Problem
We have upgraded our SQL Server 2008 R2 to SQL Server 2014. We have some big partitioned tables (with 1+ billion rows), and each time we do a statistics update with fullscan, it will take a 3+ hours, so we want to take advantage of the incremental statistics update feature of SQL Server 2014 because most of our data changes occur in one or two of our newest partitions, where should we start and how can build a robust/efficient incremental statistics update procedure?
Solution
Incremental statistics update at partition level is a new feature introduced in SQL Server 2014. In this tip, we will go through a complete process to set up an incremental statistics update procedure. The solution can be implemented in 3 phases:
- Environment Check and Preparation
- Development and Deployment
- Monitoring and Optimization
We first create a test environment, and then work on each phase. In the script below we create a sample MSSQLTips database with four filegroups, add four transaction log files, create the partition function and scheme, create a partition table, create indexes aligned and not aligned with the partition scheme and populate the table with data.
use master
go
create database MSSQLTips
on primary (name=mssqltips_data, filename='c:\data\mssqltips_data.mdf', size=1mb, filegrowth=1mb)
log on (name=mssqltips_log, filename='c:\data\mssqltips_log.ldf', size=1mb, filegrowth=1mb);
go
alter database MSSQLTips set recovery simple;
go
ALTER DATABASE MSSQLTips add filegroup fg_1;
ALTER DATABASE MSSQLTips add filegroup fg_2;
ALTER DATABASE MSSQLTips add filegroup fg_3;
ALTER DATABASE MSSQLTips add filegroup fg_4;
go
alter database MSSQLTips add file (name=mssqltips_data_1, filename='c:\data\mssqltips_data_1.ldf', size=1mb, filegrowth=1mb) to filegroup fg_1;
alter database MSSQLTips add file (name=mssqltips_data_2, filename='c:\data\mssqltips_data_2.ldf', size=1mb, filegrowth=1mb) to filegroup fg_2;
alter database MSSQLTips add file (name=mssqltips_data_3, filename='c:\data\mssqltips_data_3.ldf', size=1mb, filegrowth=1mb) to filegroup fg_3;
alter database MSSQLTips add file (name=mssqltips_data_4, filename='c:\data\mssqltips_data_4.ldf', size=1mb, filegrowth=1mb) to filegroup fg_4;
go
use MSSQLTips
-- create partition function and partition scheme
create partition function pf_mssqltips ([int]) as range left for values (10000, 50000, 90000);
create partition scheme ps_mssqltips as partition pf_mssqltips to (fg_1, fg_2, fg_3, fg_4);
go
USE MSSQLTips;
-- create a partitioned table
if object_id('dbo.Record', 'U') is not null
drop table dbo.Record
create table dbo.Record (id int not null, [name] varchar(100), x int);
go
-- this index is NOT aligned with partition scheme
create index idx_record_name on dbo.Record ([name],x);
-- this index is NOT aligned with partition scheme
create index idx_record_x on dbo.Record (x)
-- this PK / index is aligned with partition scheme
alter table dbo.Record add constraint pk_record primary key (id) on ps_mssqltips(id);
go
USE MSSQLTips;
-- populate the table
truncate table dbo.Record;
set nocount on;
declare @id int = 0
begin tran
while @id < 150000
begin
set @id +=1;
if (@id % 30000 = 0)
begin
commit tran;
begin tran;
end
begin try
insert into dbo.Record (id, [name],x) values
(cast(ceiling(rand()*100000000) as int) % case @id%10
when 1 then 10000
when 2 then 10000
when 3 then 10000
when 4 then 10000
when 5 then 40000
when 6 then 50000
when 7 then 100000
when 8 then 100000
when 9 then 100000
when 0 then 1000000
end
, substring(convert(varchar(300),NEWID()),1, cast(ceiling(rand()*300)/15 as int) + 2)
, ceiling(rand()*123456));
end try
begin catch
if (@@error = 2627) -- duplicate key error
continue;
end catch
Now we will follow the phases outlined above to build the solution.
Phase 1 - Environment Check and Preparation
In this phase, we try to address the following questions:
- Does the database allow auto incremental statistics update?
- On partitioned tables, are there any indexes that are not aligned with partition scheme?
- On partitioned tables, are aligned indexes enabled for incremental statistics update?
For the 1st question, by default, each database has its AUTO_CREATE_STATISTICS setting turned on, but without incremental update. To check and fix such issue, we use the following script:
select name, is_auto_create_stats_on, is_auto_create_stats_incremental_on
, fix_sql= CASE is_auto_create_stats_incremental_on
WHEN 0 THEN 'ALTER DATABASE ' + name +
' SET AUTO_CREATE_STATISTICS ON (INCREMENTAL = ON)'
ELSE '-- no fix needed'
END
from sys.databases
where name='mssqltips'; -- omitting if you try to fix all dbs without incremental stats update on
In my case, I get the following:
I then just copy the column [fix_sql] and run it in an SSMS window to fix the database setting.
For the 2nd question, sometimes, for whatever reason, we may find some indexes are not aligned with partition schemes. According to MSDN, an aligned index is “An index that is built on the same partition scheme as its corresponding table”.
To find out such un-aligned indexes and generate a fixed script, we can use the following code.
use MSSQLTips
-- find indexes that are not aligned with partitions
; with c as ( -- the CTE is to find any table that has index partition aligned
select t.object_id as [table_objid], p.name
from sys.indexes i
inner join sys.tables t
on i.object_id = t.object_id
and i.index_id > 0
inner join sys.partition_schemes p
on p.data_space_id = i.data_space_id
)
select distinct [Table]=schema_name(t.schema_id)+'.'+t.name, [NotAligned_Index]=i.name
, fix_sql= 'drop index ' + i.name + ' on ' + schema_name(t.schema_id) +'.' + t.name +';' +
'create index ' + i.name + ' on ' + schema_name(t.schema_id) +'.' + t.name +
' (' +substring(x.n, 2, len(x.n)) +') on ' + c.name + quotename(ps.n, '()')
from sys.indexes i
inner join sys.tables t on i.object_id = t.object_id
inner join c on c.[table_objid]= t.object_id
inner join sys.index_columns ic on ic.object_id = i.object_id
and i.index_id = ic.index_id
inner join sys.columns col on col.object_id = ic.object_id
and col.column_id = ic.column_id
left join sys.partition_schemes p on p.data_space_id = i.data_space_id
cross apply (select ','+sc.name
from sys.columns sc
inner join sys.index_columns ic2
on ic2.object_id = sc.object_id
and ic2.column_id = sc.column_id
where sc.object_id = t.object_id and ic2.index_id = i.index_id
order by ic2.index_column_id
for xml path('')) X(n)
cross apply (select distinct c2.name
from sys.index_columns ic2 inner join sys.columns c2
on ic2.object_id = c2.object_id and ic2.column_id = c2.column_id
and ic2.object_id = t.object_id
where ic2.partition_ordinal = 1) PS(n)
where p.data_space_id is null;
The result will be:

We can copy the [Fix_SQL] column and run the script under the target database [MSSQLTips] to fix the unaligned indexes.
For the 3rd question, we can check the index statistics update property via the following script:
USE mssqltips
-- find indexes that did not turn on incremental statistics update
SELECT [Table]= OBJECT_SCHEMA_NAME(i.object_id)+'.'+ OBJECT_NAME(i.OBJECT_ID)
, s.name, s.is_incremental
, Fix_SQL = 'alter index ' + quotename(s.name, '[]') +
' on [' + OBJECT_SCHEMA_NAME(i.object_id) + '].[' + object_name(i.object_id) +
'] rebuild with (STATISTICS_INCREMENTAL = ON)'
from sys.stats s
inner join sys.indexes i on i.name = s.name
and i.object_id = s.object_id
inner join sys.partition_schemes p on i.data_space_id = p.data_space_id
where is_incremental = 0;
In this case, the result is:

Phase 2 - Development and Deployment
Our development requirement is to have a script that can scan a database and find any partitioned tables that need incremental statistics updated. This is actually an on-demand statistics update. So how do we know which partitions need to be updated? In short, we can use a new DMV sys.dm_db_incremental_stats_properties that has been available since SQL Server 2014 SP2 or 2016 SP1.
So let’s first look at the example, after I do a statistics update on a table with fullscan, then check the DMV:
USE MSSQLTips;
-- update table stats with full stats
update statistics dbo.Record with fullscan;
-- after fullscan stats update, the [modification_counter] will be reset to 0
-- for each stats of indexes
select dm.stats_id, dm.partition_number, last_updated, rows, modification_counter
from sys.indexes i
cross apply sys.dm_db_incremental_stats_properties(object_id('dbo.record'),i.index_id) DM
where i.object_id = object_id('dbo.record')
Figure 1 - DML Check Script
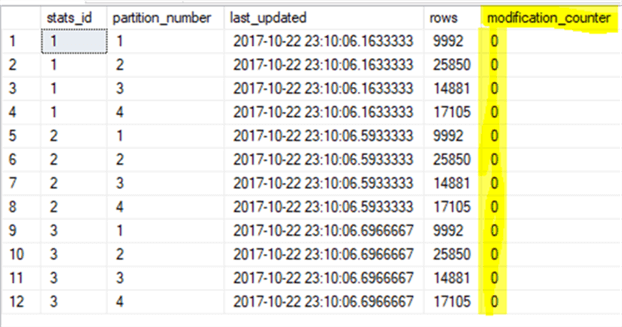
Now let’s issue a few DML statements on this table and after each DML execution, we will run the DMV check script (Figure -1) above.
-- 1 delete one record on partition 1,
delete top (1) from dbo.record
where id < 10000
After running the DMV check script in Figure 1, we will get:

Notice that each index (i.e. stats_id =1,2,3) on partition 1 has its [modification_counter] changed by 1 just as expected.
Now we will make some DML operations on partition 2:
-- 2 two inserts on partition 2,
declare @t table (id int )
insert into @t (id)
select top (40000) rn = 10000 + row_number() over (order by s.number) -1
from master..spt_values s
cross join master..spt_values t;
-- delete from @t where id exists in dbo.record
delete from @t
from @t t
inner join dbo.record r
on r.id = t.id
-- any id value in @t does not exist in dbo.record
-- so we can pick up any two id values and insert into dbo.record
insert into dbo.record (id, name, x)
select top 2 id, 'hello world ' + cast(id as varchar(10)), rand(id)*30000
from @t
After running the Figure 1 check, we get the following:

Again, it is exactly what we expect.
Now we will run DML statements on partition 3:
-- 3. three updates on [name] column on partition 3
update top (3) t set [name]='hello'+cast(id as varchar)
from dbo.record t
where id > 50001

Note in this case, we only update column [name], which is included in index [idx_record_name], that’s why we only see [modification_counter] gets updated to 3 at row stats_id = 2
Finally, we will do an insert/delete/update on partition 4 (note for the update, we will update column [x] only). Before we really do any work, we can calculate that for partition 4, an insert plus a delete will cause [modification_counter] to be 2 for all stats_id, and an update on column [x] will cause stats_id=3 to have its [modification_counter] change from 2 to 3.
Ok, we will run the following DML statements and then the code from Figure 1 to check whether the result is the same as we expect.
-- 4. One insert + one delete + one update on [X] column on partition 4
-- insert
insert into dbo.record (id, name, x)
select max(id)+1, 'test only', 1111.111
from dbo.record
-- delete
delete top (1) from dbo.record
where id > 90001 -- partition 4
-- update
update top (1) t set x=x+1
from dbo.record t
where id > 90001 -- partition 4;
(1 row affected)
(1 row affected)
(1 row affected)
Now running Figure 1 code, we get the following:

The result is exactly what we expected before.
OK, so with all these examples, we can easily come up with a rule for on-demand statistics update. For example, my rule is:
- If [modification_counter]/[rows] > N%, we will do the stats update on that specific partition. Here [N] can be defined as you need, such as 10, i.e. once modified rows reach 10% of the total rows in that partition, I will do the stats update on that partition.
- For big tables, i.e. each partition may have millions of rows, I can also add another rule, such as when [modification_counter] goes beyond 2000, I will do the statistics update as well.
With such rule in mind, I can quickly come up with a script to do the on-demand statistics update.
-- on-demand stats update
USE MSSQLTips
declare @debug bit=1 -- 1=print out cmd; 0=execute
declare @N int = 10 -- 10 percent, change to your own need
declare @tbl varchar(300),@idx varchar(128), @pnum int;
declare @crlf char(2)=char(0x0d)+char(0x0a), @sqlcmd varchar(max)='';
declare @cur cursor;
set @cur = cursor for
select [tbl]=quotename(object_schema_name(i.object_id), '[]') + '.' + quotename(object_name(i.object_id), '[]')
, i.name, dm.partition_number --, last_updated, rows, modification_counter --, floor([rows]*1100.0)
from sys.indexes i
inner join (select p.object_id, p.index_id from sys.indexes i
inner join sys.partitions p
on p.object_id = i.object_id
and p.index_id = i.index_id
group by p.object_id, p.index_id having count(*) > 1) TBL
on i.object_id = tbl.object_id
and i.index_id = tbl.index_id
cross apply sys.dm_db_incremental_stats_properties(TBL.object_id,i.index_id) DM
where modification_counter >= floor(@N/100.0 * [rows])
and [rows] > 0;
open @cur;
fetch next from @cur into @tbl, @idx, @pnum;
while @@FETCH_STATUS = 0
begin
select @sqlcmd = @sqlcmd + 'update statistics ' + @tbl + ' ' + @idx
+ ' with resample on partitions ('
+ cast(@pnum as varchar(10)) +');'+ @crlf;
fetch next from @cur into @tbl, @idx, @pnum;
end
set @sqlcmd = 'use [' + db_name() + '];' + @crlf + @sqlcmd;
if @debug = 1
print @sqlcmd;
else
exec (@sqlcmd)
go
Figure 2 – On-demand SQL Server statistics update
Now let’s do some updates to make enough changes on some of the partitions.
-- update around 30% of change on partition 1 for idx_record_name (index_id = 2)
update top (3000) t set x=x+1, name=name+'_1'
from dbo.record t
where id < 10000
-- update about 77% change on partition 2, which has about 25850 rows in my environment
update top (20000) t set x=x+1, name=name+'_2'
from dbo.record t
where id >= 10000 and id < 50000
After the update, if we run the check script in Figure 1, we can see the following result:
![Stats values after DMLs - Description: We can see [modification_counter] changed after DMLs](/wp-content/images-tips/5170_incremental-sql-server-statistics-update.009.png)
If we run code in Figure 2 (with @debug=1), we will get the following:
use [MSSQLTips];
update statistics [dbo].[Record] idx_record_name with resample on partitions (1);
update statistics [dbo].[Record] idx_record_name with resample on partitions (2);
update statistics [dbo].[Record] idx_record_x with resample on partitions (1);
update statistics [dbo].[Record] idx_record_x with resample on partitions (2);
This is exactly what we need. If I set @debug=0 in Figure 2, and run the code, then all those stats which meet the update threshold will be updated. We can verify this by running the Figure 1 script. The result is:

To deploy the on-demand stats update, we can wrap up the code in Figure 2 in a job, or better, embedded the code in a PowerShell function, and then run against any target database via function parameters.
Phase 3 - Monitoring and Optimization
After deployment, we need to monitor the impacts of the statistics update. Major checks include time duration, I/O activity and any potential negative impacts on workload performance. We may adjust update threshold (i.e. the % change of rows) to ensure an optimized stats update workload and frequency. This post-deployment monitoring is very important for large partitioned tables.
For code in Figure 2, we may further modify it to include system generated stats (i.e. names like _WA_sys_xxxx) by replacing sys.indexes with sys.stats. We may even add other criteria for when to perform statistics update, such as if [last_updated] is more than 7 days ago and [modification_counter] >= 100, etc.
Summary
A robust on-demand incremental statistics update process on partitioned tables will boost performance stability, reduce resource consumption (I/O and CPU) and significantly shrink the maintenance window for very large tables.
In this tip, I have demonstrated how to implement an on-demand statistics update procedure, and the catch here is this procedure is only applicable to SQL Server 2014 Enterprise SP2 and SQL Server 2016 Standard/Enterprise SP1.
Next Steps
The following articles are a good read related to incremental statistics update on partitioned tables.
- SQL Server 2014 Incremental Update Statistics Per Partition
- Introducing SQL Server Incremental Statistics for Partitioned Tables
- Incremental statistics … How to Update Statistics on 100TB Database
- UPDATE STATISTICS (Transact-SQL)
- Improving Partition Maintenance with Incremental Statistics

Jeffrey Yao is a senior SQL Server consultant with 15 years of database administration, his current interests are on database administration automation and visualization. He enjoys reading the concise and smart sql tips and loves R&D work in DBA Engineering topics. His blog is at: http://www.sqlservercentral.com/blogs/jeffrey_yao/.


