Problem
SQL Server Merge Replication configuration supports Identity Range options using either “Automatic” or “Manual” to manage Auto Incremented values for a column of a table. The problem with this is it gets tricky to make sure the identity values do not collide. In this tip we look at an approach to make sure the identity values are evenly distributed among the Publisher and the Subscriber.
Solution
Microsoft SQL Server generates Auto Incremented numbers for new rows inserted into a table that contain an identity column. To use identity columns in a Merge Replication, the table has to be populated at more than one instance (Publisher and Subscribers) and each instance in the Merge Replication must be initiated with a different range of identity values, so duplicates or violations do not occur. So how to you solve this problem.
Identity Range Management in SQL Server Merge Replication
When adding a new table to Merge Replication, you need to select the Identity Range Management option for synchronization. If any column has an identity property, IDENTITY (1,1), as a PRIMARY KEY for a table then it will create conflicts. So, Merge Replication suggests two options “Automatic” and “Manual”, as shown below to help eliminate this issue.

Automatic
Replication manages the Identity range at the publisher and subscribers with the parameter of Range Threshold Percentage. It specifies the size ranges for the Publisher and Subscribers, and SQL Server manages the assignment of new ranges. The NOT FOR REPLICATION option will be applied on the identity column at the Subscriber and it restricts a new value getting created while synchronizing the row at the destination. In Automatic, replication manages the Identity range at the publisher and subscribers with the parameter of Range Threshold Percentage.
Manual
Users need to configure the Range of Identity for the publisher and each subscriber. As best practice, we manage identity values with a gap of ranges at the subscribers according to the use case.
For example, table user_orders that has a large number of rows and the primary key is an identity column with a BIGINT data type on column order_id. Rows can be inserted at both ends (Publisher and Subscribers). So, the user will reseed the IDENTITY of a table with large gaps at the Subscribers to avoid Primary Key Violation\Conflicts.
We have three subscribers Subscriber – A, Subscriber – B and Subscriber – C and the Identity is reseeded with a range value of 10000000 at all replication subscriber nodes. Accordingly, new records will have a new unique value in the range of the subscribers as shown in the below row structure.
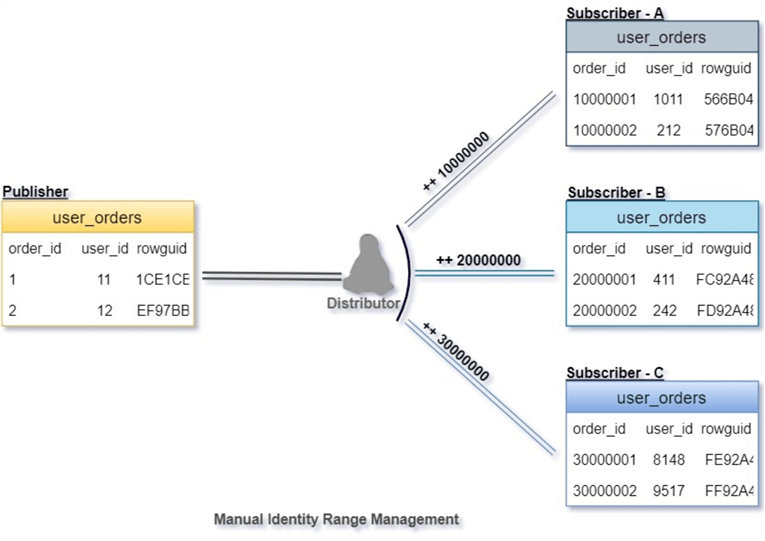
Before applying the Synchronization or Generating the Snapshot, the DBA needs to prepare numbers to track the current range at the publisher and each subscriber. If the current_ident is near to the boundary then the DBA should be alerted to change it or take action.
You need to choose the data type of the identity column carefully because you do not want the subscribers to run out of range values. It works fine as a manual option, but DBAs need to manage, document and monitor these tables. For example, if Subscriber – B has crossed 30000000 then again it causes an issue with Primary Key Violation and needs to be reseeded again, using a value like 40000000 to generate a new range.
This manual Identity Range problem can be resolved with the mathematical formula on the IDENTITY property. However, both options will always have at least one range for the publisher and one range for each subscriber.
Solving the Identity Range Issue for the Publisher and Subscribers
Below shows the syntax for setting up an identity. We will use this solve our problem.
IDENTITY [ (seed , increment) ]
The Seed is the value used for the very first row loaded into the table. The Increment is the incremental value that is added to the identity value as new rows are loaded. If it is IDENTITY (1,1) then rows are loaded in a sequence as 1,2,3…n
In Merge Replication, we can use the IDENTITY (m, n) formula as follows:
- m = Serial number of a node (Publisher = 1, First Subscriber = 2, Second Subscriber = 3, etc.)
- n = Number of replication nodes (Publisher + All Subscribers)
For example, we have 4 nodes (n = 4) for replication (1 Publisher + 3 Subscribers). The Serial number m will be 1 for Publisher and 2, 3, 4 for Subscriber – A, Subscriber – B and Subscriber – C respectively.
According to the formula, the data will be populated as follows:
- Publisher: IDENTITY (1, 4) – the column data sequence will be 1, 5, 9, 13…
- Subscriber – A: IDENTITY (2, 4) – the column data sequence will be 2, 6, 10, 14…
- Subscriber – B: IDENTITY (3, 4) – the column data sequence will be 3, 7, 11, 15…
- Subscriber – C: IDENTITY (4, 4) – the column data sequence will be 4, 8, 12, 16…

As the default nature of Merge Replication, the table will be dropped and recreated at each subscriber with the schema of the publisher while adding a new table in Merge Replication. So, the IDENTITY property will be IDENTITY (1,1) at Publisher and all Subscribers. But we can reseed it using the below commands, once the snapshot is generated and applied to all subscribers.
Subscriber A
DBCC CHECKIDENT('user_details', RESEED, 2);
Subscriber B
DBCC CHECKIDENT('user_details', RESEED, 3);
Subscriber C
DBCC CHECKIDENT('user_details', RESEED, 4);
Now, each time it generates a new number at the different nodes, there is no chance of duplicate values.
In the future, if new subscribers are added to the Merge replication then the IDENTITY property can be changed using the IDENTITY(m,n) formula as mentioned above. Consider the highest SEED value as the maximum current_ident from the Publisher and Subscribers. You can skip a small range and consider a new number while updating the SEED and INCREMENT parameter in the IDENTITY property of the table.
For example
- Publisher: has a current_ident : 945005
- Subscriber – A: has a current_ident : 945006
- Subscriber – B: has a current_ident : 945007
- Subscriber – C: has a current_ident : 945008
Now, new subscriber Subscriber – D is added, so we can skip the identity to 946000 to avoid any duplication issues while applying the new SEED and IDENTITY. So, new configuration for the IDENTITY property can be as follows:
- Publisher: IDENTITY(946001, 5)
- Subscriber – A: IDENTITY(946002, 5)
- Subscriber – B: IDENTITY(946003, 5)
- Subscriber – C: IDENTITY(946004, 5)
- Subscriber – D: IDENTITY(946005, 5)
This solution can help in other use cases as well, where a table is managed by different databases, instances or data center and the identity values need to be unique.
Next Steps
- Check out these other resources:

Jignesh Raiyani is a SQL Server Developer/DBA with experience in design and development of T-SQL procedures and query performance tuning. He loves to resolve and troubleshoot complex issues. He has worked on installation, administration and maintenance of SQL Server.
In your Blogpost you mentioned this:
As the default nature of Merge Replication, the table will be dropped and recreated at each subscriber with the schema of the publisher while adding a new table in Merge Replication. So, the IDENTITY property will be IDENTITY (1,1) at Publisher and all Subscribers. But we can reseed it using the below commands, once the snapshot is generated and applied to all subscribers.
How did you archived the last sentence? “But we can reseed it using the below commands, once the snapshot is generated and applied to all subscribers.”
When I create the subscription from the publication, the snapshot is apllied to the subscribers and I have no chance to manipulate the ids