Problem
Due to the Coronavirus pandemic, Quarantine and Lockdown are two prominent words from the year 2020. The word Quarantine means isolating things such as a COVID-19 positive patient to prevent the spread of the disease.
Does the keyword Quarantine have a relationship with Windows Failover Clusters? We will explore the following topics in this tip to find out.
- What do we mean by a Quarantine of Windows Failover Cluster nodes?
- How do we get rid of a Quarantine node?
Solution
Recently, while working with my Windows Server 2016 Failover Cluster for Availability Groups, I found the Quarantined status for one of the nodes.
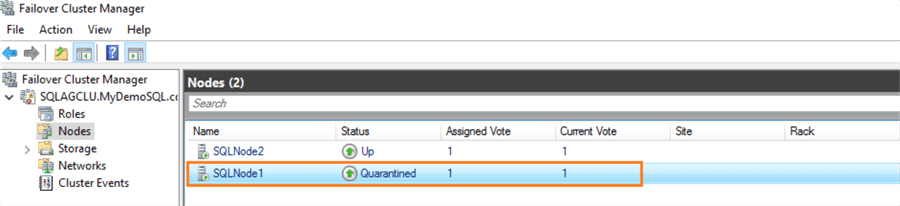
To simulate the scenario, I shut down SQLNode1 three times. It transitions the status from Up to Quarantined. However, in the above screenshot, it shows a green arrow for quarantined status because the node is online, but it is not joined with the cluster.
I verified the following for troubleshooting purposes.
- Quarantined node [SQLNode1] is online
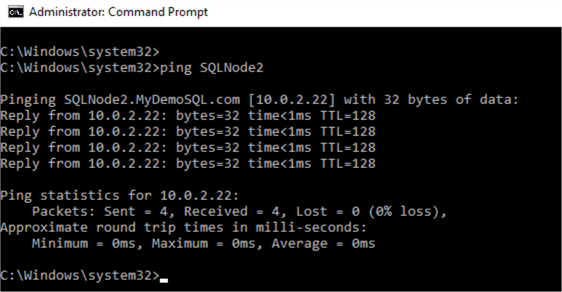
- You also get a ping response from the healthy node to Quarantined node.
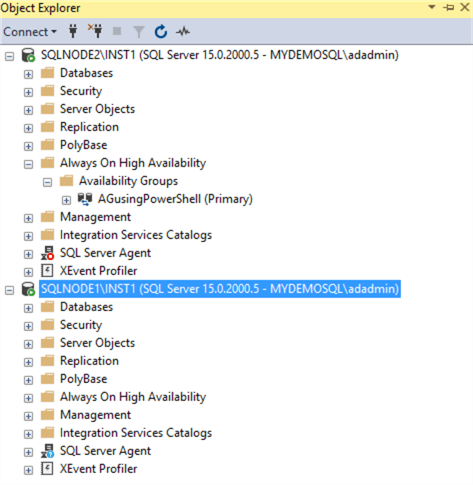
- The connection to SQL instance [SQLNode1\INST] is successful.
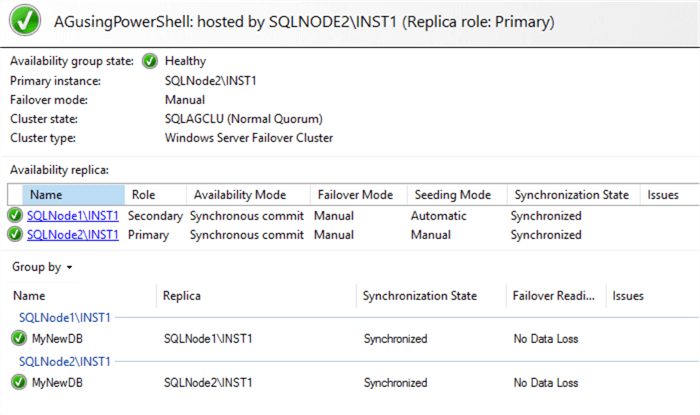
However, the Availability Group dashboard is not synchronized. It shows a warning symbol for the quarantined replica.
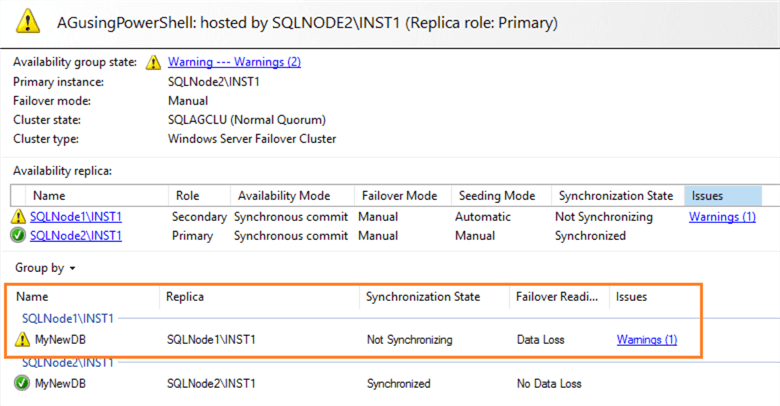
If you click on the Warnings (1), it complains about the unhealthy data synchronization state for the quarantined replica.
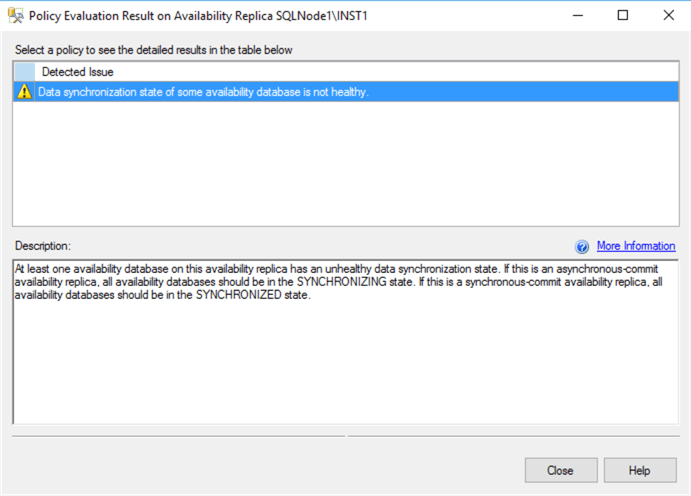
Let’s view the SQL Server logs to investigate the synchronization issue. Here, you get information about terminating the connection from the secondary replica SQL instance. It does not specify the reason like the node quarantined in the SQL Server logs. Therefore, it is essential to examine the SQL logs as well as failover cluster logs while investigating the AG synchronization issues.
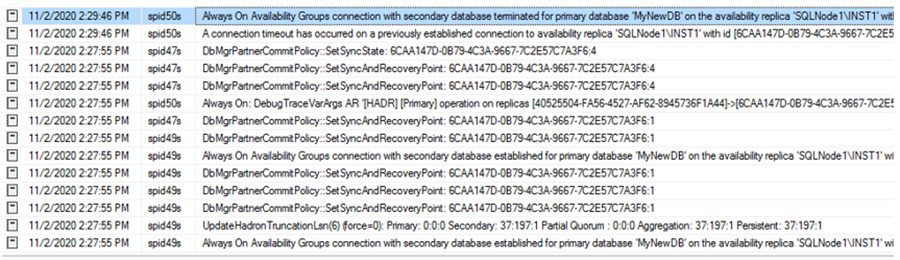
Quarantined nodes in Windows Failover Clusters
Starting with Windows Server 2016, Microsoft has improved the Virtual Machine Compute Resiliency. It safeguards your clusters from transient failures. If any failover nodes leave the cluster three times in an hour, WSFC does not allow the node to rejoin the cluster for the next 2 hours. The node might have issues due to network failures, hardware, or power issues. The Quarantined node helps prevent the unstable cluster state or quorum loss.
To get more details, filter the cluster properties with the Quarantine property using the Get-Cluster PowerShell command.
Get-Cluster | Format-List -Property Quarantine*
It returns two properties, QuarantineThreshold and QuarantineDuration, with their default values.
- QuarantineThreshold: Defines the maximum number of times a node can go into isolation before it is quarantined. By default, it has a value 3.
- QuarantineDuration: Defines the period the node will be in the quarantined state. By default, the value is 7200 seconds, or 2 hours.
Track the remaining QuarantineDuration for a node in Quarantined status
As we saw earlier, my [SQLNode1] is already in the quarantined state. For the QuarantineDuration, it remains like this status for 2 hours. However, the question remains – When will my node will be back in its normal status?
To track the remaining time for QuarantineDuration out of 7200 seconds, we can view the cluster events. Click on the cluster name and you will see Recent Cluster Events with the latest warnings, errors, and critical errors.

In cluster events, you can see the exact event details.
- The node experienced ‘3’ (default value of QuarantineThreshold) consecutive failures in an hour. The node is removed from the cluster to avoid further disruptions.
- It gives you a timestamp that says when the quarantine will be automatically cleared.

It also logs a warning message stating the quarantine type. According to the message, the cluster node cannot join the cluster automatically until the specified timestamp.
Cluster node ‘SQLNode1’ has been quarantined by ‘cluster nodes’ and cannot join the cluster. The node will be quarantined until ‘2020/11/01-17:34:59.892’ and then the node will automatically attempt to rejoin the cluster.
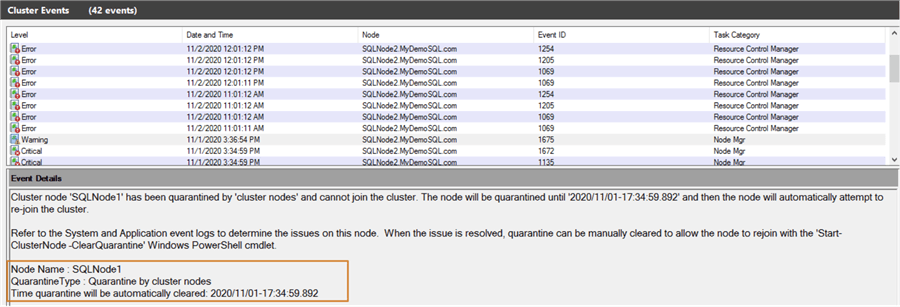
Manually remove the quarantine status for Windows Failover Cluster
It is unlikely that we want to wait another 2 hours for node availability after the defined QuarantineDuration of 2 hours. Suppose there were some network connectivity issues between the nodes. Once we investigate and fix these issues, we can remove the quarantine status for the nodes. WSFC allows you to manually use PowerShell command.
To remove the quarantined status manually, we can use Failover Clustering PowerShell and execute the Start-ClusterNode cmdlet with the ClearQuarantine flag. You can also specify –CQ flag in the Start-ClusterNode cmdlet.
Start-ClusterNode -ClearQuarantineThis command returns the node state as Joining, shown below.

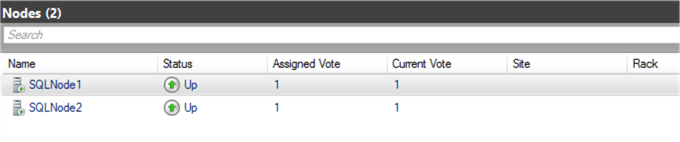
It clears the quarantine status for SQLNode1, joins the server back to cluster, and makes it available for failovers. Refresh your Nodes in Failover Cluster Manager and see all nodes in the Up status as shown below.
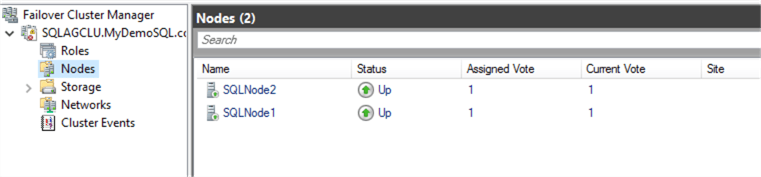
As the cluster transitioned from quarantined to Up status, your AG dashboard is now healthy.
Configuring Quarantine settings for Windows Failover Clusters
We can modify the Windows failover cluster quarantine settings based on our infrastructure requirements.
- Modify the QuarantineThreshold value
Suppose we want to modify the QuarantineThreshold value to 2 failures in an hour. For this purpose, run the following Windows PowerShell command.
(Get-Cluster).QuarantineThreshold=2It changes the quarantine threshold, as shown below.

- Modify the QuarantineDuration value from default 7200 seconds to 3600 seconds
(Get-Cluster).QuarantineDuration=3600
For this demonstrations purpose, let’s change the QuarantineDuration to three minutes (180 seconds).

To validate these settings, I forced the Windows failover cluster to transition SQLNode1 into quarantined status (forced shutdown twice).
At this time, since the SQLNode1 is down, it shows a red down arrow for Quarantined status.

In the cluster critical events, we can verify that SQLNode1 went into quarantined status after two consecutive failures (within an hour).

This time the SQLNode1 joins the cluster automatically after 180 seconds.
Note: At any given time, Windows Failover cluster does not allow more than 25% of nodes to be quarantined.
Conclusion
In this article, we explored the Windows Failover Cluster resiliency improvement in Windows Server 2016. It puts the node into quarantined state and stops clusters communications. If you use SQL availability groups, it goes into Not Synchronizing state despite the SQL instance availability.
Next Steps
- Review your Windows Failover Cluster configurations for QuarantineThreshold and QuarantineDuration.
- Go through the Failover clustering tips on MSSQLTips.

Hi! I am Rajendra Gupta, Database Specialist and Architect, helping organizations implement Microsoft SQL Server, Azure, Couchbase, AWS solutions fast and efficiently, fix related issues, and Performance Tuning with over 14 years of experience.
I am the author of the book “DP-300 Administering Relational Database on Microsoft Azure.” I can be reached at: Rajendra.gupta16@gmail.com for any consulting help.
- MSSQLTips Awards:
- Author of the Year – 2022 | Author Contender – 2021/2023/2024 | Champion Award (100+ tips) – 2020

Scott: still struggling with this. Both nodes are green, but one is UP and the other is Quarantined. In addition, my secondary node and databases are not synced with the Primary. not sure if it’s a Listener issue, or network connection to the DR, or what not.
@MrB how did you resolve this as I have the exact same scenario in a 2 node AG Cluster
One of my Nodes is still in quarantine after 6 hours. Tried using the clearQuarantine command but it still shows in the Failover Cluster Manager. However, in the SSMS Availability Group Dashboard, everything is green and synchronized. Not sure what to do next.
Thanks for your article. its really helpful to resolve the issue
This blog helps me a lot to understand quarantine concept in WSFC
Ah that makes more sense.
Thanks @Rajendra gupta.
Thanks for your comments. At a given time, a maximum of 25% node or 1 node can be quarantined . Therefore, we can have maximum 1 node in quarantine state for 2,3,4 node cluster. However, We need to test this behavior for 5 or mode cluster nodes.
Thanks for the info Raj!
As Eitan mentioned, the NOTE doesn’t sit well with the example.
Probably someone with four node cluster can help prove it.
If quarantine threshold is for 25% of nodes, how come 50% of two nodes could be quarantined?
Could it be because the threshold check is done only before the quarantine and not after?
I.e. it allows one of the nodes to become quarantined because at that time there’s 0% nodes already in quarantine, but after it’s quarantined then the other node will not be quarantined because there’s already 50% quarantined?
I’m totally guessing here.
Thanks Tim
Thanks Eitan. You can refer to following article for confirmation.
https://techcommunity.microsoft.com/t5/failover-clustering/virtual-machine-compute-resiliency-in-windows-server-2016/ba-p/372027
Great article. I’ve never worked with SQL Server clusters before, and didn’t realize there was a quarantined state. Really good information-Tim
Thanks for sharing!
This part doesn’t seem right:
Note: At any given time, Windows Failover cluster does not allow more than 25% of nodes to be quarantined.
In your specific example you have only two nodes, which means that when one is quarantined then it’s already 50% of the nodes.
So I think your note about 25% is not quite right.
Great article other than that. Very useful!