By: Sadequl Hussain | Comments (31) | Related: > Error Logs
Problem
SQL Server Error Logs often show a message related to error 18456. Although it generally means a login attempt from a client connection has failed, different State numbers associated with the error can mean different reasons for the failure. One of the error States is 38, which was added with SQL Server 2008, means the database being accessed cannot be found or does not exist. Unfortunately the Error Log entry does not show what database it is, so in this tip we walk through how you can determine which database is causing the error message.
Solution
A few days ago I was looking through the Error Log of a database server and noticed a large number of the same error messages that looked like the following:
2011-12-15 11:22:08.76 Logon Error: 18456, Severity: 14, State: 38.
2011-12-15 11:22:08.76 Logon Login failed for user '<domain_name>\<account_name>'. Reason: Failed to open the explicitly specified database. [CLIENT: XXX.XX.XX.XXX]
Error 18456 generally means a failed login attempt. Like other error messages, it also has a State number and there are different State numbers associated with it, each having a different meaning for the failure. As I found out later, States 38 and 40 (in SQL 2008 and later) and States 16 and 27 (before version 2008) mean that there is an issue with the database being connected to. The database could be offline, shutdown, deleted, dropped, renamed, auto-closed, or inaccessible for some other reason. It could also be the default database for the login where explicit permission was not given.
The server was running an instance of SQL Server 2008 and although it was a test instance, I decided to spend some time to find out what database was being accessed by this account. The reason I wanted to dig deeper was because the error was happening many times, almost every ten seconds, and in my view it had these potential problems:
- If this was a production server, SQL would be spending I/O time writing the same message to the Error Log. In other words, disk access would be almost continuous.
- The potentially large Error Log would take longer and longer to load. Even with this instance where the Error Log was cycled every night, it was still taking time to load thousands of rows of log entries. Things would be even worse for instances where the log was not cycled regularly.
- With the same error message repeated over and over, it would be difficult to sift through the log and a DBA could miss other errors or warnings.
- And of course there is the question of security - you should want to know why database access is being refused.
From the frequency of the messages, I knew the request was probably coming from an application or web server, so I ran the following command against the IP addresses to confirm this. nslookup is a command that can take an IP address as a parameter and tell you the name of the machine: it's like the reverse of the ping command.
I looked at the SQL Server logins and saw that the account in question was a member of the sysadmin role, meaning it had unrestricted access to all the databases in the server. In other words, it was trying to access a database that was not in the system anymore and I had to find that missing database. The problem would be simple if there were a few databases and if I knew the application well enough to identify each of them. This was a test environment reflecting a production system and there were 104 databases hosted by the instance. The Windows Application or Security Event Log did not yield much information either except showing the same messages.
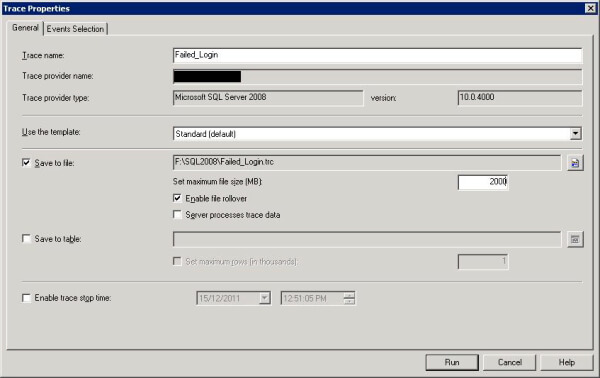
So I decided to start Profiler and put a trace on the server. I started with the default trace template (since I was going to modify the events anyway) and ensured the trace data was being saved somewhere:
Next came the question of choosing events. Since the problem was not associated with a query, I could get rid of the default TSQL and Stored Procedures events listed. Instead, I chose two different categories of events:
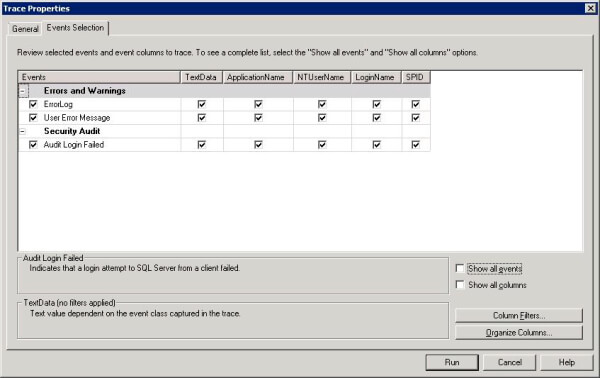
- Security Audit
- Errors and Warnings
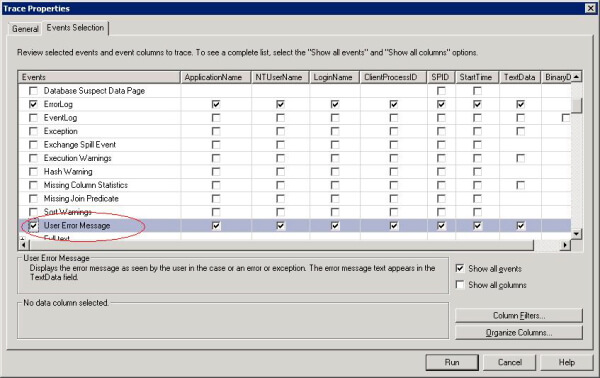
From the Security Audit category (which is automatically listed in the default trace), I only kept the "Audit Login Failed" event. It may be tempting to keep the "Audit Login" event as well, but if you think about it this would cause the trace to grow really big very quickly. Each login attempt would be recorded and the trace would have unnecessary entries that you would not need.
From the Errors and Warnings category, only two events were chosen. First, the "ErrorLog" event - this would trap every instance the Error Log is accessed. The second and the most important event was the "User Error Message". This is the event that would capture the error returned to the client (in this case the web server the connection request was being made from) and the message would contain the name of the database being accessed. This would also mean other messages sent to the client would also be captured, such as "database context changed to..." etc.
For the columns, only five were kept: TextData, ApplicationName, NTUserName, LoginName and SPID. Again, you may think the DatabaseID or DatabaseName columns would yield the required information, but in reality it only shows the context of the database from which the connection was requested. In this case, it was the account's default database: master. HostName was also not required because I knew the name of the requesting server already.
Finally, all that remained was to define a filter. I chose to filter the NTUserName field because I was able to determine the account name from the Error Log. (Make sure you replace the value with the account you are trying to trace.)
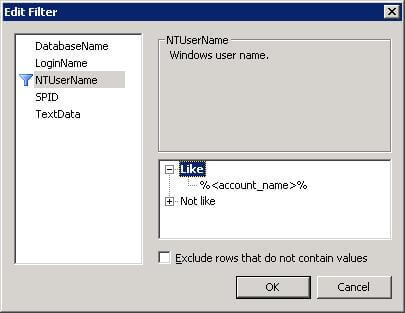
Within a few seconds of starting the trace, I had something like the following:
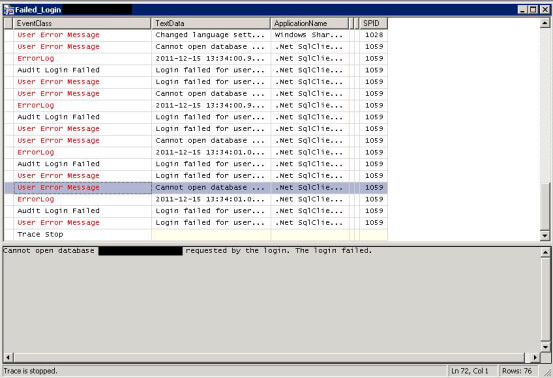
As you can see from the repeated entries, a user error message is sent to the client, then an Error Log entry is made and then the login failure audit is captured. Clicking on a User Error Message entry right before the Error Log entry gave me the name of the database that was causing the error.
The message was something like the following:
As I queried the sys.databases table, obviously there was no entry for that name, which proved my initial premise that the database had been dropped.
One thing you need to be aware of, particularly where large number of databases are associated, is that the account could be failing to connect to not one, but multiple databases. In my case as I found out, a number of databases had been dropped by the developers and the login attempt against each database was failing.
To cater for this, it's best to run Profiler for a reasonable amount of time so all database access attempts are captured. After you have stopped the trace, you can open the file and filter the TextData field for the error message, as shown below:
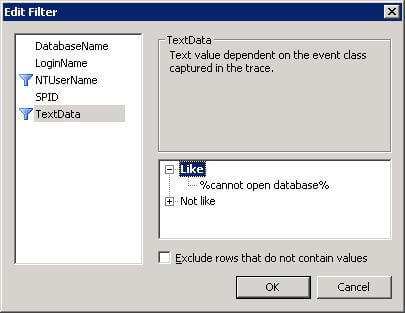
This allowed me to find seven databases that were missing. The next step was to contact the relevant application team and notify them of the missing databases.
Next Steps
- Learn more about SQL Server Profiler and how to set up trace
- Learn about SQL Server Error Log and how you can access the file in a text editor, outside of SSMS
- There is an excellent article on Error 18456, written by Aaron Bertrand. You can read it here.






About the author
 Sadequl Hussain has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical systems.
Sadequl Hussain has been working with SQL Server since version 6.5 and his life as a DBA has seen him managing mission critical systems.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
