which will include references to other changelog files in these release-specific subdirectories. Those subdirectories will contain “child” changelog files pointing to other component specific changelog files in other subdirectories. The image below shows the directory hierarchy.
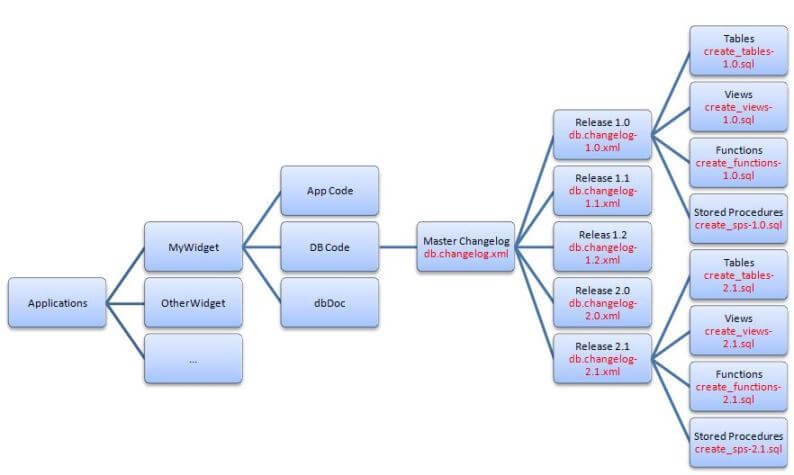
Using this directory structure provides flexibility. When a new release is created, a new directory is created for it. Under this directory, component specific directories are created for tables, views, stored procedures, functions and so on. Each of these component subdirectories will contain a changelog file for implementing the components for the release. A changelog file is created under the release directory which will include references to the component changelogs. Finally, the reference to this release changelog is added to the master changelog.
Some Best Practices
The official Liquibase site lists a number of best practices. We won’t rehash them here; instead, we will list some of the things to make your life as a DBA or developer easier.
- When using Liquibase to manage database changes, don’t use any other tools, methods or processes. Liquibase cannot track changes that it did not make. From the first day of adopting Liquibase, make it the tool of choice.
- Make use of contexts, pre-conditions and rollbacks. This can ensure you are not running changes meant for DEV in QA or PROD.
- Use a consistent directory structure for storing changelogs. This applies for both developer workstations and the version control system.
- Don’t use a generic author name like “Dev Team” for all your changes. Developers should be encouraged to use their own names in a consistent fashion. For example, if Jane Doe is using her author name as “jane_doe”, it should be used as “jane_doe” for all her changes, not “JANE DOE”.
- Encourage developers to use comments in their changelogs.
- Although changeset ids can be any combination of letters and numbers, try to keep them in easy-to-read format. If you don’t want to use simple sequential values like 1,2 or 3, that’s fine, use something that can be eyeballed easily. Using a long hexadecimal string may ensure uniqueness, but it may not be easily readable. Again, use a consistent approach for all changelogs.
- If you are a DBA, generate dbDocs often and see how your database changes are looking. Are there any failed runs? Are there too many rollbacks or too many pending changes?
- Use a logLevel of INFO for each Liquibase run. This would ensure you can capture Java exceptions whenever there is an error.
- Try to incorporate Liquibase into your Continuous Integration workflow.
Limitations
There are some limitations to consider when using Liquibase with SQL Server databases:
- It can roll out stored procedures, functions or triggers, but it cannot generate them from an existing database with the generateChangeLog command.
- We have not tested Liquibase with advanced SQL Server features like partitions, XML data type, database triggers or full text indexes. They may not be supported.
- It cannot be used to reverse engineer or roll out SQL Server database user accounts, role memberships or permissions.
- It cannot be used to reverse engineer or roll out SQL Server database properties like partial containment, mirroring, replication, AlwaysOn or recovery modes.
However, if you think about it, Liquibase was designed with the developer in mind, not the operational DBA. It excels when it comes to creating and maintaining database schema structures, not vendor specific configuration parameters.
Conclusion
By now you should have a fairly good idea about how Liquibase can help manage your database changes. The product is free and available for multiple operating systems, so there is really nothing stopping you from taking it for a test drive. As in the case of most new products, you are better off starting small. In fact if you are working with microservice architecture, it may just be the thing to test Liquibase with.
Microservice architecture is a software development model where a large application is made up of small, independent components with each component performing a specific task. The components are independent in the sense that they can be deployed separately without affecting any other part of the application. For example, a web site can have one component taking care of user registration while another component can take care of password reset requests. Components communicate with each other through defined interfaces for delivering the overall functionality. And being independent, each component may use completely separate database or schema.
Microservice architecture fits neatly with the agile development practice where small changes are iteratively applied to an application. Since each component is small and lightweight, their database requirements are usually small as well. For example, a component may need to access only five tables in a database to store application session data. Managing a small database’s frequent changes thus becomes extremely easy with Liquibase.
Having said that, there is nothing stopping you from testing Liquibase with large, monolithic database projects.
Next Steps
- Think about small databases in your organization that can benefit from refactoring. Even if their schema remains fairly static, you can generate their structure with Liquibase and save it for future reference.
- Talk with your application architects, software developers and DevOps engineers about existing deployment methods. Try to think how Liquibase can fit in there. You may be surprised to find that they would want to start using Liquibase.
- Once you are comfortable with Liquibase, introduce it to your colleagues and managers. If your role allows you to make decisions, start working on an enterprise-wide adoption.

Sadequl Hussain lives in Sydney, Australia and holds a Bachelor’s degree in Electrical Engineering. His more than 15 years’ experience in IT has seen him in various roles including training, technical writing, web application development and database administration. Sadequl has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical database systems for various large companies. He is also an Oracle DBA and an avid Linux administrator. Over the years Sadequl has achieved various certifications including those from Microsoft, CompTIA and ITIL. He is currently having fun preparing for other ones from Amazon and the Open Group. He regularly contributes to various SQL Server and Linux online publications. Apart from spending time with his wife and daughter, he loves his part-time career as a photographer and film-maker and also loves to travel.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2017


