Problem
I have a large SQL Server Analysis Services Tabular model. Some of the tables have many columns and millions of rows. When the model is being processed, all the memory of the server is consumed. Is there a way to reduce the size of the model so I can keep the entire model in memory?
Solution
SQL Server Analysis Services (SSAS) Tabular is a memory-intensive product, as it stores all of the data in the RAM of the machine. This means all data is compressed using the columnstore technology and then loaded into memory. Due to the compression, the size of the data is typically much smaller in memory than it is on disk. However, models can grow too large to fit into memory.
There are a couple of solutions for this problem:
- The most obvious is to put more RAM memory into the server. This is however not always possible. For example, you can use SSAS Tabular in Standard Edition since SQL Server 2016 SP1, but there’s a limit to how much RAM the instance can use. With the release of SQL Server 2017 the maximum is currently set at 16GB of RAM. You can find more information at Editions and supported features of SQL Server 2017.
- For very large models (in the Terabyte range or bigger) it’s more feasible to use DirectQuery instead of in-memory. In this configuration, the data is kept at the source and there’s only a semantic layer build in the Tabular model. DAX queries are translated to native queries of the source system. This means no memory consumption to store the data, but possibly slower performance.
- The last option - which we will describe in this tip - is to use some techniques to reduce the size of the model. If the model is smaller, more data can be put in memory.
Keep in mind, processing a Tabular model can be very memory intensive. The new data has to be loaded into memory - uncompressed while it is being encoded - and the old data might be kept around as well for transaction purposes. If you have multiple tables being processed at once, a lot of data is being put into RAM. You can avoid this by having a different processing strategy than just doing a Process Full. You can for example do a Process Clear first to remove existing data out of memory and then a Process Default to process the model again. You can use combine this with the techniques described in this tip to further trim down on your memory usage.
In the first part of the tip, we’ll set up a Tabular model we can use for testing and explain how you can find the size of the various columns in a Tabular model.
Test Set-up
We’re going to use the StackOverflow sample database, as it has a large number of rows in the Posts table (about 32 million rows). On my machine, I removed some blob columns to save space and I put a clustered columnstore index on the table. The following query will be used to extract the data from the database:
SELECT TOP 15000000 -- 15M rows
[Id]
,[AcceptedAnswerId]
,[AnswerCount]
,[ClosedDate]
,[CommentCount]
,[CommunityOwnedDate]
,[CreationDate]
,[FavoriteCount]
,[LastActivityDate]
,[LastEditDate]
,[LastEditorDisplayName]
,[LastEditorUserId]
,[OwnerUserId]
,[ParentId]
,[PostTypeId]
,[Score]
,[Tags]
,[Title]
,[ViewCount]
,RandomPercentage = RAND(Id) * 100
,WeirdBusinessKey = CONCAT(Id,CONVERT(DATE,CreationDate,112),OwnerUserId)
FROM [StackOverflow].[dbo].[Posts];
I limited the number of rows to 15 million, because my machine doesn’t have enough RAM to do process the data. You might adjust this number to your environment. As you can see in the query, I added two extra columns to showcase two typical scenarios you might find in a Tabular model:
- A numerical columns using the float data type. Almost every value is unique.
- A string column which is the concatenation of other columns. Typically this is used to create some business key to enforce a type of uniqueness. It could be used for distinct counts or to create multi-column relationships. Since Tabular only supports one-column relationships, you have to concatenate columns together to create multiple-column relationships. Again, almost every value (if not all) is unique.
Both columns will compress very badly and will take up a large portion of the model size. If you are using the 1400 compatibility level for SSAS Tabular 2017, you need to modify the registry so you can use the legacy data sources in Visual Studio. There you can specify SQL statements, while in the modern get-data experience you can only create M queries. The process is described in the article Using Legacy Data Sources in Tabular 1400.

Now we can create a legacy data source in SSAS 2017:

In the wizard, choose Microsoft SQL Server as the data source type, specify the connection information to the StackOverflow database, specify the impersonation information (I choose the service account, which means you need to give the account read permissions on the StackOverflow database) and then choose how you want to import the data:

Here you can use the T-SQL statement we specified earlier:

Click Finish and load the data to the model in Visual Studio.
Retrieving the SSAS Tabular Model Size
Before we start reducing the size of our Tabular model, we first have to figure out how big it is. There are a couple of methods to get the size; some are more accurate than others.
In earlier versions of SSAS Tabular, the easiest method is to right-click on a Tabular database and go to its properties. The following screenshot was taken on a SSAS 2012 model (not the StackOverflow model we are using in this tip) with the version of SSMS shipped with SQL Server 2012:

However, this estimate doesn’t always seem to be accurate. In the latest versions - SSAS 2017 and SSMS 17.3 - this property doesn’t appear anymore in the database properties.
Another option is to go to the data folders and check the size of the model on disk (the model is saved here when it is unloaded from memory). For the StackOverflow database, we find a size of about 2.51GB.
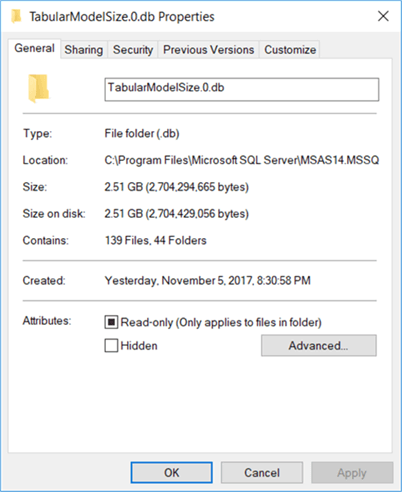
Again, this is a very rough estimate. The last and most accurate method is to use the SSAS data management views (DMVs). Luckily, a free-to-use tool has been built by sqlbi.com: the Vertipaq Analyzer. This tool is an Excel document with a PowerPivot model that connects to an SSAS Tabular model and retrieves all of the information for you. To understand all of its capabilities, please read the article Data Model Size with VertiPaq Analyzer. The VertiPaq Analyzer add an extra tab to the ribbon of the Excel workbook where you can also find more information:

To get the information from your model, you need to go to the PowerPivot model, where you click on Existing Connections in the ribbon.

There you need to modify the connection named SSAS so it points to your SSAS instance and to the model you want to analyze.

Once the connection is modified, you need to refresh the workbook so it can retrieve all the data. You can do this in the PowerPivot model itself, in the Vertipaq Analyzer tab or in the Analyze tab when you have selected a pivot table.
The sheet we’re the most interested is the Columns sheet. Here we can find the following information:
- The number of rows and the cardinality of the column. If every value of the column is unique, the cardinality is the same as the number of rows. The goal of this tip is to get the cardinality is low as possible, because compression will be much more effective.
- The total size of the column, in bytes. This consists of the size of the actual data, the dictionary and the size of the columns hierarchy. There is also a column indicating the relative size of the column compared to the entire model size.
- The encoding and the data type. You can read the tip Improve Analysis Services Tabular 2017 Processing with Encoding Hints to learn more about the encoding of a column and why it’s important.
Analysis of the StackOverflow model gives the following result:

The model takes up 4.5GB of size in memory (which is more than the size on disk). The high cardinality columns take up the most space. Four columns take up 71% of the entire model and we’re going to focus on those columns. Take note there are other high cardinality columns - such the Id column - but since they are value encoded they have a very small dictionary size so they take up less space.
Next Steps
- You can download the latest versions of the Vertipaq Analyzer here. Try it out on your Tabular models to find out how much space they occupy in memory.
- More information about how to enable the legacy data sources (the way data was retrieved in SSAS Tabular 2012/2014) in the article Using Legacy Data Sources in Tabular 1400.
- Stay tuned for part 2 of this tip, where we’ll try to minimize the size of the model as much as possible.
- You can find more Analysis Services tips in this overview.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025