By: Marios Philippopoulos | Comments | Related: > SQL Server 2016
Problem
I have recently heard that the upcoming release of SQL Server 2016 will bring about several important enhancements for columnstore indexes. I want to learn more about these changes, so as to leverage them to achieve improved application performance and scalability.
Solution
SQL Server 2016 promises to be a revolutionary product with new features addressing database security, availability, performance and analytics. Among these enhancements are those applying to columnstore indexes. In this series of tips I will be exploring these enhancements, starting with today's tip on the new/altered system views for disk-based tables. (Metadata for memory-optimized tables will be the subject of a future tip).
According to the Columnstore Indexes Versioned Feature Summary these are the new/altered system views for columnstore indexes:
- sys.column_store_row_groups
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
- sys.internal_partitions
- sys.dm_db_index_operational_stats
- sys.dm_db_index_physical_stats
Concepts
Before continuing, a brief description of key concepts is needed. For a detailed introduction of the concepts about columnstore indexes see the Columnstore Indexes Guide. Also white paper "Enhancements to SQL Server Column Stores" contains an excellent figure for helping better visualize the columnstore structure.
- Columnstore: a structure, first introduced in SQL Server 2012, in which data is stored in columnar format, as opposed to a heap or b-tree. The columnar structure can provide a significant performance benefit, in terms of IO and memory utilization, to data-warehouse-type queries that access small subsets of columns in large tables. Data in a columnstore index is compressed by default, further boosting performance.
- Rowstore: the traditional b-tree/heap index structure. I will be using rowstore or b-tree interchangeably to refer to this structure from now onwards.
- Rowgroup: a group of rows that are compressed together into a columnstore. A rowgroup contains the same number of rows from every column defined in the columnstore index. Depending on the uniqueness of data in each of the columns, a rowgroup can contain a number of rows between 102,400 and 1,048,576.
- Segment: data from a single column compressed individually and combined with the segments of the other columns in the index as part of a rowgroup. Each segment in a rowgroup contains the same number of rows.
- Dictionary: an auxiliary structure used to encode the data in a column ahead of its compression into a column segment. Dictionaries encode only some data types, so it is not necessary that each column segment in an index come with a dictionary attached to it. Dictionaries and column segments are physically converted to individual BLOB (Binary-Large-Object) structures by the storage engine.
- Deltastore: a b-tree structure for storing data whose volume is not yet large enough (less than 102,400 rows) to compress into a columnstore. Once a deltastore reaches the maximum number of rows for a rowgroup (1,048,576), it cannot accept any more data and switches from state OPEN to CLOSED.
- Delete Bitmap: a b-tree structure used for storing the row IDs of deleted rows in the columnstore index. Data from deltastores and delete bitmaps are transparently merged together with compressed data during scan operations of the columnstore index.
- Tuple Mover: a background process that periodically checks for rowgroups in the CLOSED state and compresses them into columnstore format.
Setup
Here I am using a copy of the AdventureWorksDW2014 database upgraded to compatibility level 130 (SQL Server 2016). My SQL Server instance is on version SQL Server 2016 RC3. To better emulate the size of real-world data warehouses, two tables, [FactInternetSales] and [FactProductInventory], are expanded to several times their initial size and three new indexes (two columnstore, one rowstore) are created. In addition, a small workload of DELETE, UPDATE and SELECT statements is run against the two tables. Here is the full setup script.
The new indexes are created as follows (inside the setup script):
----------- --Script 1: ----------- USE [AdventureWorksDW2014]; GO --http://www.sqlskills.com/blogs/joe/row-and-batch-execution-modes-and-columnstore-indexes/ CREATE NONCLUSTERED COLUMNSTORE INDEX [NCI_FactInternetSales] ON [dbo].[FactInternetSales] ( [OrderDateKey], [CustomerKey], [SalesAmount] ) WITH (DROP_EXISTING = OFF) ON [PRIMARY]; GO -- Creating a clustered index with PAGE data compression CREATE CLUSTERED INDEX [CCI_FactProductInventory] ON [dbo].[FactProductInventory] ( [ProductKey] ASC, [DateKey] ASC ) WITH (DATA_COMPRESSION = PAGE) ON [PRIMARY]; GO --Create it again as columnstore with MAXDOP 1 to get better sorting of the data: CREATE CLUSTERED COLUMNSTORE INDEX [CCI_FactProductInventory] ON [dbo].[FactProductInventory] WITH (DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE, MAXDOP = 1); GO CREATE NONCLUSTERED INDEX [NI_FactProductInventory] ON [dbo].[FactProductInventory] ( [UnitsBalance] ); GO
On completion of "Script 1" we end up with the following indexes (obtained by using Kimberly Tripp's custom stored procedure sp_SQLskills_SQL2012_helpindex, which, in its current version, does not identify clustered columnstore indexes - notice the value for the Index Description of the clustered columnstore index, CCI_FactProductInventory):
| Table | Index Name | Index Description |
|---|---|---|
| FactInternetSales | [PK_FactInternetSales_SalesOrderNumber_ SalesOrderLineNumber] | clustered, unique, primary key located on PRIMARY |
| FactInternetSales | [NCI_FactInternetSales] | nonclustered columnstore located on PRIMARY |
| FactProductInventory | [CCI_FactProductInventory] | new index type located on PRIMARY |
| FactProductInventory | [NI_FactProductInventory] | nonclustered located on PRIMARY |
In "Script 1" notice that I first create a rowstore clustered index on table FactProductInventory. I then recreate it as a clustered columnstore index with MAXDOP 1, in order to preserve the original sorting of the data. For more details on this technique see Niko Neugebauer's excellent analysis here.
Results and Analysis of SQL Server Columnstore Indexes of Disk Based Tables
sys.column_store_row_groups
Changes to this system view are solely with regards to memory-optimized tables. See Niko's comments here.
Although there is nothing new with regards to disk-based tables, it is still instructive to examine this view for the sake of the later discussion. "Script 2" returns information on the columnstore row groups in the [AdventureWorksDW2014] database:
----------- --Script 2: ----------- USE [AdventureWorksDW2014]; GO SELECT OBJECT_NAME(rg.[object_id]) AS [Table], i.[name] AS [Index], rg.[row_group_id], rg.[delta_store_hobt_id], rg.[state_description], rg.[total_rows], rg.[deleted_rows], rg.[size_in_bytes] FROM sys.column_store_row_groups AS rg LEFT OUTER JOIN sys.indexes AS i ON rg.[object_id] = i.[object_id] AND rg.[index_id] =i.[index_id] ORDER BY [Table], [Index], rg.[row_group_id]; GO
Results (after a few minutes):
![returns information on the columnstore row groups in the [AdventureWorksDW2014] database](/tipimages2/4280_column_store_row_groups.GIF)
There are 17 row groups, 4 for [FactInternetSales] and 13 for [FactProductInventory]. 2 row groups are in an OPEN state, meaning they are still available for accepting more rows, should more data be added to the tables. The open row groups come with a non-NULL delta_store_hobt_id, identifying the deltastore structure holding the data. The rest of the row groups are in a COMPRESSED state. Some of the compressed row groups contain the maximum value of rows (1,048,576 under the total_rows column), while others contain a lower number.
It is interesting that none of the deletes/updates on table [FactInternetSales] (setup script) shows up under the deleted_rows column for non-clustered index [NCI_FactInternetSales]. (Updates in a columnstore index are implemented, under the covers, as an equal number of deletes and inserts). There are, on the other hand, non-zero values under deleted_rows for some row groups of clustered index [CCI_FactProductInventory]. However, the total number of deleted rows shown in the results (about 60,000) is less than the numbers of rows affected in the setup script (94,315 rows deleted and 426,128 rows updated). This is because during execution of the DELETEs/UPDATEs of the [FactProductInventory] table in the setup script there were row-group re-arrangements with two new row groups created (17 and 18) and one row group removed (11). The final number of deleted rows shown is the end result of these intermediate changes.
sys.dm_column_store_object_pool
Provides information on memory-pool usage for columnstore-index structures.
"Script 3" returns information on the current memory use of individual column segments (and associated structures) in the AdventureWorksDW2014 database:
----------- --Script 3: ----------- USE [AdventureWorksDW2014]; GO SELECT OBJECT_NAME(p.[object_id]) AS [Table], i.[name] AS [Index Name], c.[name] AS [Column Name], p.[column_id], p.[row_group_id], p.[object_type_desc], p.[access_count], p.[memory_used_in_bytes], p.[object_load_time] FROM sys.dm_column_store_object_pool p LEFT OUTER JOIN sys.index_columns ic ON ic.[index_column_id] = p.[column_id] AND ic.[index_id] = p.[index_id] AND ic.[object_id] = p.[object_id] LEFT OUTER JOIN sys.columns c ON ic.[object_id] = c.[object_id] AND ic.[column_id] = c.[column_id] LEFT OUTER JOIN sys.indexes i ON i.[object_id] = p.[object_id] AND i.[index_id] = p.[index_id] ORDER BY p.[memory_used_in_bytes] DESC; GO
Here is a subset of the results showing the top memory consumers (a total of 99 rows returned - this output will vary widely depending on the level of activity preceding the time of capture):
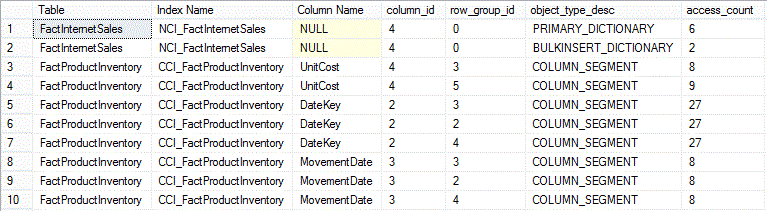
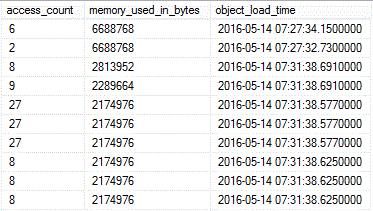
Two dictionaries for the [SalesOrderNumber] column (column_id = 4) of table [FactInternetSales] are at the top, followed mostly by column segments from table [FactProductInventory]. Column name is NULL for the first two records; that is because [SalesOrderNumber] is not part of the definition of index [NCI_FactInternetSales] (see "Script 1"), but is included as a key of clustered index [PK_FactInternetSales_SalesOrderNumber_SalesOrderLineNumber]. Also shown is the number of times a particular object type was accessed for reads/writes (access_count) and the time the object was loaded into memory (object_load_time).
In all there are five distinct object types returned (see also sys.dm_column_store_object_pool (Transact-SQL)):
COLUMN_SEGMENT: the columnstore structure corresponding to a specific column and rowgroup as we defined it earlier.
PRIMARY_DICTIONARY: a dictionary used to encode all segments of a particular column.
SECONDARY_DICTIONARY: a dictionary used to encode a subset of segments of a particular column.
BULKINSERT_DICTIONARY: a dictionary used to map a column segment to its primary dictionary, if this column segment was part of a rowgroup loaded through a bulk-insert or tuple-mover operation.
DELETE_BITMAP: used to track deleted rows in the column segment.
sys.dm_db_column_store_row_group_operational_stats
Returns information on row-group usage statistics and locking for reads/writes (see sys.dm_db_column_store_row_group_operational_stats (Transact-SQL)).
"Script 4" returns operational statistics on database AdventureWorksDW2014 after first running a couple of SELECT statements against the FactInternerSales and FactProductInventory tables:
----------- --Script 4: ----------- USE [AdventureWorksDW2014]; GO SELECT * FROM [dbo].[FactInternetSales] WHERE [OrderDateKey] = 20131227 AND [CustomerKey] = 19112 AND [SalesAmount] = 1700.99; GO 10 SELECT TOP 10 * FROM [dbo].[FactProductInventory] ORDER BY [ProductKey] ASC, [DateKey] ASC; GO SELECT OBJECT_NAME(os.[object_id]) AS [Table] , i.[name] AS [Index] , os.[row_group_id] , os.[index_scan_count] , os.[scan_count] , os.[delete_buffer_scan_count] , os.[row_group_lock_count] , os.[row_group_lock_wait_count] , os.[row_group_lock_wait_in_ms] FROM sys.dm_db_column_store_row_group_operational_stats AS os LEFT OUTER JOIN sys.indexes AS i ON i.[index_id] = os.[index_id] AND i.[object_id] = os.[object_id] ORDER BY [Table] , [Index] , os.[row_group_id]; GO
Results:
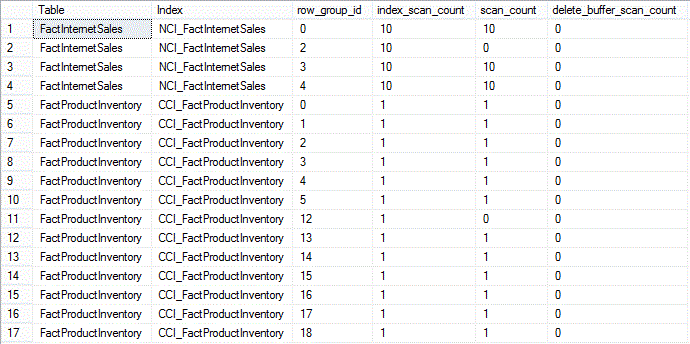
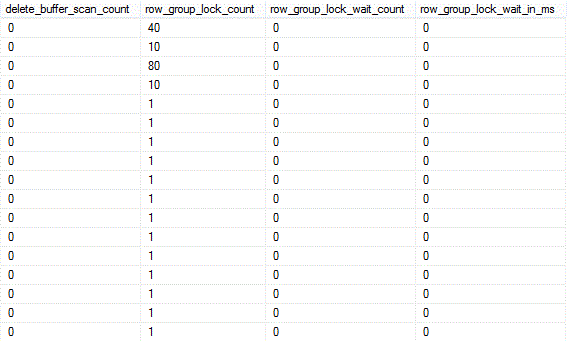
We get index_scan_count values consistent with the number of times a SELECT statement was executed against each table (10 times on FactInternetSales, 1 time on FactProductInventory). Also the scan_count values are 0 for the 2 delta stores (row_group_id 2 and 12 for NCI_FactInternetSales and CCI_FactProductInventory, respectively). Many of the other values are 0, due to the small workload.
sys.dm_db_column_store_row_group_physical_stats
Extends the sys.column_store_row_groups catalog view and is a good source of information on the extent of fragmentation of columnstore indexes (see sys.dm_db_column_store_row_group_physical_stats (Transact-SQL)). The data returned by this view can serve as a first step of maintenance procedures, in a similar fashion as sys.dm_db_index_physical_stats is used for b-tree/heap structures.
----------- --Script 5: ----------- USE [AdventureWorksDW2014]; GO --https://technet.microsoft.com/nl-be/dn832030 SELECT OBJECT_NAME(i.[object_id]) AS [Table], i.[name] AS [Index], ps.[row_group_id], ps.[delta_store_hobt_id], ps.[state_desc], ps.[total_rows], ps.[deleted_rows], ps.[size_in_bytes], ps.[trim_reason_desc], ps.[transition_to_compressed_state_desc], ps.[has_vertipaq_optimization], ps.[generation], ps.[created_time], ps.[closed_time], 100 * ( ISNULL ( ps.[deleted_rows], 0 ) ) / total_rows AS 'Fragmentation' FROM sys.indexes AS i INNER JOIN sys.dm_db_column_store_row_group_physical_stats AS ps ON i.[object_id] = ps.[object_id] AND i.index_id = ps.index_id ORDER BY [Table], [Index], ps.[row_group_id]; GO
Results (broken into 2 screens from left to right):
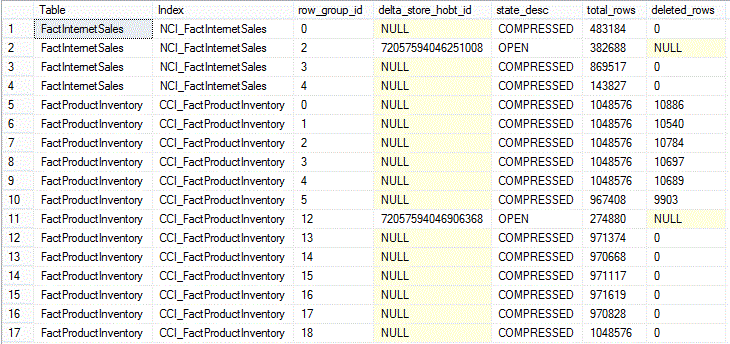

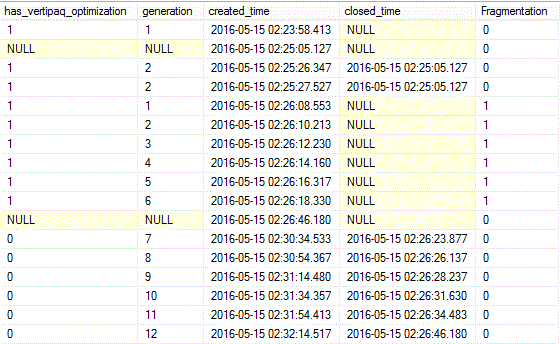
In addition to columns also found in sys.column_store_row_groups, several new ones appear here (for a complete list and descriptions of columns and their possible values see sys.dm_db_column_store_row_group_physical_stats (Transact-SQL)):
trim_reason_desc: if the row group in question did not reach the maximum size of 1,048,576 rows, this column provides the reason why. In our example, values for this column are one of the following:
-
NO_TRIM: row group achieved the maximum number of rows (1,048,576).
-
RESIDUAL_ROW_GROUP: number of rows in this row group have not reached the maximum value (1,048,576), because there simply were not enough rows left over at the end of a bulk load.
-
DICTIONARY_SIZE: the size of the dictionary for this particular row group prevented the number of rows from reaching the maximum.
-
REORG: some reorganization took place during a bulk load operation, whereby some row groups were deleted or merged with other row groups.
transition_to_compressed_state_desc: the process through which a row group arrived at the compressed state. Values we see in this example are:
-
INDEX_BUILD: row group was compressed by an index create or rebuild operation. In our case these are row groups containing data that existed prior to creation of the columnstore indexes in the setup script.
-
TUPLE_MOVER: row group transitioned from the OPEN to the CLOSED state (in which it could accept no more rows), and was subsequently compressed asynchronously by this background process.
-
NULL: row group is not compressed. It is still in the OPEN state, and is therefore able to accept more rows.
has_vertipaq_optimization: Vertipaq is the name of the underlying technology responsible for achieving the highly efficient compression seen in columnstore indexes. Possible values for this column are 0, 1 and NULL:
-
0: vertipaq optimization skipped. We see a number of row groups with this value in the clustered columnstore index, CCI_FactProductInventory: row group ids 13 to 18. These row groups all transitioned to the compressed state via the TUPLE_MOVER.
-
1: vertipaq optimization implemented. The rest of the compressed row groups have this value. For the clustered index, CCI_FactProductInventory, these are mostly row groups that have achieved the maximum number of rows allowed (1,048,576), and for which the transition to a compressed state occurred as a result of an INDEX_BUILD operation.
-
NULL: row groups still in the OPEN state.
generation: a number signifying the sequence in which a row group was compressed, relative to other row groups.
created_time: the time at which a row group was created
closed_time: the time at which a row group switched from the OPEN to the CLOSED state, as a result of the TUPLE_MOVER process.
Fragmentation: a computed value derived from the relative ratio of deleted versus total rows for a particular row group.
sys.internal_partitions
Returns the internal supporting rowset structures within each columnstore index. These entities are structured as a b-tree with an associated hobt_id.
Script (adapted from Columnstore Indexes – part 56 (“New DMV’s in SQL Server 2016”)):
----------- --Script 6: ----------- USE [AdventureWorksDW2014]; GO SELECT OBJECT_NAME(p.[object_id]) AS [Table], i.[name] as [Index], p.[hobt_id], p.[internal_object_type_desc], p.[row_group_id], p.[rows], p.[data_compression_desc] FROM sys.internal_partitions AS p INNER JOIN sys.indexes AS i ON p.[object_id] = i.[object_id] AND p.[index_id] = i.[index_id] ORDER BY [Table], [Index], p.[row_group_id]; GO
Results:

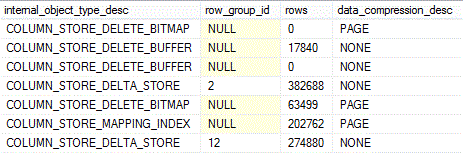
There are 7 rowset structures returned here, with 4 on the nonclustered index, NCI_FactInternetSales, and 3 on the clustered index, CCI_FactProductInventory. Apart from table and index name, the rest of the columns returned are:
hobt_id: unique id of each b-tree (rowset) structure.
internal_object_type_desc: description of each object type; in our example the types returned are:
-
COLUMN_STORE_DELETE_BITMAP: tracks the rows marked as deleted in a columnstore index. These rows are still physically present and take up space in the columnstore. They can be removed only by an explicit command to reorganize or rebuild the columnstore index.
-
COLUMN_STORE_DELETE_BUFFER: maintains deletes in a nonclustered columnstore index. This structure tracks deletes in the nonclustered columnstore that occur as a result of deletes in the underlying rowstore table. When the number of deleted rows in the rowstore table exceeds 1,048,576, the corresponding rows in the delete buffer are merged into the delete bitmap by the TUPLE_MOVER or an explicit REORGANIZE command. Note that the delete bitmap in our example is page-compressed (record 1 in the above figure, data_compression_desc column), whereas the delete buffer is not (record 2); so the eventual transfer of rows from delete buffer to delete bitmap results in more optimized data storage. The sum of rows in delete bitmap and delete buffer represent the total number of rows marked for deletion in the nonclustered columnstore index.
-
COLUMN_STORE_DELTA_STORE: contains rows in an open row group; these are rows that have not yet been compressed and converted into a columnstore.
-
COLUMN_STORE_MAPPING_INDEX: used when a clustered columnstore index is accompanied by a non-clustered rowstore/b-tree index on the same table. It maps index keys of the nonclustered index to the appropriate rowgroup and rowID of the clustered index. This tracking is triggered only after conversion of a deltastore rowgroup to a columnstore or the merging of 2 or more rowgroups into a larger rowgroup. In our case this structure (row 6 in the above results) is used to map the non-clustered b-tree index (NI_FactProductInventory - see "Script 1") to the clustered columnstore index CCI_FactProductInventory.
row_group_id: the id of a deltastore row group. Apart from deltastores, none of the other object types form their own row groups (row_group_id NULL).
rows: number of rows contained in each internal partition. We see non-zero values for the COLUMN_STORE_DELETE_BUFFER and COLUMN_STORE_DELTA_STORE of the nonclustered columnstore NCI_FactInternetSales and for all 3 internal partitions of the clustered columnstore CCI_FactProductInventory.
data_compression_desc: type of data compression for each internal partition. Since these are all rowstore structures, the type of compression can be ROW, PAGE or NONE. In our example we see that the delete bitmaps and the mapping index have been page-compressed by default, whereas the other structures are not compressed (compression NONE).
For more information see sys.internal_partitions (Transact-SQL).
sys.dm_db_index_operational_stats
Returns usage statistics and I/O-related activity (locks, latches) for each partition of a table or index in a database. This is not a new DMV in SQL Server 2016, but has been extended to cover columnstore-related structures of the rowstore variety.
In "Script 7" I run a small workload on the database. I then query sys.dm_db_index_operational_stats joined with sys.indexes and sys.internal_partitions to obtain information on the I/O and locking activity of indexes in tables FactInternetSales and FactProductInventory:
-----------
--Script 7:
-----------
USE [AdventureWorksDW2014];
GO
SELECT * FROM [dbo].[FactInternetSales]
WHERE [OrderDateKey] = 20131227
AND [CustomerKey] = 19112
AND [SalesAmount] = 1700.99;
SELECT TOP 10 * FROM [dbo].[FactProductInventory]
ORDER BY [ProductKey] ASC, [DateKey] ASC;
GO
--Search for rows already deleted earlier:
SELECT TOP 50 * FROM [dbo].FactInternetSales
WHERE OrderDateKey < '20120101';
SELECT TOP 10 * FROM [dbo].[FactProductInventory]
WHERE [DateKey] < '19600101';
GO
SELECT
OBJECT_NAME(os.[object_id]) AS [Table],
i.[name] AS [Index],
i.[type_desc] AS [Index Type],
ip.[internal_object_type_desc],
os.[range_scan_count],
os.[singleton_lookup_count],
os.[page_lock_count],
os.[page_io_latch_wait_count],
os.[page_io_latch_wait_in_ms],
os.[tree_page_io_latch_wait_count],
os.[tree_page_io_latch_wait_in_ms]
FROM
sys.dm_db_index_operational_stats (DB_ID(), NULL, NULL, NULL)
AS os
INNER JOIN
sys.indexes AS i
ON
i.[index_id] = os.[index_id]
AND i.[object_id] = os.[object_id]
LEFT OUTER JOIN
sys.internal_partitions AS ip
ON
ip.[hobt_id] = os.[hobt_id]
AND ip.[index_id] = os.[index_id]
AND ip.[object_id] = os.[object_id]
AND ip.[partition_number] = os.[partition_number]
WHERE
OBJECT_NAME(os.[object_id]) IN
('FactInternetSales', 'FactProductInventory')
ORDER BY
[Table],
[Index],
ip.[row_group_id];
GO
Results (split into 2 screens from left to right):
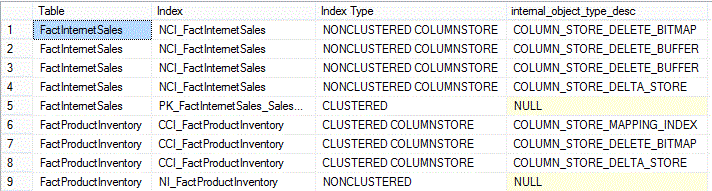
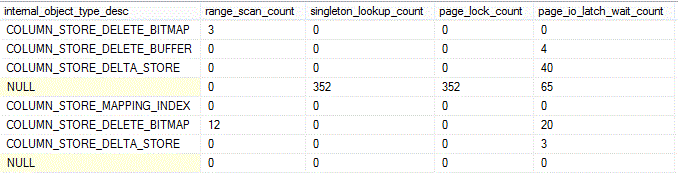

As expected, we get records on the b-tree clustered and nonclustered indexes: PK_FactInternetSales_SalesOrderNumber_SalesOrderLineNumber and NI_FactProductInventory. The rest of the results originate from the internal columnstore structures, built as a rowstore, that we saw earlier in the discussion on sys.internal_partitions: delete bitmap, delete buffer, delta store and mapping index.
sys.dm_db_index_physical_stats
Returns information on the size and fragmentation of indexes and heaps in a table, database or instance. In SQL Server 2016 2 new columns have been added, specifically for columnstores: column_store_delete_buffer_state and column_store_delete_buffer_state_desc. Another column, hobt_id, has been extended to account for internal columnstore structures that are built as rowstores.
"Script 8" returns fragmentation information and the state of the delete buffer for the b-tree structures associated with the 2 columnstore indexes:
-----------
--Script 8:
-----------
USE [AdventureWorksDW2014];
GO
SELECT
i.[name] AS [Index],
i.[type_desc] AS [Index Type],
ip.[internal_object_type_desc],
ip.[rows],
ps.[avg_fragmentation_in_percent],
ps.[columnstore_delete_buffer_state_desc]
FROM
sys.dm_db_index_physical_stats
(DB_ID(), NULL, NULL, NULL , 'LIMITED') AS ps
INNER JOIN
sys.indexes AS i
ON
i.[index_id] = ps.[index_id]
AND i.[object_id] = ps.[object_id]
LEFT OUTER JOIN
sys.internal_partitions AS ip
ON
ip.[hobt_id] = ps.[hobt_id]
AND ip.[index_id] = ps.[index_id]
AND ip.[object_id] = ps.[object_id]
AND ip.[partition_number] = ps.[partition_number]
WHERE
OBJECT_NAME(ps.[object_id]) IN
('FactInternetSales', 'FactProductInventory')
ORDER BY
OBJECT_NAME(ps.[object_id]),
[Index];
GO
Results:
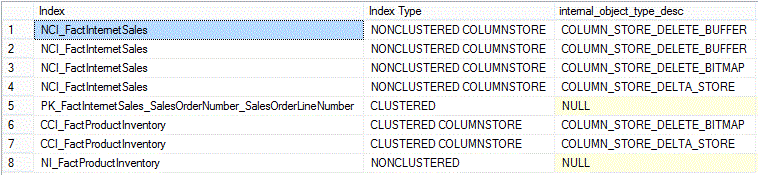
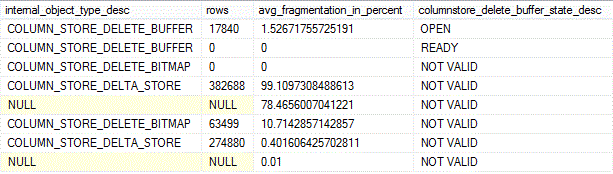
The delta store of the non-clustered columnstore index, NCI_FactInternetSales, is severely fragmented (avg_fragmentation_in_percent = 99%), followed by the b-tree clustered index of the same table, PK_FactInternetSales_SalesOrderNumber_SalesOrderLineNumber (78%). Also values of the columnstore_delete_buffer_state_desc are relevant only for the delete buffer of NCI_FactInternetSales (see above discussion on sys.internal_partitions), hence the value of "NOT VALID" for the rest of the records. Finally, the delete buffer with 17,840 rows is in an OPEN state (is currently in use), whereas the delete buffer with 0 rows is available (READY) but not in use yet.
Conclusion
In this tip I have gone through examples showing how the new/changed system views introduced in SQL Server 2016 can be used to analyze the internals and operational behavior of columnstore indexes of disk-based tables. I have barely scratched the surface and there are still many aspects in the results that I do not fully understand. But I hope I have given a flavor of what level of information is possible. The online documentation is still sketchy in places, and the product itself is still being updated before it reaches a point where it will be ready to be officially released later this year. So it is possible that some things will change by the final release, although I do not expect most of the information presented here to be impacted.
In subsequent tips I will be covering other columnstore-index enhancements in SQL Server 2016, starting with system views on memory-optimized tables.
Next Steps
- Apply the solution outlined in this tip to your environment to monitor columnstore indexes in SQL Server 2016.
- Review these related links to learn more about columnstore indexes:
- SQL Server 2016 Features in CTP2
- SQL 2016: Columnstore row group Merge policy and index maintenance improvements
- SQL Server Columnstore, B-Tree and Hybrid Index Performance Comparison for Data Warehouses
- SQL Server Column Store Index Performance
- Columnstore Indexes – part 56 (“New DMV’s in SQL Server 2016”)
- Columnstore – Niko Neugebauer
- Exploring Columnstore Index Metadata, Segment Distribution and Elimination Behaviors
- The Illusion of Updateable Clustered ColumnStore Indexes






About the author
 Marios Philippopoulos has been a SQL Server DBA for over 10 years. He is based in the Toronto area, Canada.
Marios Philippopoulos has been a SQL Server DBA for over 10 years. He is based in the Toronto area, Canada.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
