Problem
In this tip, we’ll take a look at the SUBSTRING function, which is used to extract a string of characters out of a larger string. We’ll cover the syntax of the SQL SUBSTRING function and demonstrate its usage with some examples.
Solution
A common scenario in database development – and in programming in general – is to do text manipulation. One of the more common use cases is when you need to extract a piece of a string. For example, a word out of a sentence, or the filename of an object out of a file path.
Microsoft SQL Server SUBSTRING Syntax
The SUBSTRING function has the following syntax:
SUBSTRING ( expression ,start , length )
For example, SELECT SUBSTRING('Hello World',1,5) will yield the result “Hello”. Keep in mind “start” and “length” can be expressions themselves as well, as long as they return a positive integer, negative integer or a bigint.
- expression – is of the following data types: character (char, varchar, nchar or nvarchar), binary (binary or varbinary), text, ntext or image. If the expression returns NULL, SUBSTRING will also return NULL.
- start – specifies the starting point of the first character you want to return. SQL Server starts counting at 1. So SUBSTRING('MSSQLTips',3,3) returns 'SQL', SUBSTRING('MSSQLTips',6,3) returns 'Tip'. If you have a length below 1, SQL Server will count back although it will not return blanks. SUBSTRING('MSSQLTips',0,5) returns 'MSSQ' (so only 4 characters), while SUBSTRING('MSSQLTips',-4,5) returns the empty string ''. If “start” is bigger than length, the empty string is also returned. SUBSTRING('MSSQLTips',15,5) returns ''. If “start” is NULL, the result is also NULL.
- length – specifies the number of characters you want to return. If (length + start) is longer than the number of characters in “expression”, the entire expression is returned. If the length is NULL, NULL is returned. If the length is negative, an error is returned.

Microsoft SQL Server String Functions
Let’s suppose you want to select a substring from the start of the expression, or from the end. From the start, you can just enter 1 for the start parameter, but you can also use the shorthand function LEFT. The following two SQL statements are functionally equivalent:

If you want to start from the end of the expression, you can use the RIGHT function. It is functionally equivalent to SUBSTRING(expression, LEN(expression), -length), but of course this is not valid syntax for SQL Server. The RIGHT function can be “rewritten” as a LEFT function by using REVERSE, which returns the expression in reverse order.

Keep in mind every character counts when using the substring functions, this also includes white space and non-printable characters. To clean up your text, you can use the LTRIM, RTRIM or TRIM functions. The TRIM function (introduced in SQL Server 2017) is a bit more versatile because it removes from both ends of the string at once, but it can also remove other characters than spaces. If you’re using a version lower than SQL Server 2017, you can implement similar behavior using the REPLACE function.
Parsing Phone Number in SQL Server
The phone numbers in the US and Canada consists of 10 digits: 3 digits for the area code, 3 digits for the central office code and 4 digits for the line number. An example is (415) 555 – 2671. In this example, we want to extract the three parts of the phone number.
First, we can get rid of all the extra characters using the TRIM and REPLACE functions:
SELECT
PhoneNumber = '(415) 555 - 2671'
,CleanedNumber = REPLACE( REPLACE( TRIM(' (' FROM '(415) 555 - 2671') ,') ','') ,' - ','')
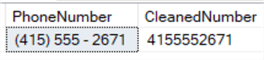
Now that only the digits remain, we can extract the different parts using SUBSTRING:
WITH CTE_Cleaning AS ( SELECT PhoneNumber = '(415) 555 - 2671' ,CleanedNumber = REPLACE( REPLACE( TRIM(' (' FROM '(415) 555 - 2671') ,') ','') ,' - ','') ) SELECT [PhoneNumber] ,AreaCode = SUBSTRING([CleanedNumber],1,3) ,CentralOfficeCode = SUBSTRING([CleanedNumber],4,3) ,LineNumber = SUBSTRING([CleanedNumber],7,4) FROM [CTE_Cleaning]
The result:

Parsing an Email Address in SQL Server
Telephone numbers have a fixed structure, but email addresses are a bit more tricky to parse since you don’t know their exact length upfront. An email address has the following format:
<recipient>@domain
Where domain = <domain name>.<top-level domain>
In this example, we’re assuming there’s only one @ symbol present in the email address. Technically, you can have multiple @ symbols, where the last one is the delimiter between the recipient and the domain. This is for example a valid email address: “user@company”@company.com. This is out of scope for this tip.
Using the CHARINDEX function, we can find the position of the @. The recipient can then be found by taking the start of the email address right until the @ symbol. The domain is everything that comes after the @ symbol. If you also want to extract the top-level domain, you cannot search for the first dot starting from the right, since some top-level domains have a dot, for example co.uk. Let’s see how we can parse the email address john.doe@mssqltips.co.uk.
WITH cte_sample AS ( SELECT email = 'john.doe@mssqltips.co.uk' ) SELECT email ,recipient = SUBSTRING(email,1,CHARINDEX('@',email,1) - 1) ,fulldomain = SUBSTRING(email,CHARINDEX('@',email,1) + 1,LEN(email)) ,domainname = SUBSTRING( email ,CHARINDEX('@',email,1) + 1 -- start is one char after the @ , -- starting position of charindex is the position of @ CHARINDEX('.',email,CHARINDEX('@',email,1)) - CHARINDEX('@',email,1) -- length is the position of the first dot after the @ - position of the @ ) ,toplevel = SUBSTRING( email ,CHARINDEX('.',email,CHARINDEX('@',email,1)) + 1 -- position of first dot after @ ,LEN(email) ) FROM [cte_sample]
For both the full domain as for the top-level domain, we specified LEN(email) which is too long. However, if the length specified for SUBSTRING is longer than there are characters, everything is returned until the last character. This avoids having us writing a more complicated expression to calculate the correct length, while the only thing we want is the substring from a certain position right until the end of the string.
Extracting File Name from a File Path in SQL Server
When you want to extract the file name from a file path, you have to start from the right. There can be any number of subfolder between the root and your file:
/rootfolder/subfolder1/subfolder2/…/subfolderN/myfile.csv
(a lot of programming languages and non-Windows operating systems use forward slashes in their file paths. Windows uses backwards slashes – which is typically a reserved symbol in many programming languages – but it can accept forward slashes as well)
If we want to extract the file name, we can use the following SQL statement, where we use the REVERSE function to flip the string around, since CHARINDEX can only search from left to right:
WITH cte_sample AS ( SELECT filepath = '/rootfolder/subfolder/myfile.csv' ) SELECT filepath ,fullfilename = REVERSE(SUBSTRING(REVERSE(filepath),1,CHARINDEX('/',REVERSE(filepath)) - 1)) FROM [cte_sample]
The result:

If you want the file name without the extension, we have to start the search after the first dot from the right. We can modify the SQL statement as follows:
WITH cte_sample AS ( SELECT filepath = '/rootfolder/subfolder/myfile.csv' ) SELECT filepath ,fullfilename = REVERSE(SUBSTRING(REVERSE(filepath),1,CHARINDEX('/',REVERSE(filepath)) - 1)) ,filenamenoextension = REVERSE(SUBSTRING( REVERSE(filepath) ,CHARINDEX('.',REVERSE(filepath)) + 1 ,CHARINDEX('/',REVERSE(filepath)) - CHARINDEX('.',REVERSE(filepath)) -1 ) ) FROM [cte_sample]
The start position for the SUBSTRING function is the position of the first dot +1 extra position shifted to the left (or right when the string is reversed). The length is the position of the first slash minus the position of the first dot minus one (to remove the slash itself). This results in the following:

Parsing an URL is similar to parsing a file path, and various use cases are described in the tip Parsing a URL with SQL Server Functions.
Prefix Extraction in SQL Server
Suppose we have a free text column containing the full names of people. We want to extract the prefixes, such as Mr., Mrs., Ms., Dr. etc. Since it’s nearly impossible to write one SQL statement that is able to parse all known prefixes, let’s assume the prefix is always abbreviated with a dot followed by a space (between the prefix and the first name). First, we’re going to check if there even is a prefix. Using the CHARINDEX function, we can find if there’s a dot followed by a space, then we use the LEFT function to extract the prefix. If there’s no prefix, CHARINDEX returns zero.
WITH cte_sampledata AS ( SELECT FullName = 'Ms. Doubtfire' UNION ALL SELECT 'Dr. Zeuss' UNION ALL SELECT 'Ir. Koen Verbeeck' UNION ALL SELECT 'Mr. Bruce Wayne' UNION ALL SELECT 'Selina Kyle' ) SELECT FullName ,Prefix = IIF( CHARINDEX('. ',FullName) = 0 ,'No Prefix Found' ,LEFT(FullName,CHARINDEX('. ',FullName)) ) FROM cte_sampledata
This returns the following results:

If you only want a selected list of prefixes to extract, you can use a lookup table as an alternative. In the following piece of code, a lookup table is added (using a common table expression, but in reality you probably want to persist this table) and it is matched against the full name using a LEFT OUTER JOIN. In the code, we search for the first space in the full name. If there’s no prefix, most likely the first name (or a part of the first name) is returned. In this case, the join doesn’t return a match.
WITH cte_sampledata AS ( SELECT FullName = 'Ms. Doubtfire' UNION ALL SELECT 'Dr. Zeuss' UNION ALL SELECT 'Ir. Koen Verbeeck' UNION ALL SELECT 'Mr. Bruce Wayne' UNION ALL SELECT 'Selina Kyle' ) , cte_lookuplist AS ( SELECT Prefix = 'Ms.' UNION ALL SELECT 'Dr.' UNION ALL SELECT 'Ir.' UNION ALL SELECT 'Mr.' ) SELECT s.FullName ,Prefix = ISNULL(CONVERT(VARCHAR(20),l.Prefix),'No Prefix Found') FROM cte_sampledata s LEFT JOIN cte_lookuplist l ON l.[Prefix] = LEFT(s.FullName,ABS(CHARINDEX(' ',s.FullName)-1
The check with CHARINDEX to see if there’s an actual space is dropped, but if there’s a name without a space, CHARINDEX will return zero. Subtracted by one, the length is negative and LEFT will return the error previously mentioned. To resolve this issue, the ABS function is used. In the unlikely case the name does not have a space, the first character will be returned.
The code has the following output:

Suffix Extraction in SQL Server
Extracting suffixes from a name is similar as extracting prefixes, but there are some differences. Of course, suffixes come after a name, which means it can be preceded with any number of spaces. A suffix doesn’t necessarily end with a dot. You have Jr. and Sr., but also PhD, the 3rd and Roman numerals. Since a suffix can contain dots itself (M.B.A. or D.D. for example) and possibly spaces as well (e.g. when III as written out as “the third”), it becomes a bit harder to define a cut-off point to extract the suffix. If we make the assumption there are no spaces and the suffix is always at the end of the string, we can use a combination of REVERSE and LEFT to extract the suffix. REVERSE is used since in SQL Server we cannot tell CHARINDEX to start searching from the end of an expression.
WITH cte_sampledata AS ( SELECT FullName = 'Indiana Jones Jr.' UNION ALL SELECT 'Marshall Mathers 3rd' UNION ALL SELECT 'Martin Luther King Sr.' UNION ALL SELECT 'King Albert I' ) SELECT s.FullName ,Suffix = REVERSE(LEFT(REVERSE(s.FullName),CHARINDEX(' ',REVERSE(s.FullName))-1)) FROM cte_sampledata s;
The problem with this solution is that if there is no suffix, most likely the last name (or part thereof) is returned.

Working with a lookup list of known suffixes might yield better results in this case. If we use the LIKE operation in the LEFT JOIN, we can even match suffixes with spaces in them.
WITH cte_sampledata AS ( SELECT FullName = 'Indiana Jones Jr.' UNION ALL SELECT 'Marshall Mathers 3rd' UNION ALL SELECT 'Martin Luther King Sr.' UNION ALL SELECT 'King Albert I' UNION ALL SELECT 'Bruce Wayne' UNION ALL SELECT 'Alec Baldwin the third' ) , cte_lookuplist AS ( SELECT Suffix = 'Jr.' UNION ALL SELECT 'Sr.' UNION ALL SELECT 'I' UNION ALL SELECT 'II' UNION ALL SELECT 'III' UNION ALL SELECT '3rd' UNION ALL SELECT 'the third' ) SELECT s.FullName ,Suffix = ISNULL(l.Suffix,'N/A') FROM cte_sampledata s LEFT JOIN cte_lookuplist l ON s.FullName LIKE '%' + l.Suffix
The result:

It’s clear working with a suffix table can be more flexible than writing an expression using SUBSTRING, but you have to maintain a list of known suffixes and all of their variations. To avoid case sensitivity issues, you can use the UPPER function on both sides of the LEFT JOIN to make everything upper case. Also be aware that using roman numerals can lead to issues. I, II and III will all be matched by I, as well as any name ending in i (if there’s no case sensitivity).
Extracting Values from a Comma Separated List in SQL Server
Let’s assume we have a comma separated list and we want to retrieve a specific item from that list, for example the 2nd item. The first and last item are easier, as you can just search for the first comma and extract from either the start or the end of the string, as has been demonstrated in the previous paragraphs. But when you need an item of which you don’t know the exact position, it gets trickier.
The problem is SQL Server currently doesn’t support this scenario with the built-in functions.
You could use STRING_SPLIT to split out the list into its individual items, but unfortunately the function only returns the members of the list but not an ordinal column (a column containing the index of each member). Also, it doesn’t guarantee any ordering, so you cannot calculate the ordinal column yourself. The following example splits a couple of arrays using STRING_SPLIT.
WITH sampleData AS ( SELECT myArray = 'one,two,three,four,five' UNION ALL SELECT myArray = 'one,two,three,four' UNION ALL SELECT 'Hello,Readers,Of,The,MSSQLTips,Website,!' ) SELECT [myArray] ,value FROM [sampleData] CROSS APPLY STRING_SPLIT([myArray],','

It seems everything is returned in the correct order (again, this is not guaranteed), but we have no way of telling SQL Server we want the second element of each list. We could try to add an index column using ROW_NUMBER(), but what will we sort on?
Another option would be to use CHARINDEX, but unfortunately, we cannot specify we need a specific occurrence of the expression we’re seeking. For example, it’s not possible to specify we need the 2nd occurrence of the comma delimiter. CHARINDEX only allows you to set a starting position.
So let’s use a ready-to-use function that splits a list and returns an index column as well, laid out in this excellent solution by Jeff Moden. The function heavily uses “Tally” tables or number tables. Examples of such tables can be found in the tip How to Expand a Range of Dates into Rows using a Numbers Table. I’d recommend to fully read Jeff’s article, as it demonstrates a very clever use of tally tables, SUBSTRING and CHARINDEX to get the job done.
We can use the table function on a set of sample data by using CROSS APPLY.
WITH sampleData AS ( SELECT myArray = 'one,two,three,four,five' UNION ALL SELECT myArray = 'one,two,three,four' UNION ALL SELECT 'Hello,Readers,Of,The,MSSQLTips,Website,!' UNION ALL SELECT 'one,two' UNION ALL SELECT 'one' ) SELECT s.[myArray] ,d.[ItemNumber] ,d.[Item] FROM sampleData s CROSS APPLY [dbo].[DelimitedSplit8K](s.myArray,',') d
We get the following result:

Extracting the item from the list is as simple as filtering on the ItemNumber. In the next SQL snippet, we extract the second item of each list. Observer the list with one item does not return a result.
WITH sampleData AS ( SELECT myArray = 'one,two,three,four,five' UNION ALL SELECT myArray = 'one,two,three,four' UNION ALL SELECT 'Hello,Readers,Of,The,MSSQLTips,Website,!' UNION ALL SELECT 'one,two' UNION ALL SELECT 'one' ) SELECT s.[myArray] ,d.[ItemNumber] ,d.[Item] FROM sampleData s CROSS APPLY [dbo].[DelimitedSplit8K](s.myArray,',') d WHERE d.[ItemNumber] = 2
You can of course parameterize this filter.
Median Search in SQL Server
Let’s assume we have again a comma separated list and we want to retrieve the middle value of this list. For example, if we have the string 'one,two,three,four,five', we want to return the string 'three'. In the case of 'one,two,three,four', there’s no discrete median value (in mathematics this would be 2.5 but we cannot apply this to strings). So let’s make the assumption we will return the string right before the median, in this case 'two'.
There are a couple of steps we need to take to be able to extract the middle value out of a list:
- First, we need to determine how many items the list has. We can do this by counting the number of delimiters. A list of 10 items has 9 delimiters.
- Once we now the number of items, we can determine which is the middle member. This can be done by assigning an index to each member and calculating the medium of those indexes. For example, for a list of 7 members we have the following indexes: [1,2,3,4,5,6,7]. The median of those values is 4.
- Once we know the index of the median member, we can extract it using the solution provided in the previous paragraph.
Let’s see how we can translate all those steps to T-SQL. Counting the number of items can be done by getting the full length of the list and subtracting it with the list with all of the delimiters removed. The difference gives us the number of times the delimiter appeared in the string. This technique can also generalized: you can use it to find out how many occurrences a certain word occurs in a text.
The following SQL statement calculates the number of items for 3 sample lists:
WITH sampleData AS ( SELECT myArray = 'one,two,three,four,five' UNION ALL SELECT myArray = 'one,two,three,four' UNION ALL SELECT 'Hello,Readers,Of,The,MSSQLTips,Website,!' ) SELECT myArray ,numberOfMembers = LEN(myArray) - LEN(REPLACE(myArray,',','')) + 1 FROM sampleData
The result:

To calculate the medium, we can repeat the list for each member of the list. Each repetition gets its own unique number. This can be again be done using a “tally table” or numbers table:
WITH E00(N) AS (SELECT 1 UNION ALL SELECT 1) ,E02(N) AS (SELECT 1 FROM E00 a, E00 b) ,E04(N) AS (SELECT 1 FROM E02 a, E02 b) ,E08(N) AS (SELECT 1 FROM E04 a, E04 b) ,E16(N) AS (SELECT 1 FROM E08 a, E08 b) ,cteTally AS (SELECT N = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E16) ,sampleData AS ( SELECT myArray = 'one,two,three,four,five' UNION ALL SELECT myArray = 'one,two,three,four' UNION ALL SELECT 'Hello,Readers,Of,The,MSSQLTips,Website,!' ) ,countmembers AS ( SELECT myArray ,numberOfMembers = LEN(myArray) - LEN(REPLACE(myArray,',','')) + 1 FROM sampleData ) SELECT N, myArray FROM cteTally t JOIN countmembers c ON t.N <= c.[numberOfMembers] ORDER BY myArray, N
This gives us the following result set:

Using the unique row numbers from the previous step, we can now calculate the median index using the PERCENTILE_DISC function. We use the discrete function, as it will always return an index that exists in the set of values. For example, for the list of indexes [1,2,3,4] it will return 2 and not 2.5.
WITH E00(N) AS (SELECT 1 UNION ALL SELECT 1) ,E02(N) AS (SELECT 1 FROM E00 a, E00 b) ,E04(N) AS (SELECT 1 FROM E02 a, E02 b) ,E08(N) AS (SELECT 1 FROM E04 a, E04 b) ,E16(N) AS (SELECT 1 FROM E08 a, E08 b) ,cteTally AS (SELECT N = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E16) ,sampleData AS ( SELECT myArray = 'one,two,three,four,five' UNION ALL SELECT myArray = 'one,two,three,four' UNION ALL SELECT 'Hello,Readers,Of,The,MSSQLTips,Website,!' ) ,countmembers AS ( SELECT myArray ,numberOfMembers = LEN(myArray) - LEN(REPLACE(myArray,',','')) + 1 FROM sampleData ) ,explodedArray AS ( SELECT N, myArray FROM cteTally t JOIN countmembers c ON t.N <= c.[numberOfMembers] ) SELECT DISTINCT myArray ,medianMemberIndex = PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY N) OVER (PARTITION BY myArray) FROM explodedArray
We can verify the calculation works:

We can combine this SQL statement with the solution of the paragraph. The final SQL statement looks like this:
WITH E00(N) AS (SELECT 1 UNION ALL SELECT 1) ,E02(N) AS (SELECT 1 FROM E00 a, E00 b) ,E04(N) AS (SELECT 1 FROM E02 a, E02 b) ,E08(N) AS (SELECT 1 FROM E04 a, E04 b) ,E16(N) AS (SELECT 1 FROM E08 a, E08 b) ,cteTally AS (SELECT N = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E16) ,sampleData AS ( SELECT myArray = 'one,two,three,four,five' UNION ALL SELECT myArray = 'one,two,three,four' UNION ALL SELECT 'Hello,Readers,Of,The,MSSQLTips,Website,!' UNION ALL SELECT 'one,two' UNION ALL SELECT 'one' ) ,countmembers AS ( SELECT myArray ,numberOfMembers = LEN(myArray) - LEN(REPLACE(myArray,',','')) + 1 FROM sampleData ) ,explodedArray AS ( SELECT N, myArray FROM cteTally t JOIN countmembers c ON t.N <= c.[numberOfMembers] ) ,medianposition AS ( SELECT DISTINCT myArray ,medianMemberIndex = PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY N) OVER (PARTITION BY myArray) FROM explodedArray ) SELECT m.myArray ,m.medianMemberIndex ,d.[Item] FROM [medianposition] m CROSS APPLY [dbo].[DelimitedSplit8K](m.myArray,',') d WHERE d.[ItemNumber] = m.[medianMemberIndex]
In the sample data, two arrays with respectively one and two members are added again to demonstrate the edge cases. The calculation of the starting position now uses the ISNULL function to check for NULL values. This will ensure the SQL code returns an item when there’s only one item in the list.

Performance Impact of using SQL Server SUBSTRING
Using SUBSTRING in the SELECT clause will not have a noticeable performance impact. But using SUBSTRING – or any other function – in a WHERE clause or JOIN can lead to issues when the function prevents an index from being used. This is the general problem of SARGable queries, which is explained in the following article: Non-SARGable Predicates.
In short, this is bad:
WHERE SUBSTRING(mycolumn,start,length) = 'someText'
But this is better:
WHERE mycolumn = ‘someOtherText'
In the second example, if there’s an index on the mycolumn column, it can actually be used by the engine. Let’s illustrate this with an example. In the AdventureWorks2017 data warehouse, we’re going to search for all employees for which the central office code is not 555:

Assume the employee table is very large and we want this query to run as efficient as possible, so we create an index on the Phone column.
CREATE INDEX IX_Employee_Phone ON [AdventureWorksDW2017].[dbo].[DimEmployee](Phone
However, if we run the query, the index is not used:

If we checked the first characters of the phone number, we could use the following format:
WHERE Phone LIKE '555%'
In this case, the index will be used. But we’re searching for a piece of text in the middle of our column. How can we solve this? We can add a persisted calculated column to the table which pre-calculates the central office code:
ALTER TABLE [AdventureWorksDW2017].[dbo].[DimEmployee] ADD [PhoneCentralOfficeCode] AS SUBSTRING(Phone,5,3) PERSISTED
Then we can add an index on this column (we’re going to create a covering index including all of the columns from the SELECT clause, otherwise the optimizer chooses for a clustered index scan of the primary key since the Employee table is quite small):
CREATE NONCLUSTERED INDEX [IX_Employee_PhoneCentralOfficeCode] ON [AdventureWorksDW2017]. [dbo].[DimEmployee] ( [PhoneCentralOfficeCode] ASC ) INCLUDE([EmployeeKey],[FirstName],[LastName],[Phone])
When we now run the following query, we can see the index is being used:
SELECT
[EmployeeKey]
,[FirstName]
,[LastName]
,[Phone]
FROM [AdventureWorksDW2017].[dbo].[DimEmployee]
WHERE [PhoneCentralOfficeCode] = '555'

Next Steps
- In your environment, check out how you can use the SUBSTRING function to solve your problems.
- Some extra SQL reference guides:
- SQL Server CROSS APPLY and OUTER APPLY
- SQL Server Text Data Manipulation
- SQL Server Substring Function Example with T-SQL, R and Python
- SQL Server String Functions Tutorial
- SQL String functions in SQL Server, Oracle and PostgreSQL
- Parsing a URL with SQL Server Functions
- Name Parsing with SQL Server Functions and T-SQL Programming
- How to Extract URLs from HTML using Stored Procedure in SQL Server
- SQL Server STR Function

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


