Problem
Query Performance. This is the area within database administration that I find most interesting and challenging. Taking a query and making it run faster than it did before or use fewer resources to complete always gives me a sense of accomplishment. In a lot of cases this performance improvement is found by adding an index to address some predicate in the query. Either a WHERE clause or an ORDER BY or even just the columns in the SELECT list. If you are new to SQL Server, with all of the different index types that are available, it can be difficult to decide which one would be the best fit for your particular use case. In the following tip we will go through each type of index that is available in SQL Server and give an overview as well as advice on which index types fit each particular use case.
Solution
SQL Server Heap Tables
What is a SQL Server Heap?
Before we get into the different types of indexes that are available in SQL Server we should first describe the basic structure of a table. Tables with no clustered index defined (more on that later) are stored in a heap structure which essentially means that the data is stored as an unordered data set in each page.
SQL Server Heap Benefits and Usage
The main use case for implementing a heap structure is when you require fast INSERT performance on your table. Think of a log or audit table where new data is constantly being written. With a heap structure, there is no need for the database engine to figure out where to insert the new data. It simply adds data to the last page or if full, allocates a new page and writes the data in that page.
SQL Server Heap Disadvantages
Querying a heap table can be very slow. Especially if there aren’t any non-clustered indexes defined on the table. Without any indexes, every query that accesses the heap table must perform a full table scan and we all know how expensive that can be if the table is large.
SQL Server Heap Basic Syntax
CREATE TABLE TestData
(TestId integer,
TestName varchar(255),
TestDate date,
TestType integer,
TestData1 integer,
TestData2 varchar(100),
TestData3 XML,
TestData4 varbinary(max),
TestData4_FileType varchar(3));
ALTER TABLE TestData REBUILD;
DROP TABLE TestData; More Information on SQL Server Heaps
- SQL Server Heap
- SQL Server Clustered Tables vs Heap Tables
- SQL Server Tables Without a Clustered Index
SQL Server Clustered Index
What is a SQL Server Clustered Index?
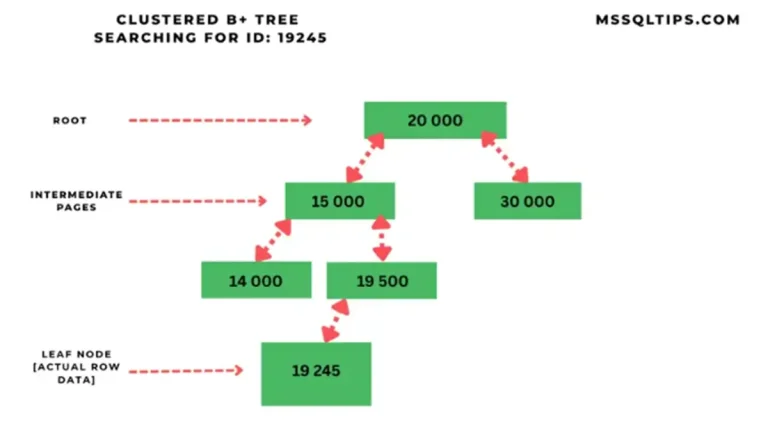
A clustered index is one of the main index types in SQL Server. A clustered index stores the index key in a B-tree structure along with the actual table data in each leaf node of the index. Having a clustered index defined on a table eliminates the heap table structure we described in the previous section. Since the rest of the table data (eg. non-key columns) is stored in the leaf nodes of the index structure, a table can only have one clustered index defined on it.
SQL Server Clustered Index Benefits and Usage
The are many benefits to having a clustered index defined on a table but the main benefit is speeding up query performance. Queries that contain the index key columns in the WHERE clause use the index structure to go straight to the table data. A clustered index also removes the need for an extra lookup, to get the rest of the column data, when querying based on the index key values. This is something that is not true of other index types. You can also eliminate the need to sort data. If the ORDER BY clause of a query is based on the index key values then a sort is not required since the data is already ordered by these values.
SQL Server Clustered Index Disadvantages
There are a couple of disadvantages when it comes to clustered indexes. There is some overhead in maintaining the index structure with respect to any DML operation (INSERT, UPDATE, DELETE). This is especially true if you are updating the actual key values in the index as in this case all of the associated table data also has to be moved as it is stored in the leaf node of the index entry. In each case there will be some performance impact to your DML query.
SQL Server Clustered Index Basic Syntax
CREATE CLUSTERED INDEX IX_TestData_TestId ON dbo.TestData (TestId);
ALTER INDEX IX_TestData_TestId ON TestData REBUILD WITH (ONLINE = ON);
DROP INDEX IX_TestData_TestId on TestData WITH (ONLINE = ON);More Information on SQL Server Clustered Indexes
- SQL Server Clustered Index
- SQL Server Clustered Index Behavior Explained via Execution Plans
- Make Sure all Tables have a Clustered Index Defined
SQL Server Non-Clustered Index
What is a SQL Server Non-Clustered Index?
A non-clustered index is the other main type of index used in SQL Server. Similar to its clustered index counterpart, the index key columns are stored in a B-tree structure except in this case the actual data is not stored in the leaf nodes. In this type of index, a pointer to the actual table data is stored in the leaf node. This could point to the data value in the clustered index or in a heap structure depending on how the table data is stored.
SQL Server Non-Clustered Index Benefits and Usage
The benefits of a non-clustered index are similar to that of the clustered index we mentioned above, the main benefit being speeding up query performance. There are however two differences. The first is that you can have multiple non-clustered indexes defined on a single table. This allows you to index different columns which can help queries with different columns in the WHERE clause allowing you to fetch data faster and in the ORDER BY clause to eliminate a need for a sort. The second is that although there is overhead for a non-clustered index when it comes to DML operations there is less than its clustered counterpart.
SQL Server Non-Clustered Index Disadvantages
Similar to the clustered index the main disadvantage of a non-clustered index is the extra overhead required in maintaining the index during DML operations. It can sometimes be tricky to balance query performance as having too many non-clustered indexes on a table, while they will help all of your SELECT queries, can sometimes really slow down DML performance.
SQL Server Non-Clustered Index Basic Syntax
CREATE INDEX IX_TestData_TestDate ON dbo.TestData (TestDate);
ALTER INDEX IX_TestData_TestDate ON TestData REBUILD WITH (ONLINE = ON);
DROP INDEX IX_TestData_TestDate on TestData;SQL Server Column Store Index
What is a SQL Server Column Store Index?
A column store index is a different type of non-clustered index that uses a column-based storage format in order to index the data. Column store indexes can be created as a clustered or as non-clustered index.
SQL Server Column Store Index Benefits and Usage
Column store indexes were designed to be used when indexing very large amounts of data in data warehouse applications, specifically for fact tables. Depending on the data being indexed you can see up to a 100 times improvement in query performance. Column store indexes also provide an option for data compression. Depending on your data you could see up to 10 times saving in storage space. The less selective your column is, the more it can be compressed.
SQL Server Column Store Index Disadvantages
As with every feature there are some drawbacks when it comes to column store indexes. They can’t be used with all datatypes: varchar(max)/nvarchar(max), xml and text/ntext, image and CLR types are not supported for column store indexes. They also can’t be used if features such as replication, change data capture or change tracking are enabled. With regards to performance, although your SELECT queries can see a big benefit that is not the case with DML operations. Due to the overhead required when updating a column store index any DML operations will perform worse than a row-based counterpart. Finally, although this shouldn’t be much of an issue anymore as hopefully you are on a recent release of SQL Server, prior to SQL Server 2014 column store indexes were not updatable so having one on your table essentially made it read only.
SQL Server Column Store Index Basic Syntax
CREATE CLUSTERED COLUMNSTORE INDEX CIX_TestData_TestType ON TestData.TestType
WITH (DATA_COMPRESSION = COLUMNSTORE);
ALTER INDEX CIX_TestData_TestType ON TestData REORG IX_TestData_TestDate;
DROP INDEX CIX_TestData_TestType;More Information on SQL Server Column Store Indexes
- SQL Server Columnstore Index Performance
- SQL Server Clustered Columnstore Index Examples for ETL
- Supercharge your Data Warehouse with Columnstore Indexes
- SQL Server 2016 Columnstore Index Enhancements
SQL Server XML Index
What is a SQL Server XML Index?
XML indexes are a special type of index that can be created on XML typed columns. There are two types of XML indexes, primary and secondary, which index all tags, values, paths and properties in the XML data in your column. A clustered primary key is required on the table you want create the XML index on since this primary key is used to correlate rows in the primary XML index with rows in the table that contains the XML column.
SQL Server XML Index Benefits and Usage
Generally speaking, you would benefit from having an XML index on a column when your XML values are large but the parts being retrieved are small. This prevents the entire XML value from being loaded into memory and parsed for each query. The primary XML index will index all tags, values and paths in your XML column and can return scalar values or XML subtrees. Secondary XML indexes can be of three different types. A PATH secondary XML index is beneficial if your queries use path expressions. If your queries do not know the attribute names in your XML values then a VALUE secondary XML index can speed up these queries. Queries where the primary key of the of the value object is known and you are using the value() method of the XML type can benefit from at PROPERTY index.
SQL Server XML Index Disadvantages
The main drawback when it comes to XML indexes is they can use massive amounts of disk space since each tag in the XML value results in multiple rows in the index. Also, as with all indexes, there is some performance overhead when updating/maintaining the index that will cause DML operations on the XML column to be slower.
SQL Server XML Index Basic Syntax
-- primary index
CREATE PRIMARY XML INDEX PXML_TestData_TestData3 ON TestData (TestData3);
-- secondary indexes
CREATE XML INDEX XMLPATH_TestData_TestData3 ON TestData (TestData3)
USING XML INDEX PXML_TestData_TestData3 FOR PATH;
CREATE XML INDEX XMLPROPERTY_TestData_TestData3 ON TestData (TestData3)
USING XML INDEX PXML_TestData_TestData3 FOR PROPERTY;
CREATE XML INDEX XMLVALUE_TestData_TestData3 ON TestData (TestData3)
USING XML INDEX PXML_TestData_TestData3 FOR VALUE;More Information on SQL Server XML Indexes
SQL Server Full-Text Indexes
What is a SQL Server Full-Text Index?
A full-text index is a special type of index that provides indexing support for full-text queries. These special indexes can be created on binary or character-based column types as well. They are different from your standard index types in that instead of using the entire column as the index key the column data is broken up into tokens and these tokens are what is used to build the index and used as a predicate when navigating the index structure. The index structure itself is also stored in its own catalog and not in the data files of the database.
SQL Server Full-Text Index Benefits and Usage
Enabling full-text search and allows you to create indexes on columns that are not indexable by the standard index types mentioned earlier. With full-text indexes we can index large varchar(max) and varbinary(max) columns as well as any of the following column types: char, varchar, nchar, nvarchar, text, ntext, image, xml and FILESTREAM. Once the index is created you can write queries that perform indexed searches using full text query functions that will find data related to any of the following conditions. Note: This list is taken directly from the following Microsoft documentation.
- One or more specific words or phrases (simple term)
- A word or a phrase where the words begin with specified text (prefix term)
- Inflectional forms of a specific word (generation term)
- A word or phrase close to another word or phrase (proximity term)
- Synonymous forms of a specific word (thesaurus)
- Words or phrases using weighted values (weighted term)
SQL Server Full-Text Index Disadvantages
Most of the disadvantages of using full-text indexes center around resource consumption. Since the full-text index searches are performed by the MSFTESQL service and not the SQL Server service these two services can compete for memory resources on your server. If not configured correctly with both services in mind this can be an issue. Also, although disk space has become much more inexpensive over the years there is still a premium on the amount of IO performed on your data files so if you have a relatively large catalog it can make sense to have this catalog on its own volume so the two services (SQL Server and MSFTESQL) aren’t competing for this resource.
SQL Server Full-Text Index Basic Syntax
-- catalog is needed before indexes can be created
CREATE FULLTEXT CATALOG fulltextCatalog AS DEFAULT;
CREATE FULLTEXT INDEX ON dbo.TestData (TestData4 TYPE COLUMN TestData4_FileType)
KEY INDEX PK_TestData WITH STOPLIST = SYSTEM;
ALTER FULLTEXT CATALOG fulltextCatalog REBUILD;
DROP FULLTEXT INDEX ON dbo.TestData;More Information on SQL Server Full-Text Indexes
SQL Server Index Variations
SQL Server Index Included Columns
Not really a type of index but it’s actually a clause that can be added to a non-clustered index which stores the column values listed in the clause in the leaf nodes of the index. This allows the non-clustered index to behave kind of like a clustered index in that it can retrieve the column data for these columns with having to do a lookup in the table data. It also allows more columns to be included in the index since it supports columns that could otherwise not be supported as a key column. All datatypes except text, ntext, and image are supported in the included columns clause.
CREATE NONCLUSTERED INDEX IX_TestData_TestDate_incTestData3 ON TestData (TestDate)
INCLUDE (TestData3);SQL Server Function Based (Computed Columns) Index
A function based index is exactly what the name suggests. It’s an index that is created based on the values after a function has been applied to a number of columns. SQL Server unfortunately does not have direct support for function based indexes but you can simulate the functionality using it’s computed column feature. The only requirements for being able to create an index on the computed column is that the function is deterministic and the computed column is persisted. Below is an example.
ALTER TABLE TestData ADD TestDatePlus7Days AS DATEADD(DAY,7,TestDate) PERSISTED;
CREATE NONCLUSTERED INDEX IX_TestData_TestDate_Plus7Days ON TestData (TestDatePlus7Days);SQL Server Filtered Index
A filtered index is a non-clustered index which includes a WHERE clause. They are useful when created on large tables in order to reduce the size of the index, reduce maintenance time and improve query performance for specific queries. Note that this type of index will only be used if the WHERE clause of the index matches the WHERE clause of the query.
CREATE INDEX IX_TestData_TestDate_TestTypeEq1 on TestData (TestDate) WHERE TestType=1;SQL Server Covering Index
A covering index is a non-clustered index where all columns referenced in a query are either part of the index key or are specified in the included column clause of the index creation statement. Covering indexes speed up performance as they eliminate the need to look up any extra column data from the table itself. Below is an example of a covering index which covers all columns in query below referenced below it.
CREATE INDEX IX_TestData_TestDate_TestType_AllData on TestData (TestDate,TestType)
INCLUDE (TestData1,TestData2,TestData3,TestData4);
SELECT TestData1,TestData2,TestData3,TestData4
FROM TestData
WHERE TestDate > current_timestamp-1
and TestType=1;More Information on SQL Server Indexes
- Improve SQL Server Performance with Covering Index Enhancements
- Getting Creative with Computed Columns in SQL Server
- Using Computed Columns in SQL Server with Persisted Values
- How to Create Indexes on Computed Columns in SQL Server
- How to Overcome the SQL Server Filtered Index Unmatched indexes Issue
- SQL Server Filtered Indexes
SQL Server Index Maintenance
As great as indexes can be when it comes to improving the performance of your database, they do require some upkeep to keep them performing optimally. Over time as INSERTs, UPDATEs and DELETEs are executed against your table the indexes associated with each table can become fragmented.
There are many factors that determine how quickly an index will become fragmented but luckily, we have some tools built into SQL Server that will show us exactly how fragmented an index has become. The sys.dm_db_index_physical_stats dynamic management view will give you size and fragmentation statistics on each of your indexes. The below query can be used as a starting point to list the fragmentation of your indexes.
Note the last parameter, SAMPLED. This parameter determines the scan level when collecting the index statistics. I usually use SAMPLED as most of the systems I work on are quite large but there are other options that get more or less detailed statistics depending on what you require. DEFAULT, NULL, LIMITED, DETAILED are the other options.
SELECT t.name AS TableName,i.name AS IndexName,
ROUND(avg_fragmentation_in_percent,2) AS avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ips
INNER JOIN sys.tables t on t.[object_id] = ips.[object_id]
INNER JOIN sys.indexes i ON (ips.object_id = i.object_id) AND (ips.index_id = i.index_id)
ORDER BY avg_fragmentation_in_percent DESC;Rebuild vs. Reorg
Once you have determined the level of fragmentation in your indexes you have two different options available in order to address the fragmentation. You can either REORGANIZE the index or REBUILD it. Guidelines from Microsoft suggest that if the level of fragmentation is < 10% then you should do nothing, 10% to 30% you should REORG and > 30% you should REBUILD. These numbers were chosen based on the time it takes to do each operation.
A REBUILD creates the new index from scratch where as a REORG just works to remove the fragmentation. An index with little fragmentation can be REORGed rather quickly so once the fragmentation is above 30% the index can usually be rebuilt in the same amount of time it would take to REORG so it makes sense to just REBUILD it. There are some other things to consider when deciding which option to choose. These are listed below.
| REBUILD | REORG |
|---|---|
| requires enough free space to create new index | works in place so no extra space required |
| if interrupted need to restart from scratch | can restart from where operation was interrupted |
| can be done online or offline | always done online |
| generates more trn log than reorg | only generates trn log for blocks that were reorged |
| statistics are updated automatically | statistics update must be done manually |
More Information on SQL Server Maintenance
- Index Fragmentation Report in SQL Server
- SQL Server Index Fragmentation Overview
- Fixing Index Fragmentation in SQL Server 2005/2008
- Selectively Rebuild Indexes with SQL Server Maintenance Plans
- Script to Manage SQL Server Rebuilds and Reorganize for Index Fragmentation
- Custom SQL Server Index Defrag and Rebuild Procedures
- Rebuilding SQL Server Indexes Using the Online Option
Next Steps
- Read more tips on SQL Server indexing

Ben Snaidero has been a Database Administrator for just over 10 years. Starting out working mainly with Oracle he got into SQL Server in 2005 and has worked primarily with SQL Server for the last 3 years. His main focus with both Oracle and SQL Server is in the area of performance tuning.
- MSSQLTips Awards: Achiever (75+ tips) – 2018 | Author of the Year Contender – 2016-2017


Nice …simply explained everything,
Keep posting. All the best.