Problem
As we continue to discuss Microsoft Access in this series of tips it seemed important to revisit in more detail a tip I produced in 2008 on using Pass-Through Queries inside of Microsoft Access. Just what is a Pass-Through query? It’s a construct in Microsoft Access that allows you to code the query text in the language of the back-end relational database management system – be it SQL Server, Oracle, or the like. The query is then passed back to the RDBMS in its native language for execution; results being returned back to Access. For more background on the subject I suggest reviewing the original tip.
The purpose of this tip is to demonstrate what happens inside of SQL Server when it has to process a request formed natively in MS Access versus a pass-through query request received from the same MS Access application.
Solution
Access does a fair amount of load-intensive processes when passing requests along to a back-end RDBMS that is not integrated as Jet is with the Access product. In order to demonstrate I’ve created a sample database, rightly named mssqltips, then created and populated the following tables:
(
NAME = N’mssqltips’,
FILENAME = N’C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\mssqltips.mdf’,
SIZE = 20MB , MAXSIZE = UNLIMITED, FILEGROWTH = 10MB
)
LOG ON
(
NAME = N’mssqltips_log’,
FILENAME = N’C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\mssqltips_log.ldf’,
SIZE = 5MB , MAXSIZE = 50MB , FILEGROWTH = 10MB
GO
ALTER DATABASE [mssqltips] SET RECOVERY SIMPLEGO CREATE TABLE dbo.Customers (customer_id INT NOT NULL IDENTITY (1, 1),
customer_name VARCHAR(50) NOT NULL);
ALTER TABLE dbo.Customers ADD CONSTRAINT
pk_customers_customer_id PRIMARY KEY CLUSTERED
(
customer_id
)
ON [PRIMARY]
CREATE TABLE dbo.Orders (order_id INT NOT NULL IDENTITY (1, 1),
order_date datetime NOT NULL,
customer_id INT NOT NULL);
ALTER TABLE dbo.Orders ADD CONSTRAINT
pk_orders_order_id PRIMARY KEY CLUSTERED
(
order_id
)
ON [PRIMARY] INSERT INTO dbo.[Customers] ([customer_name])
VALUES ( ‘SQLCruise.com’
INSERT INTO dbo.[Customers] ([customer_name])
VALUES (‘Indie Label’
INSERT INTO dbo.[Customers] ([customer_name])
VALUES (‘Rose Street Advisors’
DECLARE @counter INT
SELECT @counter = 1
WHILE @counter < 1001
BEGIN
INSERT INTO dbo.[Orders] ([order_date], [customer_id])
VALUES (DATEADD(d, –1 * @counter, ’12/31/2009′), 1)
SELECT @counter = @counter + 1
CONTINUE
END
SELECT @counter = 1
WHILE @counter < 1001
BEGIN
INSERT INTO dbo.[Orders] ([order_date], [customer_id])
VALUES (DATEADD(d, –2 * @counter, ’12/31/2009′), 2)
SELECT @counter = @counter + 1
CONTINUE
ENDSELECT
@counter = 1
WHILE @counter < 1001
BEGIN
INSERT INTO dbo.[Orders] ([order_date], [customer_id])
VALUES (DATEADD(d, –3 * @counter, ’12/31/2009′), 3)
SELECT @counter = @counter + 1
CONTINUE
END
Next we’ll jump back-and-forth between MS SQL Server and MS Access to create identical queries and look at what occurs within the Query Engine in SQL Server to demonstrate the need to use Pass-Through queries when working with MS Access and a non-Jet data engine. The remainder of this tip will focus on the following query to identify all orders placed prior to January 1, 2009.
Transact-SQL Query and Native Execution Directly From Microsoft SQL Server Management Studio:
Below is the t/sql query we’ll be executing:
FROM dbo.Orders INNER JOIN dbo.Customers
ON [Orders].[customer_id] = [Customers].[customer_id]
WHERE dbo.Orders.order_date < ’01/01/2009′
When executed from within a new query window within SSMS we return 2333 results, using the execution plan displayed below:
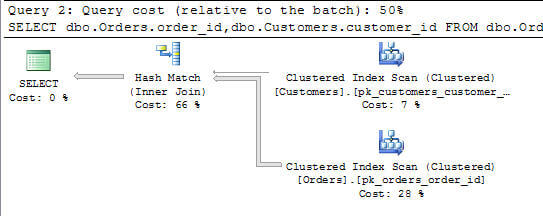
This is our benchmark – what we would expect to see if the query was formed correctly, and natively, in Transact SQL, executing from within the SQL Server Management tools. Please note that I did not create an index on the order_date column in this table, otherwise we would more-likely see an index scan or seek on that index. Since the amount of rows in this table (and database) are so low, I preferred to keep it simple. That being said, let’s look at what happens when we form the query text inside of MS Access. Using the process
FROM dbo_Orders INNER JOIN dbo_Customers ON dbo_Orders.customer_id=dbo_Customers.customer_id
WHERE (((dbo_Orders.order_date)<#1/1/2009#
It should be noted that for the sake of this demonstration, I’m running the DBCC FREEPROCCACHE; command between executions in order to remove any cached plan for this query from cache so as not to influence results. Otherwise, if the engine sees that a cached plan exists, it may chose to use that over creating a new one, hence impacting the comparison I hope to show here.
I drafted the statement inside of a new query tab inside of MS Access and executed it. Using SQL Server Profiler I captured the command as it was fulfilled inside of the SQL Server query engine. At first blush you’re probably wondering what all the fuss is about using pass-through queries:
FROM “dbo”.”Orders”, “dbo”.”Customers”
WHERE ((“dbo”.”Orders”.”order_date”< {d ‘2009-01-01’} )
AND (“dbo”.”Orders”.”customer_id”= “dbo”.”Customers”.”customer_id”) ) ;
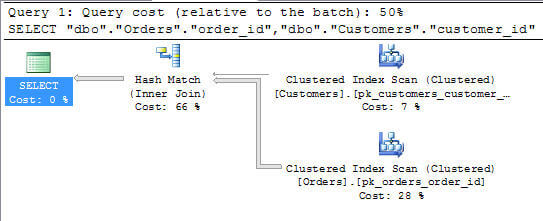
Sure, the translation does look a little complex and convoluted, but the execution plan is identical between the two. Matter-of-fact, when I didn’t run the DBCC FREEPROCCACHE; command between executions the query optimizer chose to reuse the plan.
If I proceed to drop in the T/SQL command I originally ran inside of SSMS, and do so inside of MS Access via a pass-through query I end up with the same execution plan as well:
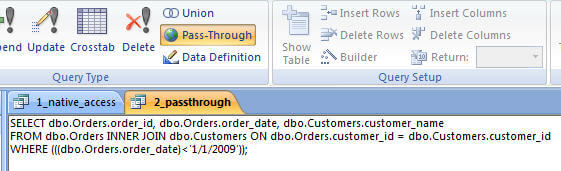
So, what is the problem? Why am I advocating using pass-through queries? Well it’s simply because of the work involved inside of SQL to get the native MS Access query request transformed into something it can work with. I mentioned SQL Server Profiler a few paragraphs ago. Let’s look at what occurs in SQL Server when the queries are executed.
First the native query directly from SSMS:
FROM dbo.Orders INNER JOIN dbo.Customers ON dbo.Orders.customer_id = dbo.Customers.customer_id
WHERE (((dbo.Orders.order_date)<‘1/1/2009’
Look what happens though when SQL Server receives a native MS Access query request however:
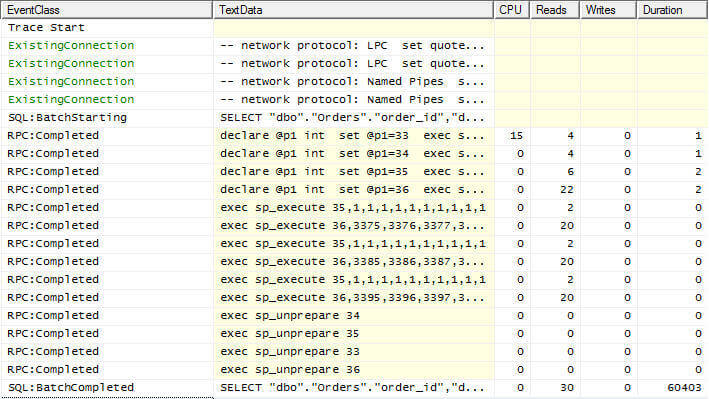
What is going on in those intermediate steps? Why is the duration so high? What is up with all the additional reads? Well, what is going on is that there is overhead associated with converting the query command from how it is received, to how it is processed by SQL Server.
The batch starts by processing the the converted SQL command that is a language understood by the SQL Server query engine:
FROM “dbo”.”Orders”, “dbo””Customers”
WHERE ((“dbo”.”Orders”.”order_date”< {d ‘2009-01-01’} )
AND (“dbo”.”Orders”.”customer_id”= “dbo”.”Customers”.”customer_id”) ) ;
Then a series of commands are run to prepare and execute the parametered query as it is received from MS Access. The first of the four identifies the lower limit for the result set’s sole predicate (WHERE order_date < 1/1/2009). That order_id is 3365. It is the first order_id that falls inside of the bounds of the WHERE clause.
SET @p1=33
EXEC sp_prepexec @p1 output,N’@P1 int’,N’SELECT “order_id”,”order_date”,”customer_id” FROM “dbo”.”Orders”
WHERE “order_id” = @P1′,3365
SELECT @p1
Then the execution really jumps the shark when you examine what SQL Server is attempting to do with perceived parameters for the customer_id. When the query is translated, the join criteria to satisfy the relationship between the dbo.Orders and dbo.Customers tables is moved into the WHERE clause and SQL infers that this is now also a parameter. The second command captured in the trace reflects the attempt to determine the lower bounds of the customer_id parameter:
SET @p1=34
EXEC sp_prepexec @p1 output,N’@P1 int’,N’SELECT “customer_id”,”customer_name” FROM “dbo”.”Customers”
WHERE “customer_id” = @P1′,1
SELECT @p1
Further overhead is incurred when processing all possible parameter values for both the customer_id and the order_id columns:
SET @p1=35
EXEC sp_prepexec @p1 output,N’@P1 int,@P2 int,@P3 int,@P4 int,@P5 int,@P6 int,@P7 int,@P8 int,@P9 int, @P10 int’,N’SELECT “customer_id”,”customer_name” FROM “dbo”.”Customers” WHERE “customer_id” = @P1 OR
“customer_id” = @P2 OR “customer_id” = @P3 OR “customer_id” = @P4 OR “customer_id” = @P5 OR “customer_id”
= @P6 OR “customer_id” = @P7 OR “customer_id” = @P8 OR “customer_id” = @P9 OR “customer_id” =
@P10′,1,1,1,1,1,1,1,1,1,1
SELECT @p1
DECLARE @p1 INT
SET @p1=36
EXEC sp_prepexec @p1 output,N’@P1 int,@P2 int,@P3 int,@P4 int,@P5 int,@P6 int,@P7 int,@P8 int,@P9 int,
@P10 int’,N’SELECT “order_id”,”order_date”,”customer_id” FROM “dbo”.”Orders” WHERE “order_id” = @P1
OR “order_id” = @P2 OR “order_id” = @P3 OR “order_id” = @P4 OR “order_id” = @P5 OR “order_id” = @P6
OR “order_id” = @P7 OR “order_id” = @P8 OR “order_id” = @P9 OR “order_id” =
@P10′,3365,3366,3367,3368,3369,3370,3371,3372,3373,3374
SELECT @p1
After SQL has prepared the statements needed to satisfy the request it then executes the prepared statements via the sp_execute calls:
EXEC sp_execute 36,3375,3376,3377,3378,3379,3380,3381,3382,3383,3384
EXEC sp_execute 35,1,1,1,1,1,1,1,1,1,1
EXEC sp_execute 36,3385,3386,3387,3388,3389,3390,3391,3392,3393,3394
EXEC sp_execute 35,1,1,1,1,1,1,1,1,1,1
EXEC sp_execute 36,3395,3396,3397,3398,3399,3400,3401,3402,3403,3404
Lastly, the prepared statements are freed via sp_unprepare:
EXEC sp_unprepare 35
EXEC sp_unprepare 33
EXEC sp_unprepare 36
If you’re to total-up the cumulative CPU, reads, and writes for both the native SQL Server command processing and the native MS Access processing the tale is telling enough:
| Native SQL | Native MS Access | |
| Total CPU | 0 | 15 |
| Total Reads | 36 | 132 |
| Total Writes | 0 | 0 |
What is interesting though is how Microsoft Access handles the transaction on it’s close. You may be wondering why the duration is so high in comparison between the two alternative methods of satisfying the query. 60,403 milliseconds for a Native MS Access execution in comparison to only 538 for SQL Server to process the same (essentially) command from SSMS. This is because I left the Microsoft Access query window displayed as a Datasheet view after the query results were returned for a total of one minute (human error accounts for the additional 403 milliseconds.) Yes, MS Access will hold a transaction open until you cease reviewing the returned data rows. It was not until I switched to SQL view in the query window that the transaction was closed inside of SQL Server. This is one of the key complaints SQL Server DBAs have with users hitting SQL via MS Access.
So what happens under the covers when we process the command as a pass-through query request from MS Access? Thing are much simpler, though there still is that issue with the open transaction that is consistent with how MS Access handes connections to non-native RDMBSs:

What you’ll observe is that all the intermediate mess of identifying true (and implied) parameters is avoided as SQL is receiving commands it understands and processing them accordingly. The only overhead occurred is due to how MS Access handles the open recordset issue. We’ll examine that topic in the next tip in this series. So why do I advocate the use of pass-through queries? Because it reduces overhead in the manifestation of CPU and I/O on the SQL Server instance. Any implicit conversion is removed from the hops between platforms. So if you must use MS Access please do so with the understanding that you should always speak in the language that the database platform hosting the data can understand.
Next Steps
- More tips from the author are available via this link.
- Review the original tip on Pass Through Queries.
- Learn more about linked tables in MS Access at MSSQLTips.com
- Additional introductory tips on SQL Server from MSSQLTips.com are available here
- The first tip in this series is available here
- Stay tuned for more tips in this series on SQL Server and Microsoft Access.

Tim Ford is a Senior Database Administrator with MindBody in San Luis Obispo, California and is in the process of relocating west to the Pacific Northwest from Michigan. Since 2010 he’s produced Microsoft Data Platform training events branded as SQL Cruise from Alaska to the Caribbean and the Mediterranean at Tech Outbound, an events company specializing in technical training in unconventional locations. His SQL Cruise events take place on cruise ships in the Caribbean, Alaska, and the Mediterranean. Tim also is the Executive VP of Marketing for PASS, the global association for Microsoft data professionals. He also is a contributing author for itprotoday. Tim loves helping people find their true potential through education and building networks between Thought Leaders in various fields and those who are just starting on their careers or struggling to find their footing in established careers. If you’re looking for this sort of experience then check out the next SQL Cruise event taking place this August in Seattle.
- MSSQLTips Awards: Acheiver (75+ tips) – 2010