By: Burt King | Comments (9) | Related: > Clustering
Problem
Recently a group of developers were looking for high availability solutions with SQL Server and ran into some problems because they believed some common myths regarding SQL Server and clustering. In this tip we'll look at some of these myths and correct the common misconceptions.
Solution
Myth #1: SQL Server Clustering Provides Better Performance Because each Node Handles Part of the Load
The confusion arises here because SQL Server is installed on each node in the cluster. Adding to this confusion is the additional capability for SQL Server to have multiple instances of SQL Server running in a cluster. This type of installation is typically called an Active-Active cluster meaning each node has an active installation of SQL Server running. However, the SQL Server services which run on each node, each run separate databases, in separate file systems; the data and file systems are never shared. A better name which Microsoft prefers is a multi-instance installation.
Take a look at example 1 below for a single instance of SQL Server. In this illustration the Green node is the installation of SQL Server that is running the SQL1 instance. When you look in the Control Panel | Services application you can see that SQL Server is running. On the gray node an instance of SQL is installed, but is shut down. In the Control Panel | Services application you see the SQL Server service is not running. An instance of SQL Server is installed on each node that acts as part of the clustered instance, but SQL Server runs on only one node at a time. If the instance of SQL Server were to be shut down and moved to another node, then the service would be shut down on the original node and then started on the new node running SQL Server.
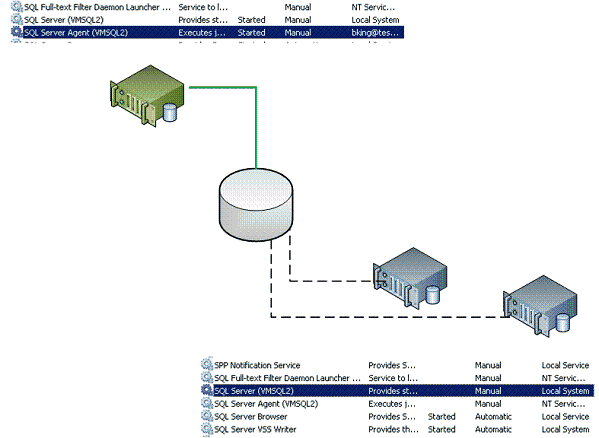
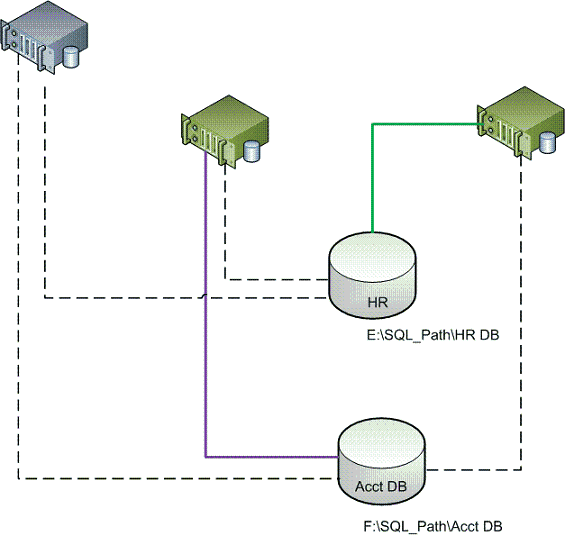
In example 2, often referred to as an Active-Active Cluster, there are three nodes with two instances of SQL Server running. Accounting is running on the first node and HR is running on the second. The dotted line indicates that the other node doesn't have access to the database instance, but could take over if needed. Notice the third server, this server has SQL Server installed and could take over as well. SQL Server is installed, but is not running at this time.
Myth #2: There is no SQL Server Down Time if the SQL Server Instance fails from one Node to the other
As the first myth explained, SQL Server is running on one node and is not started on the other node(s). When a failover condition occurs, SQL Server needs to startup on the new node that is taking over the instance of SQL Server. Whether the instance has failed or is restarted intentionally the effect is the same. SQL Server is starting up on the new node and proceeds through the recovery process which is the same process for SQL Server whether it is on a cluster or a non-clustered instance.
Since SQL Server may take anywhere from a few moments to several minutes to start, the virtual name of SQL Server and the instance of SQL Server are not available until the server recovers and the instance starts accepting connections. In addition, any transactions that have not been committed at the time of the failover are rolled back just as they are with a non-clustered instance of SQL Server.
We also need to recognize that when SQL Server restarts applications need to handle the issue of how to reconnect to the instance of SQL Server. SQL Server has no mechanism for storing in-flight transactions and connections. From the application point of view, SQL Server has either disappeared or been restarted. The application vendor will need to determine how and what to do when this occurs.
Myth #3: The SQL Server AlwaysOn Availability Groups feature in SQL Server 2012 requires that SQL Server be Clustered
SQL Server availability groups technology is new to SQL Server 2012 and has some resemblance to SQL Server mirroring technology. Availability groups are a grouping of databases with a virtual name and IP address that act as a single unit for users to access. If the server or file systems fail with an availability group on them, then the entire group is failed over to another replica on another server.
The confusion about SQL Server in a cluster with Availability Groups is pretty easy to understand. To deploy SQL Availability Groups SQL Server must be installed on a server that is part of a Windows Cluster; SQL Server itself, however, does not need to be clustered. What's more, Microsoft has taken the unfortunate position of also calling SQL Server Clustering, "Always On", which leads to confusion that clustering and availability groups are the same thing.
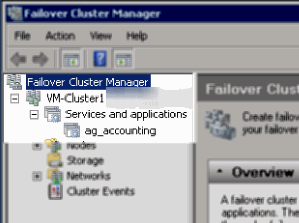
Example 3 shows failover cluster manager for our server. The availability group, ag_accounting, is listed as being online, but notice SQL Server is not present in the list of "Services and Applications" because it is not clustered.
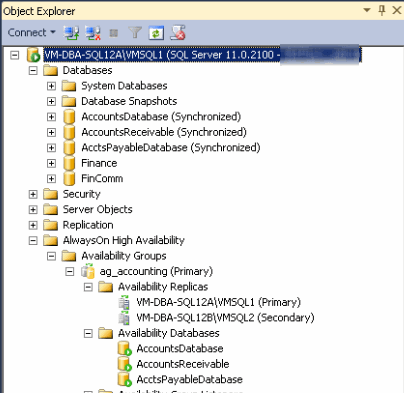
In the next example, example 4, we see how an Availability Group looks through SQL Server Management Studio. You'll first notice the databases indicate they are synchronized. In our example databases AccountsDatabase, AcctsPayableDatabase, and AccountsReceivable are all part of an Availability Group and would fail over together. The other two databases, Finance and FinComm are not part of an Availability Group and act as a database on a typical server. Inside the Availability Groups node in SQL Server Management Studio we see the databases listed in the Availability Databases node.
Myth 4: Other SQL Server Clustered Nodes can be used for Reporting Purposes
SQL Server 2012 does offer an AlwaysOn Availability option which allows the data from SQL Server to be accessed from another server, but SQL Server Clustering does not. SQL Server Clustering contains one set of databases that exist on a shared storage array such as the EMC DMX family of storage. An instance of SQL Server is installed on one more nodes, which can access the data. The access is restricted to one SQL Server instance unless a failover occurs or the SQL Server Cluster is manually failed over to another node.
The option which does allow read only access to other nodes is the SQL Server AlwaysOn Availability Groups feature and the implementation is moderately more involved than setting up a single clustered instance. SQL Server Availability Groups work by copying the data in real time or near real time to another instance of SQL Server and then that data can be made available as a read only replica. With SQL Server AlwaysOn Availability Groups the data can be applied at the destination server synchronously or asynchronously insuring zero latency or minimal latency.
Myth 5: Non Critical SQL Server Databases on a Clustered Instance can reside on Disks that are not Clustered to Save Money
SQL Server 2012 and all previous versions of SQL Server require databases be created on clustered resources. Internal drives or drives which are not part of the cluster group cannot hold user databases. To create a database the syntax remains the same, but SQL Server will perform an additional check to verify the resource is clustered. Also note that SQL Server will accept ANY drive path making no distinction between different levels of RAID technology such as RAID 5 or RAID 1. It is up to the DBA to ensure drives can handle the load which will be placed on them.
In the following illustration, Example 5, the output from a CREATE DATABASE T-SQL statement is issued after attempting to place a database on non-clustered disk.

In SQL Server 2012 Microsoft has made one exception to this rule allowing, for the first time, Tempdb to be installed on non-clustered disk. This is especially useful for those who choose to use internal Solid State Disk (SSD) drive technology to get the best performance possible. The ALTER Database statement is the same as before to move Tempdb.
Next Steps
- Review this tip for information on using Tempdb with local storage.
- Familiarize yourself with setting up Always on Availability groups with this tip
- Check out this additional resource from Microsoft on Availability groups with SQL Server 2012.






About the author
 Burt King is Senior Database Administrator at enservio with more than 15 years experience with SQL Server and has contributed to MSSQLTips.com since 2011.
Burt King is Senior Database Administrator at enservio with more than 15 years experience with SQL Server and has contributed to MSSQLTips.com since 2011.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
