Problem
Prototype development should be a regular exercise for most ETL projects before starting the actual solution development. Some of the challenges that ETL prototypes face are:
1) Insufficient load testing: Projects are not able to test a prototype sufficiently due to lack of sufficient data and therefore the prototype is tested with just a few records. Issues then only get discovered when the actual logic reaches the phase of testing with a volume of real data.
2) Inability to reuse package: A prototype might have been developed close to the actual requirement and might not be considered as a template for future projects. Since the source metadata may turn out to be different than what was used for the prototype development, it does not remain a feasible choice for reuse. Due to possible changes in the source schema, there is a greater chance that the entire logic flow would break due to changes in lineage IDs.
In this tip we will develop a design that will address these two challenges.
Solution
In this solution, we will look at how to solve both of the issues listed above.
1) Generating Test Data
First, we need to generate data that would allow us to test records in volume. The data used in most Data Flows are text or numeric data. For the prototype, we need this generated data to take the place of the actual source data since the source data may not be ready during prototype development.
Fortunately, we do not need to develop any logic for this generated data. There is a component, Konesans Data Generator Source Adapter which is freeware (to the best of my knowledge) available from SQLIS.com and can be downloaded from here. Download and install this component, installation instructions are available on the download page.
This component has a very simple editor, it’s very easy to configure and needs no explanation.
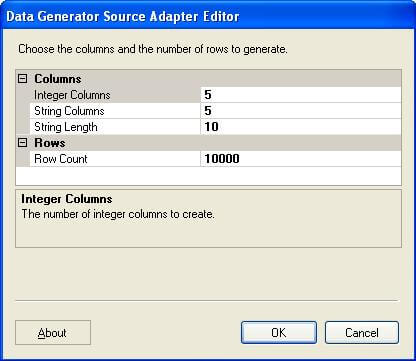
When the package is executed, this component generates rows specified in the Row Count property. One thing that needs to be kept in mind is that it generates different values for integer columns, but it might generate the same values for all string columns. In this case a script transform could be used to make the column values different based on any suitable logic.
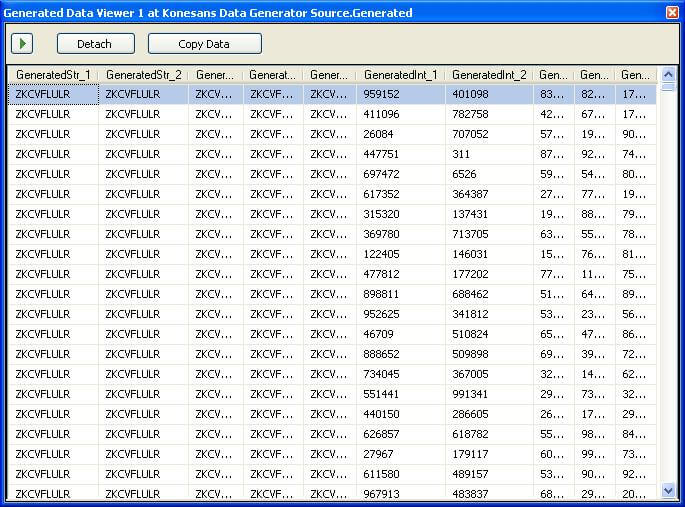
Let’s start to develop the prototype design, as we have the solution to the first part of the problem. I take it for granted the reader has installed this component and added it to the BIDS toolbox.
1) Create a new SSIS Project. Add a new package and add a Data Flow Task to the package.
2) Edit the Data Flow and add a Data Generator task to the package and configure it as shown in above screenshot.
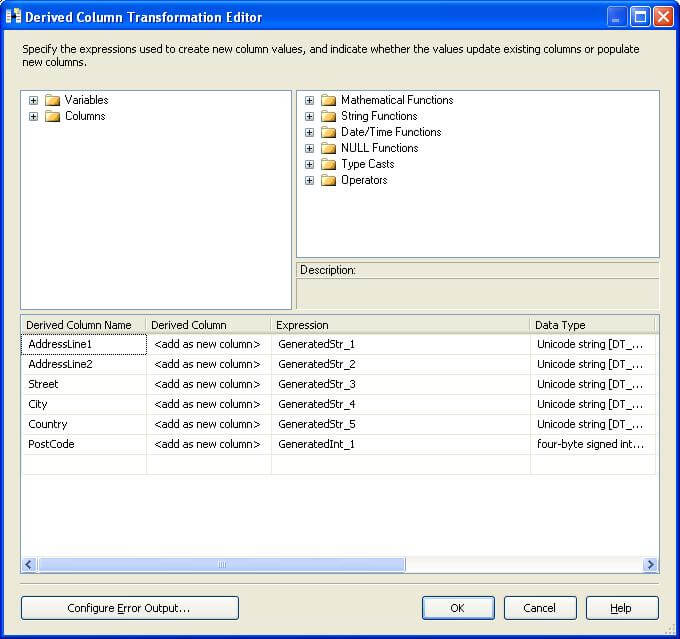
3) Add a derived column transformation and configure it as shown in the below screenshot. We will come back to why we are doing this shortly.
4) Add a multicast transformation, as we are considering this as the boundary from which multiple transforms can fetch data.
5) Add a conditional split transformation and configure a split with the condition of “PostCode > 200000” and name it Part I.
6) Add another multicast transformation as a placeholder for the destination.
After following the above steps, your package should look like the below screenshot. If you execute the package, data will be generated by the data generator component, and it would flow until the last transform.
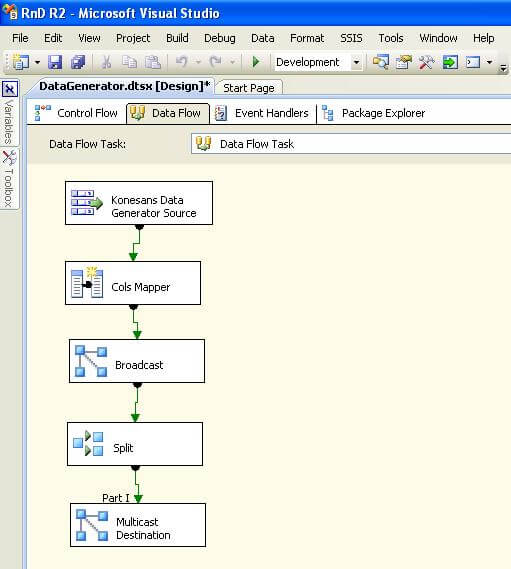
Our first challenge is solved we have a volume of generated data.
2) Ability to Reuse
To simulate our next challenge, say that we now have source data available in SQL Server and we want to use this data instead of the data generator. Remove the data generator task and add an OLE DB Source Adapter. Configure it to read some source columns of the same name and data type. By doing this it will break all the transforms below in the flow, as the lineage IDs of all the fields would change. This is the reason we have placed an interface (Derived Columns Task) that insulates the transforms from the changes to the metadata from the source.
When you add the OLE DB Adapter in place of the data generator component, the derived column transformations will break as shown in the below screenshot.
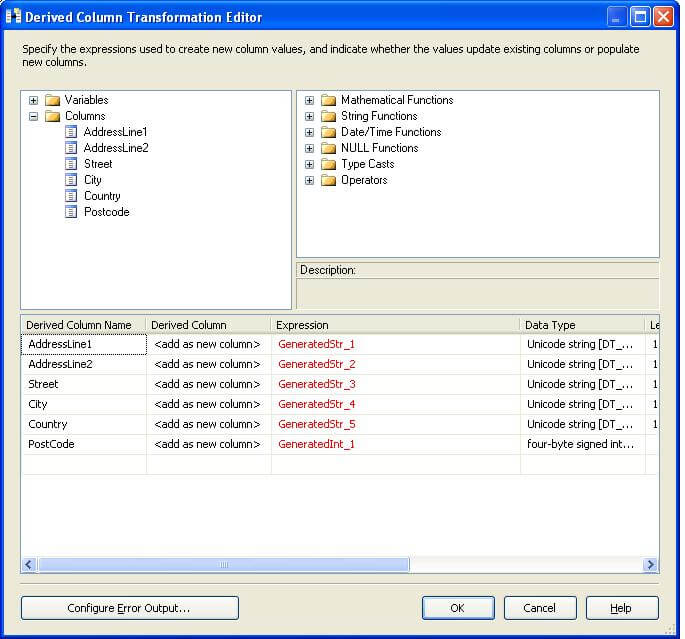
Fix the errors as shown in the below screenshot by mapping columns from the source to the derived columns we created earlier.

After fixing these errors in the derived column transformation, there should be no issue in the transformations below this task. By making a change at this mapping layer, we can reuse the existing package to a considerable extent, thus facilitating package development before the source becomes available.
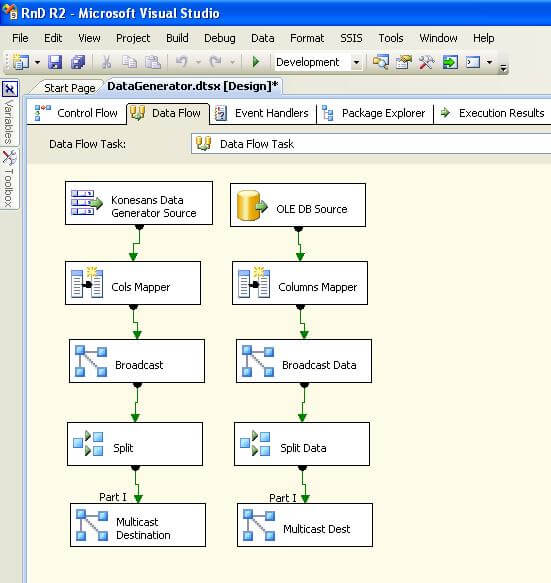
By implementing the above design approach, we solve both challenges for SSIS prototype development.
Next Steps
- Implement this design in your existing package which might be exposed to the risk of change in lineage IDs due to a change in your data source
- Test your existing packages with sufficient data by implementing the data generator component

Siddharth has more than 14 years of experience in the IT Industry, with more than a decade of experience in Business Intelligence and Analytics, for clients banking, logistics, government, Media Entertainment, products, life sciences and other domains. He has been a lead architect for a portfolio of 40+ apps, containing apps in web, mobile, BI, Analytics, data warehousing, reporting, collaboration, CMS, NoSQL and other technologies. He has several certifications and is a published author for online and print-media publications, as well as the MSDN Library.
In his present role, he remains responsible for architecture design, technology stack selection, infrastructure design, 3rd party products evaluation and procurement, and performance engineering. These applications use technologies like Elasticsearch / Lucene, MongoDB, SharePoint 2013 and 2010, jQuery-based framework like Highcharts and GoJS, SQL Server and the Microsoft Business Intelligence stack (SSIS, SSAS, SSRS, MDX, PowerPivot, PowerView), jQueryMobile, Bootstrap, iOS xCode framework, and many others.
- MSSQLTips Awards: Champion (100+ tips) – 2018 | Author of the Year – 2017 | Author Contender – 2016, 2018-2019

