Problem
We are storing large text and URLs that are over 900 bytes in some of our tables and have a requirement to enforce uniqueness in those columns. But SQL Server has a limitation that index size can’t be over 900 bytes. How do I enforce uniqueness in these columns and is it possible to achieve this in SQL Server 2005 and above? What are my different options to solve this problem? I heard that we can use CHECKSUM to create a hash, but is it possible to avoid collisions in the hash value as we are storing millions of rows?
Solution
In SQL Server, an unique constraint is enforced using an unique index on the column. But the index key size has a limitation of 900 bytes and this is why we can’t enforce the unique constraint on columns over 900 bytes. This limitation not only applies to indexes, but also for foreign keys and primary keys as well. This 900 byte limitation is documented in the Maximum Capacity Specifications for SQL Server.
What happens if data goes over 900 bytes?
Let’s take a step back and see what happens when data is added that violates the 900 bytes constraint. Using the below script, create a table with more than 900 bytes with a unique constraint. SQL Server gives us a warning about the key length and informs that future inserts and updates will fail. This is OK for now.
IF OBJECT_ID('dbo.Violate900byte', 'U') IS NOT NULL
DROP TABLE dbo.Violate900byte
GO
CREATE TABLE dbo.Violate900byte (ReallyLongText VARCHAR(1000) NOT NULL,
CONSTRAINT UC_ReallyLongText UNIQUE (ReallyLongText))
GO
--Output Message
/*
Warning! The maximum key length is 900 bytes. The index 'UC_ReallyLongText'
has maximum length of 1000 bytes.
For some combination of large values, the insert/update operation will fail.
*/
Now add data that violates the constraint’s index key length by inserting a longer text with more than 900 bytes and SQL Server throws an error message ‘Msg 1946, Level 16, State 3, Line 1 Operation failed.’ right back.
INSERT dbo.Violate900byte SELECT REPLICATE('A', 901)
GO
--Output Message
/*
Msg 1946, Level 16, State 3, Line 1
Operation failed. The index entry of length 901 bytes for the index 'UC_ReallyLongText'
exceeds the maximum length of 900 bytes.
*/
Now we have seen how, why and what happens when the 900 byte limit is hit.
Let’s explore some options to solve this problem.
CHECKSUM to the rescue?
SQL Server has a CHECKSUM feature and it can be used to generate a hash value based on a large text column and possibly index the hash value. The hash value generated by the CHECKSUM is an INTEGER which takes up only 4 bytes and one should be able to enforce a unique constraint on the hash value. Let’s give this option a try and see what happens.
--Create the table
IF OBJECT_ID('dbo.Violate900byte', 'U') IS NOT NULL
DROP TABLE dbo.Violate900byte
GO
CREATE TABLE dbo.Violate900byte (
ReallyLongText VARCHAR(1000) NOT NULL
, CHECKSUM_ReallyLongText INT
, CONSTRAINT UC_CHECKSUM_ReallyLongText UNIQUE (CHECKSUM_ReallyLongText))
GO
--Insert long text
INSERT dbo.Violate900byte SELECT REPLICATE('A', 901), CHECKSUM(REPLICATE('A', 901))
--Check the data
SELECT * FROM dbo.Violate900byte
Although, it seems that our problem is solved by the CHECKSUM trick, in fact its not. As noted earlier, CHECKSUM generates an INTEGER value which has only a limited range of values when compared to all possible text that can be generated. There is a higher risk to have collisions in the hash value even for distinct text values.
Let’s run a test to see the risk of collisions using CHECKSUM. The below script is run in the AdventureWorks database. To have distinct values sys.objects and sys.columns are CROSS JOINed to generate 20 million records quickly.
/*Generate distinct possible text with sys.objects, sys.columns,
reverse name of sys.objects using CROSS JOIN.
Also add some extra characters like space, comma, colon and period
to simulate real text.
*/
WITH
X1 AS ( SELECT name AS C FROM sys.objects)
, X2 AS ( SELECT DISTINCT name AS C FROM sys.columns)
, X3 AS ( SELECT REVERSE(name) AS C FROM sys.objects)
SELECT TOP 20000000
X1.C + ' ' + X2.C + ', ' + X3.C + '''' + '. ' AS C1
, CHECKSUM( X1.C + ' ' + X2.C + ', ' + X3.C + '''' + '. ') AS C2
INTO ##CHECKSUM
FROM X1 CROSS JOIN X2 CROSS JOIN X3
Astonishingly, the above script generates 46,396 hash collisions for a 20 million data set.
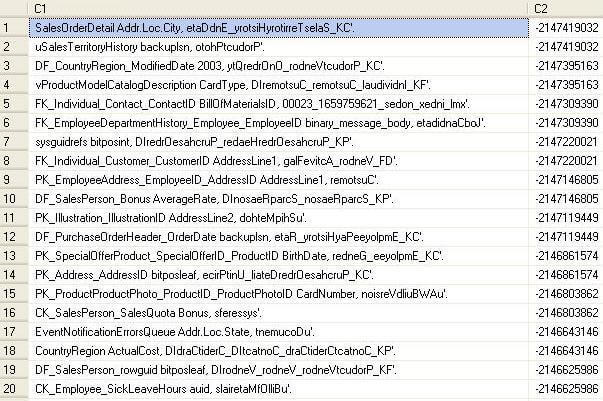
Let’s see if the hash collisions are indeed similar text or from distinct text values using the below queries. The below picture tells the story louder and clearer than any words.
--Check for HASH collisions
SELECT C2, COUNT(1) FROM ##CHECKSUM
GROUP BY C2
HAVING COUNT(1) > 1
--Check if HASH collisions are indeed similar text
SELECT a.*
FROM ##CHECKSUM a JOIN (
SELECT C2 FROM ##CHECKSUM
GROUP BY C2
HAVING COUNT(1) > 1) b
ON a.C2 = b.C2
ORDER BY a.C2
We can see below that C2 is the same, but C1 is totally different.
Know your data
For any DBA, understanding what kind of data is supported in the system is very important and this information might be useful to solve this problem. Even though large text longer than 900 bytes is stored in the column but if the data is guaranteed to be unique within 900 bytes then one can create a computed column and apply the unique constraint on the computed column.
This technique is illustrated below.
--Create the table
IF OBJECT_ID('dbo.Unique900byte', 'U') IS NOT NULL
DROP TABLE dbo.Unique900byte
GO
CREATE TABLE dbo.Unique900byte (
ReallyLongText VARCHAR(1000) NOT NULL
, Unique_ReallyLongText AS SUBSTRING ( ReallyLongText, 1, 900)
, CONSTRAINT UC_Unique900byte_Unique_ReallyLongText UNIQUE (Unique_ReallyLongText))
GO
--Insert long text
INSERT dbo.Unique900byte SELECT REPLICATE('A', 900)+ 'This is just a filler data'
INSERT dbo.Unique900byte SELECT REPLICATE('B', 900)+ 'This is just a filler data'
--Check the data
SELECT * FROM dbo.Unique900byte
Good old Triggers?
TRIGGERS can be used to enforce unique constraints. In this case by adding a CHECKSUM to the long text column, performance could also be improved. Without the CHECKSUM and an index on the CHECKSUM hashed value, performance could be a potential problem leading to table scans.
The below script demonstrates how TRIGGERS can be used to enforce the unique constraint.
--Create the table
IF OBJECT_ID('dbo.Violate900byte', 'U') IS NOT NULL
DROP TABLE dbo.Violate900byte
GO
CREATE TABLE dbo.Violate900byte (
ReallyLongText VARCHAR(1000) NOT NULL
, CHECKSUM_ReallyLongText AS CHECKSUM(ReallyLongText)
)
GO
CREATE INDEX idx_Violate900byte_CHECKSUM_ReallyLongText ON dbo.Violate900byte (CHECKSUM_ReallyLongText)
GO
IF OBJECT_ID('dbo.Trigger_Violate900byte', 'TR') IS NOT NULL
DROP TRIGGER dbo.Trigger_Violate900byte
GO
CREATE TRIGGER dbo.Trigger_Violate900byte ON dbo.Violate900byte
AFTER INSERT, UPDATE
AS
BEGIN
IF EXISTS (SELECT 1 FROM INSERTED i JOIN dbo.Violate900byte v
ON CHECKSUM(i.CHECKSUM_ReallyLongText) = v.CHECKSUM_ReallyLongText
AND i.ReallyLongText = v.ReallyLongText
GROUP BY v.ReallyLongText
HAVING COUNT(1) > 1)
BEGIN
RAISERROR ('Unique constraint violation on ReallyLongText in dbo.Violate900byte', 16, 1)
ROLLBACK TRAN;
END
END
GO
Once the above scripts are executed, we can do a dry run to test the unique constraint with the below script. While the first insert succeeds, the second script will fail. The application code should be designed in such a way to catch the error message and act accordingly.
--This will succeed
INSERT dbo.Violate900byte SELECT REPLICATE('A', 900)
GO
--This insert will fail
INSERT dbo.Violate900byte SELECT REPLICATE('A', 900)
--Check the data
SELECT * FROM dbo.Violate900byte
GO
/*
Msg 50000, Level 16, State 1, Procedure Trigger_Violate900byte, Line 11
Unique constraint violation on ReallyLongText in dbo.Violate900byte
Msg 3609, Level 16, State 1, Line 2
The transaction ended in the trigger. The batch has been aborted.
*/
While Triggers do the job to enforce the unique constraint effectively there is still overhead to check against the table if the value already exists in the table for every data modification. This overhead can be considerable if the table has frequent inserts and updates and the data in the table is huge.
HASHBYTES the winner?
Starting with SQL Server 2005, HASHBYTES can be used to enforce the UNIQUE constraint. HASHBYTES returns a VARBINARY value with a maximum of 8000 bytes of the input text. To use this function, an algorithm name should also be specified. SHA1 is the preferred algorithm as the chances of duplicates is very very minimal.
Compared to CHECKSUM, HASHBYTES is way better in reducing the collisions, but it still leaves the door open for collisions. The odds of duplicates though is considerably lower.
The below script generates 100 million records using a CROSS JOIN between sys.objects and sys.columns and a HASHBYTES value is generated. This VARBINARY hash value is type casted to a BIGINT so that we can index the hashed value. This indexed hash value will be useful for retrieving the data quickly and helps performance.
--Generate 100 million rows with HASHBYTES
WITH
X1 AS ( SELECT name AS C FROM sys.objects)
, X2 AS ( SELECT distinct name AS C FROM sys.columns)
, X3 AS ( SELECT reverse(name) AS C FROM sys.objects)
SELECT TOP 100000000
X1.C + ' ' + X2.C + ', ' + X3.C + '''' + '. ' AS C1
, CAST(HASHBYTES ('SHA1', X1.C + ' ' + X2.C + ', ' + X3.C + '''' + '. ') AS BIGINT) AS C2
INTO ##HASHBYTES
FROM X1 CROSS JOIN X2 CROSS JOIN X3
The above script generates 0 duplicate hash values for the 100 million records. To put into perspective, CHECKSUM generated 46,396 duplicates for 20 million records, but HASHBYTES generated 0 duplicate hash values for 5 times the data set. As per Michael Coles, the odds of a duplicate hash value with HASHBYTES is 1 in 1,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000 values. Can you really count that?
Recap
All companies will not have the problem of enforcing unique constraints for really long text values longer than 900 bytes, but when you have the need, its important to know all the possible solutions to the problem. While CHECKSUM alone seems like a terrible solution due to high risk of collisions, HASHBYTES seems to be the winner with less chance of duplicate hash values. It is very important to know the data and if the data is unique in 900 bytes then a computed column should be a good solution. It is also important to understand the performance overhead of using TRIGGERS to enforce the unique constraint.
Next Steps
- Catch up on HASHBYTES and CHECKSUM.
- Take a look at Steve Jones post on HASHBYTES.
- The algorithm used for HASHBYTES dictates the chances of possible collisions, while SHA1 is the best available algorithm in SQL Server, SHA2 is even better. Unfortunately SHA2 algorithm is NOT available to use in SQL Server natively, one can use CLR to use SHA2. Watch this space for that tip soon.
- Wait and watch this space for thorough article on HASHBYTES soon.

Sankar is a Database Engineer/DBA currently working for FunMobility, a mobile media entertainment company. He has been working with SQL Server from 2003 in a variety of roles including development DBA, Database administrator, Report writer and datawarehouse developer. Currently he works with high traffic OLTP and Tera byte datawarehouse systems. Sankar spends most of his free time at MSDN social forums answering questions.