By: Koen Verbeeck | Comments (63) | Related: More > Integration Services Development
Problem
When you want to load data into your data warehouse, for example into one of your dimensions, you need to determine if an incoming row is either an update - a historical change - or an insert, which is a new occurrence of a record. An update row is a source record for which the business key - or the natural key as some folks prefer - is already present in the destination table. To process these updates as efficient as possible, you need to determine if the update is an actual update, meaning that at least one of the columns has changed values. If none of the columns have actually changed, you can skip the update of that record and save some precious resources.
A common method to detect if a row has changed is to compare hashes: if the hash of the incoming record is different from the hash found in the destination table, one or more columns have changed. Christian Allaire describes the concept using the T-SQL Hashbytes function in the tip Using Hashbytes to track and store historical changes for SQL Server data. Integration Services itself doesn't have a hash implementation, so in this tip I'll show how you can implement a hash detection mechanism using a script component, as an alternative to the pure T-SQL solution.
Solution
The concept of the incremental load pattern - where you detect the inserts and the updates - is described clearly in this article by Andy Leonard: SSIS Design Pattern - Incremental Loads. We will closely follow those recommendations in this tip, but I'll make some performance improvements and add the hashing of course. The explanation in this tip is valid for all versions of SSIS starting from SQL Server 2012 (and possibly 2005/2008 as well).
Demonstrate Data Load Options in SSIS
Let's keep it simple and use the AdventureWorksDW2017 database as the source for our data, which you can download here. If you don't have SQL Server 2017, you can use any earlier version of the AdventureWorksDW database as well. The following query will extract the data:
SELECT [CustomerAlternateKey] -- this is our business key (BK) ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] ,[BirthDate] ,[MaritalStatus] ,[Suffix] ,[Gender] ,[EmailAddress] ,[YearlyIncome] ,[TotalChildren] ,[NumberChildrenAtHome] ,[EnglishEducation] ,[EnglishOccupation] ,[HouseOwnerFlag] ,[NumberCarsOwned] FROM [dbo].[DimCustomer];
All of the data is selected from the source. The SSIS package will detect which rows are inserts and which rows are updates.
The destination table can be created with the following script:
IF NOT EXISTS (SELECT 1 FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[MyDestination]')
AND [type] IN (N'U'))
BEGIN
CREATE TABLE [dbo].[MyDestination](
[SK_Customers] [int] IDENTITY(1,1) NOT NULL,
[CustomerAlternateKey] [nvarchar](15) NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [nvarchar](50) NULL,
[MiddleName] [nvarchar](50) NULL,
[LastName] [nvarchar](50) NULL,
[BirthDate] [date] NULL,
[MaritalStatus] [nchar](1) NULL,
[Suffix] [nvarchar](10) NULL,
[Gender] [nvarchar](1) NULL,
[EmailAddress] [nvarchar](50) NULL,
[YearlyIncome] [money] NULL,
[TotalChildren] [tinyint] NULL,
[NumberChildrenAtHome] [tinyint] NULL,
[EnglishEducation] [nvarchar](40) NULL,
[EnglishOccupation] [nvarchar](100) NULL,
[HouseOwnerFlag] [nchar](1) NULL,
[NumberCarsOwned] [tinyint] NULL,
[DWH_Hash] [char](66) NULL,
CONSTRAINT [PK_MyDestination] PRIMARY KEY CLUSTERED
([SK_Customers] ASC)
);
END
The incremental load package takes the following form:
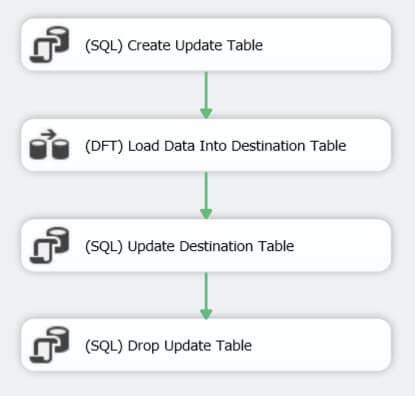
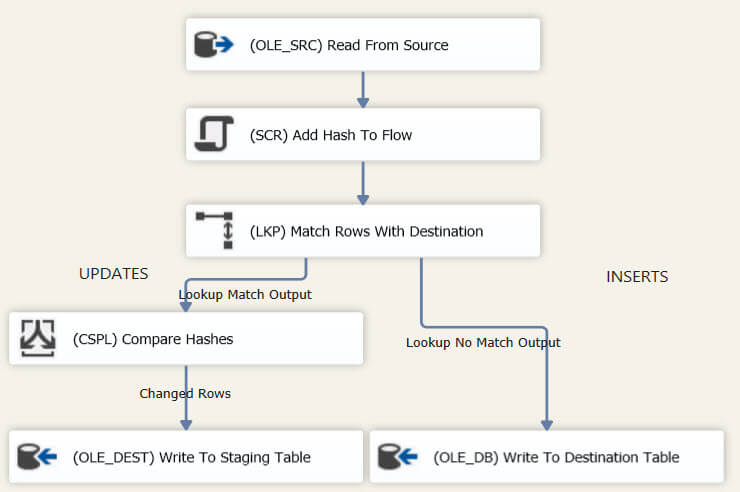
The original incremental load pattern uses an OLE DB Command in the data flow to perform the updates. I dislike this component because it issues a statement for every single row that passes through the component, which is horribly slow for large data sets and it can also bloat the transaction log. Therefore I create a staging table that will hold the update rows so that a set-based UPDATE statement can be issued in the third task. This improves performance immensely. The update table is created with this statement:
IF EXISTS (SELECT 1 FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[UPD_MyDestination]')
AND [type] IN (N'U'))
BEGIN
DROP TABLE [dbo].[UPD_MyDestination];
END
CREATE TABLE [dbo].[UPD_MyDestination](
[SK_Customers] [int] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [nvarchar](50) NULL,
[MiddleName] [nvarchar](50) NULL,
[LastName] [nvarchar](50) NULL,
[BirthDate] [date] NULL,
[MaritalStatus] [nchar](1) NULL,
[Suffix] [nvarchar](10) NULL,
[Gender] [nvarchar](1) NULL,
[EmailAddress] [nvarchar](50) NULL,
[YearlyIncome] [money] NULL,
[TotalChildren] [tinyint] NULL,
[NumberChildrenAtHome] [tinyint] NULL,
[EnglishEducation] [nvarchar](40) NULL,
[EnglishOccupation] [nvarchar](100) NULL,
[HouseOwnerFlag] [nchar](1) NULL,
[NumberCarsOwned] [tinyint] NULL,
[DWH_Hash] CHAR(66) NOT NULL
);
Next, the data flow will load the data from the source and uses a Lookup component to find out if a row is an insert or an update. The Lookup uses the following query to fetch the reference data set from the destination table:
SELECT SK_Customers,CustomerAlternateKey,DWH_Hash FROM MyDestination;
Hint: always write a SQL query to select the lookup columns from the reference data set. Never use the drop down; it selects all columns and wastes memory. If you select only the columns you actually need, chances are good that you can fit everything in memory with the full cache option, even for very large reference sets.
The Lookup matches the source rows with the destination rows using the business key. If a match is found - an update - the surrogate key and the hash are retrieved. Make sure to configure the Lookup to redirect non-matching rows to the no match output.
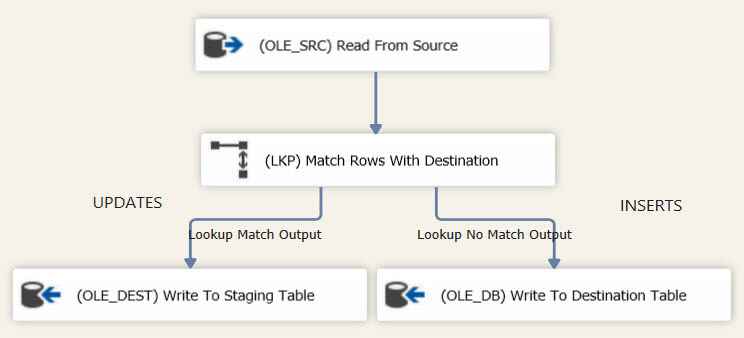
The third task updates the destination table using the rows stored in the staging table.
UPDATE dest SET [Title] = upd.[Title] ,[FirstName] = upd.[FirstName] ,[MiddleName] = upd.[MiddleName] ,[LastName] = upd.[LastName] ,[BirthDate] = upd.[BirthDate] ,[MaritalStatus] = upd.[MaritalStatus] ,[Suffix] = upd.[Suffix] ,[Gender] = upd.[Gender] ,[EmailAddress] = upd.[EmailAddress] ,[YearlyIncome] = upd.[YearlyIncome] ,[TotalChildren] = upd.[TotalChildren] ,[NumberChildrenAtHome] = upd.[NumberChildrenAtHome] ,[EnglishEducation] = upd.[EnglishEducation] ,[EnglishOccupation] = upd.[EnglishOccupation] ,[HouseOwnerFlag] = upd.[HouseOwnerFlag] ,[NumberCarsOwned] = upd.[NumberCarsOwned] ,[DWH_Hash] = upd.[DWH_Hash] FROM [dbo].[MyDestination] dest JOIN [dbo].[UPD_MyDestination] upd ON dest.SK_Customers = upd.SK_Customers;
The final task will drop the staging table, which is optional of course. If you drop it though, don't forget to set the package to DelayValidation=TRUE.
When this package is run for the first time, all of the source rows are new and are directly inserted into the destination.
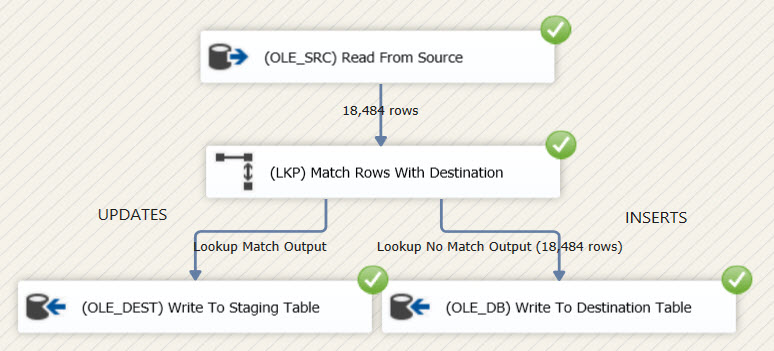
When the package is run again, all rows matched against the destination table and are sent to the staging table. This means that all of the rows were updated, while this wasn't necessary at all.
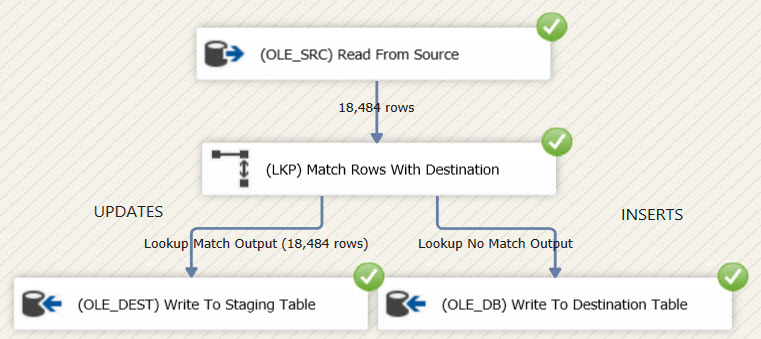
Now let's add a hash to detect if there were actual changes or not.
Adding the Hash Value to Detect Data Changes in SSIS
In this tip, we'll use the script component to calculate the hash in .NET. However, you can also use the T-SQL HASHBYTES function if your source is SQL Server. Most database vendors have similar functions. The script component is a good alternative when your source doesn't have this functionality. For example, you are loading flat files or an Excel file. Or, the source databases doesn't support hashing property (for example, Sybase ASE has a hash function, but it doesn't include the SHA2 algorithm).
From the SSIS Toolbox, add a script component to the data flow canvas. A pop-up will ask you which type of script you want: a source, a transformation or a destination. Choose the transformation. Open up the editor. In this tip, I will use C# code. If you're more familiar with VB.NET, the code can easily be adapted. Go to the Input Columns pane and add every column, except the business key. It won't change since it is the business key after all, so it is not necessary to add it to the hash. All of the input columns can be left as ReadOnly.
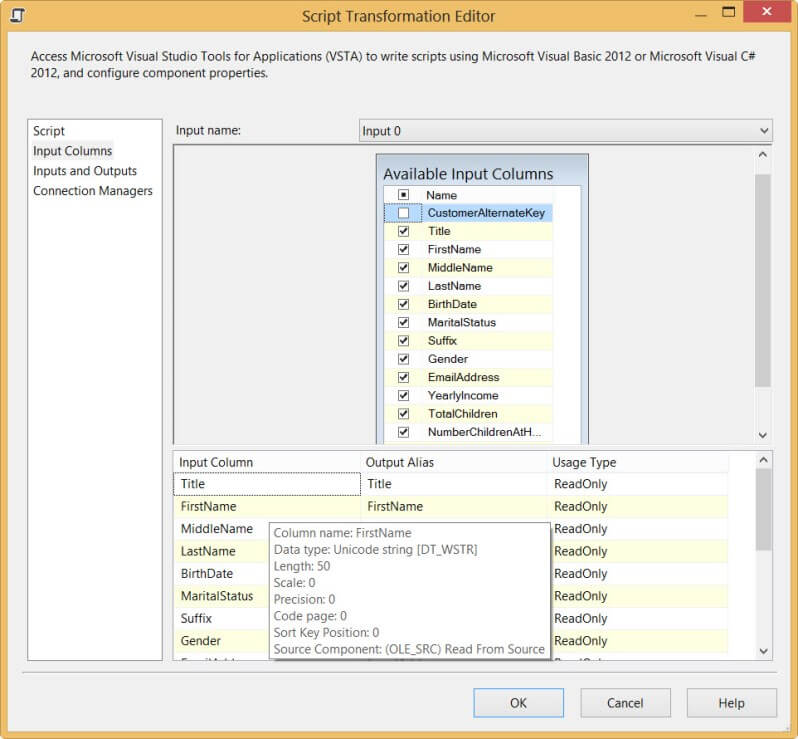
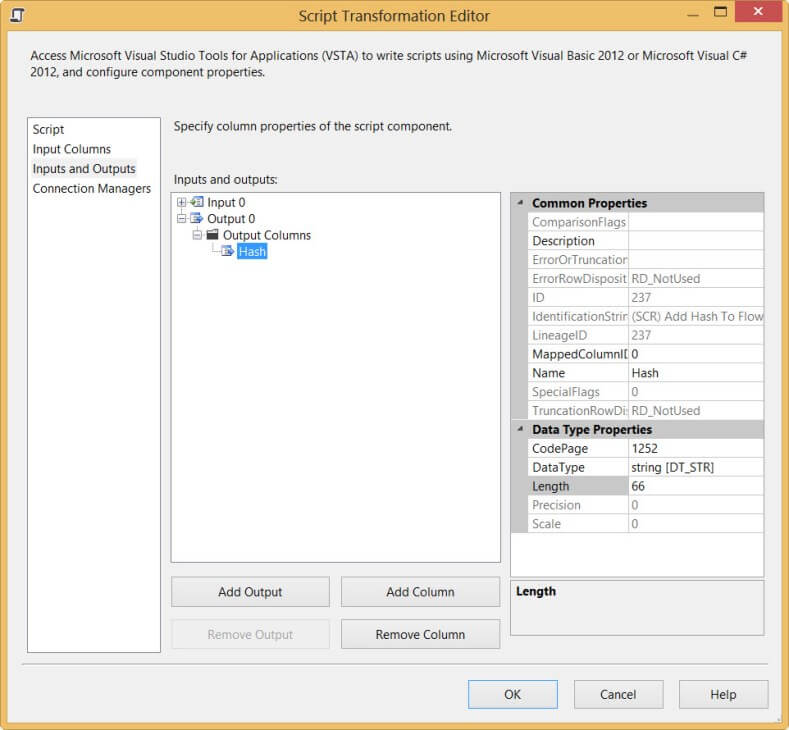
Now go to the Inputs and Outputs pane. There we will add the Hash column to the output. Give it the string data type with a length of 66. I will explain later why we are using this length.
Go back to the Script pane and open up the script editor. Since we are going to use a hash function, which is a cryptographic function, a reference to System.Security.Cryptography needs to be added to the solution.
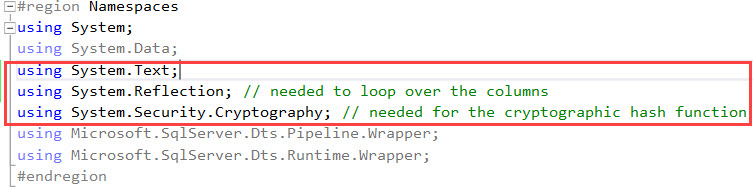
We also add System.Text so we can use the StringBuilder class and the System.Reflection namespace for looping over the input columns.
The script takes the following steps:
- Concatenate all input columns into one long string. If a column contains a NULL value, convert it to an empty string.
- Compute the hash over this concatenated string. This will return an array of bytes.
- This array is converted back to a string using a for loop and is finally added to the output. The characters '0x' are prefixed to the result, to resemble the output of the HASHBYTE function.
Instead of hard-coding all of the input columns in the concatenation, we loop over the input buffer to retrieve all the columnsThe final code looks like this:
private SHA256 sha = new SHA256CryptoServiceProvider(); // used to create the SHA256 hash
public override void Input0_ProcessInputRow(Input0Buffer Row)
{
StringBuilder concat = new StringBuilder("");
// loop over all the input columns of the buffer row
foreach(PropertyInfo inputColumn in Row.GetType().GetProperties())
{
// ignore the _IsNull properties (used to check a column for NULL values) and the output column Hash
if (!inputColumn.Name.EndsWith("IsNull") && !inputColumn.Name.Equals("Hash"))
{
// check for NULL values, otherwise the script fails
if (inputColumn.GetValue(Row, null) == null)
{
concat.Append(""); // add an empty string
}
else
{
// add the value of the input column to the concat string
concat.Append(Convert.ToString(inputColumn.GetValue(Row).ToString()));
}
concat.Append("|"); // add pipe as delimiter
}
}
// convert to string and remove last pipe
string hashSource = concat.ToString().Remove(concat.ToString().Length - 1);
// calculate the hash over the concatenated values
byte[] hashBytes = sha.ComputeHash(System.Text.UnicodeEncoding.Unicode.GetBytes(hashSource));
// convert the byte stream to a string
StringBuilder sb = new StringBuilder("");
for (int i = 0; i < hashBytes.Length; i++)
{
sb.Append(hashBytes[i].ToString("X2"));
}
Row.Hash = "0x" + sb.ToString(); // add the result to the output
}
The script uses the SHA256 hash function to compute the hash. This hash function outputs a 256 bit hash and is much safer than the regular used MD5 hash and is less prone to hash collisions. The SHA256CryptoServiceProvider class is used to implement the hash, but you can also use the SHA256Managed class. There is not much difference between the two, expect the implementation behind the scenes. The CryptoServiceProvider class might be preferred above the managed class for regulatory reasons.
The 256 bit length of the hash ensures that the chance on hash collisions is minimal. 256 bit map to 32 Unicode characters in SQL Server, or 64 non-Unicode characters. If you add the two extra characters from '0x', you get the 66 character length used in the destination table and in the script component.
Note: if you use SQL Server 2012 or a more recent edition as the source, you can also use the new CONCAT function to concatenate the string values. However, the script component can easily be ported to earlier versions of SQL Server.
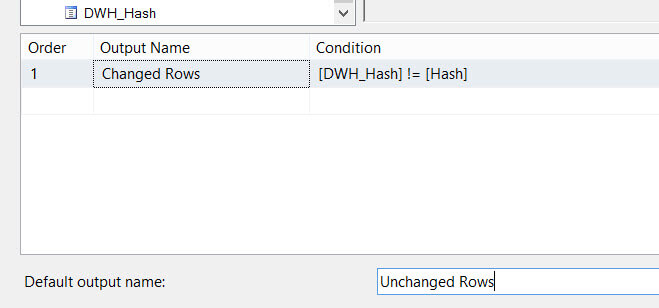
Add a Conditional Split transformation between the Lookup and the OLE DB Destination on the math output path. The expression is simple but effective:
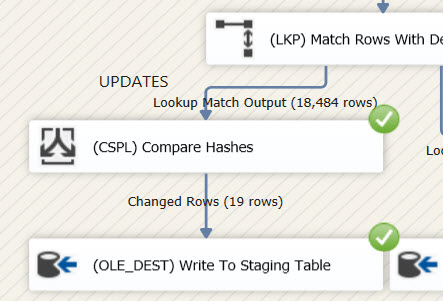
The final data flow has the following layout:
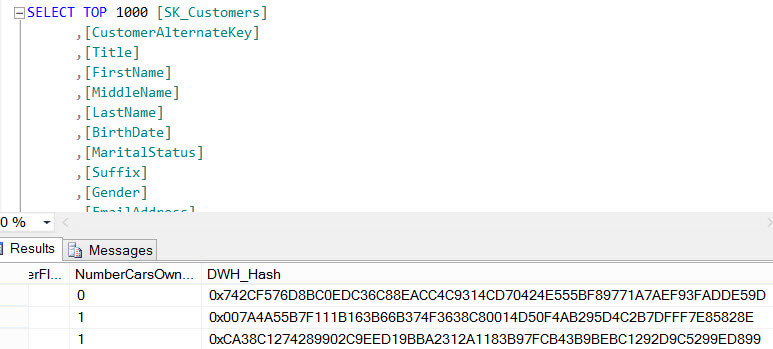
If the destination table is truncated and the initial load is executed again, you can find the hash stored alongside the data in the destination table.
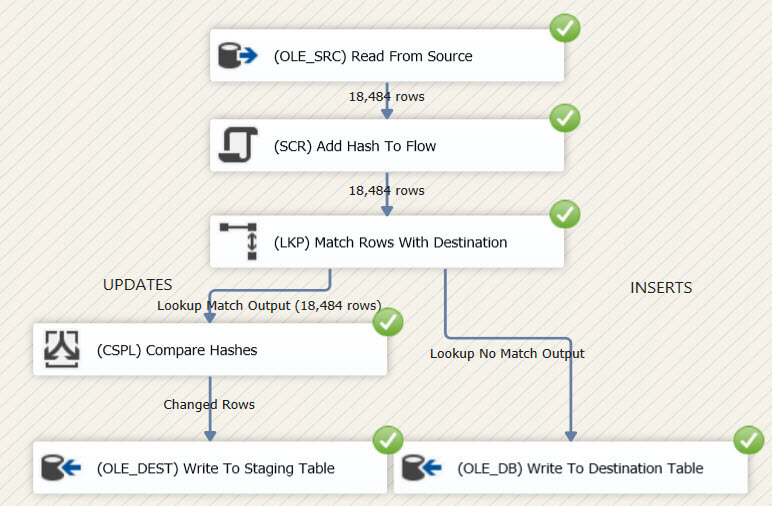
Now, here is the moment that sums up this entire tip, if the package is run again, a single row does not make it to the destination table.
Let's change some rows in the source with the following script:
UPDATE [dbo].[DimCustomer] SET Title = 'Test123' WHERE CustomerKey % 1000 = 0; -- this updates 19 rows
If the package is run again, only the changed rows are written to the staging table and subsequently updated. Mission accomplished.
Conclusion
This tip demonstrated how you can efficiently manage the number of updates that come through your SSIS package with a hash. Since the hash is calculated in a script component, the solution is independent of any possible source.
Next Steps
- Check out the tip Using Hashbytes to track and store historical changes for SQL Server data to learn about a more T-SQL centric approach of this problem.
- Try it out yourself! You can download the package used in the tip here.
- Think about which changes you would need to make to the package to load a type 2 slowly changing dimension.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
