By: Siddharth Mehta | Comments (3) | Related: 1 | 2 | 3 | 4 | > Analysis Services Measure Groups
Problem
In SQL Server Analysis Services (SSAS), each measure group by default has at least one partition. When a cube is created, this partition would not have any aggregation schemes defined, so these partitions are not optimized for performance. As you know, aggregations are pre-calculated sets of data which improve query response time and calculations during query evaluation. In this tip we wil learn how to design aggregations for a partition and optimize it for performance.
Solution
The Aggregation Design Wizard in SSAS is the easiest way to design an aggregation for a partition. For the purpose of this tip, we would use the project that we have developed using the SSAS Tutorial. From this tutorial, we already have a SSAS Project, a Cube and two measure groups. Based on these objects, follow the steps below to create an aggregation design.
Step 1: Open the SSAS tutorial project in BIDS, open the cube and aggregation tab. Select any measure group and you will see that an aggregation design has not been applied to the partition. Right-click on the "Unassigned aggregation design" partition and you would find the "Design Aggregations" option listed in the right-click menu. Selecting this option will invoke the aggregation design wizard for the selected partition.
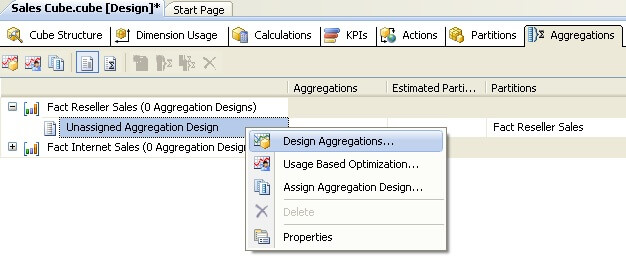
Step 2: On the first step of the wizard, you will find options to review the aggregation usage. Here all the cube dimensions will be listed along with all of the attributes. You can choose whether you want to design full aggregations, no aggregations, default or unrestricted mode. You can learn more about these modes here.
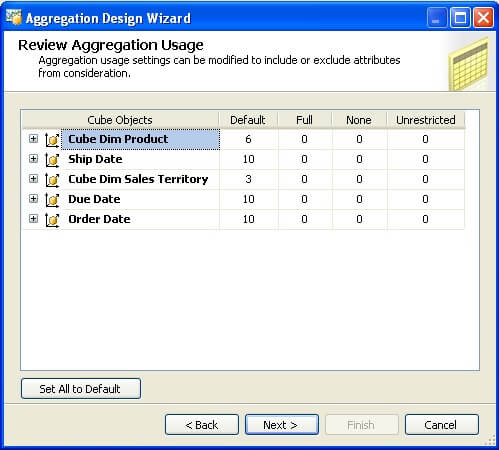
Step 3: On the next page of the wizard, you have the option to specify the number of rows in the partition, as well as member counts for each attribute. An easier way to get all of these counts is by clicking on the count button which will retrieve all the counts for you.
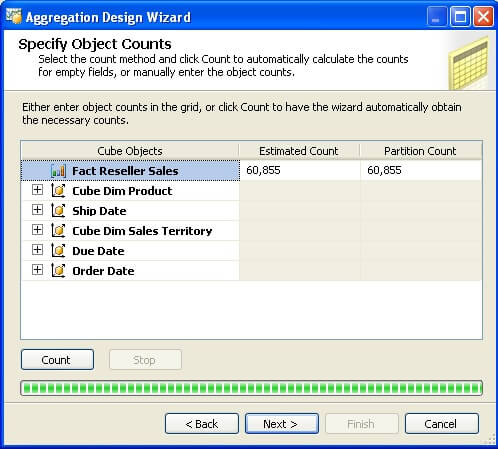
Step 4: On the next page of the wizard, you have the option to specify the volume of aggregations that you intend to create. There are three different options, and the fourth one is not a design aggregation at all. The other three options are to design aggregations until the storage space required to design the aggregation reaches a specified capacity, until the performance gain in the query optimization reaches a specified percentage or until you permit the wizard to continue. At that point, you click the Stop button to stop the wizard from creating further aggregations.
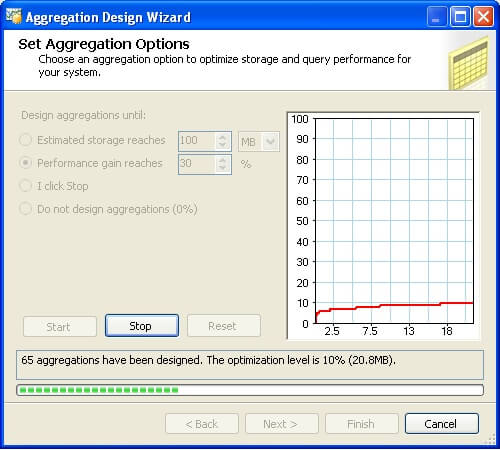
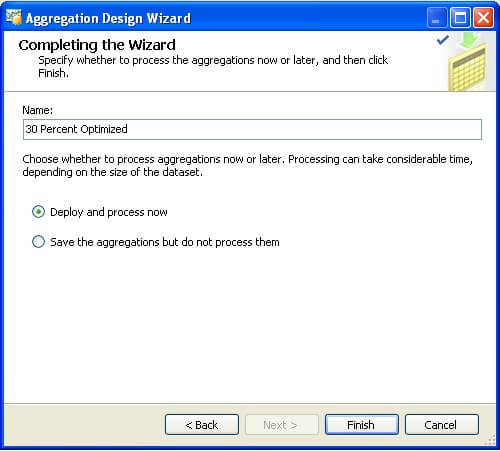
Step 5: On the next page of the wizard, you have the option of either "Deploy and process now" or "Save the aggregations but do not process them". At this point, the wizard has just created the plan to calculate the aggregations and store it, but the exercise has not been carried out. The same plan has to be executed now and aggregations have to be processed and deployed. We have chosen the option in Step 4 to create aggregation till performance reaches 30%, so we have named it accordingly.
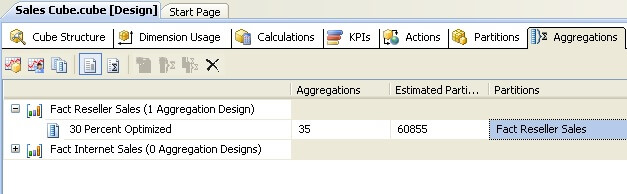
Step 6: After processing and deploying the aggregation, you would find that the aggregation has now been applied to the partition. You can always change the aggregation design or further modify it.
Next Steps
- Try using different options to create the best aggregation design for your partitions.
- Query your dimensional model and verify the number of rows and number of total members specified in Step 3 of the wizard matches the count from the source tables.
- Check out the SQL Server Analysis Services (SSAS) Tutorial.






About the author
 Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.
Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
