By: Koen Verbeeck | Comments (2) | Related: More > Integration Services Development
Problem
The previous tip Simple Text Mining with the SSIS Term Extraction Component introduced us to some simple text analysis using Integration Services (SSIS), the Microsoft ETL-tool included with SQL Server. There the Term Extraction component was presented, which aided us in extracting different nouns and phrases from text, giving us a list of terms used frequently in the text. This tip will introduce you to its sibling, the Term Lookup component, using the same simple use case: analyzing tweets. If you have not read the previous tip, I recommend you do as we will reference it a few times.
Solution
Before we start, a small, but important warning: the Term Extraction and the Term Lookup transformations fall under the Advanced Transforms, which means they are only available in Enterprise edition. You can still develop a package using these components in BIDS or SSDT(BI), but if you run it on a server with a lower edition, an error will be returned. For more information, check out Features Supported by the Editions of SQL Server 2012.
A simple use case for the SSIS Term Lookup Component
As mentioned before, we will use the same use case in this tip as used with the Term Extraction component, which is an archive of all my tweets I've downloaded from Twitter. Using this archive and the Term Extraction transformation I found out which topics I particularly tweeted about in the past years or which persons I mentioned the most. This results were outputted in the form of a list of terms together with their frequency. With the Term Lookup component, I could use this list to find the exact tweets that interest me. According to its definition on MSDN:
The Term Lookup transformation matches terms
extracted from text in a transformation input column with terms in a reference
table.
...
This transformation is useful for creating a
custom word list based on the input text, complete with word frequency
statistics.
...
The transformation will parse the text in the same manner as the Term Extraction component and compare it with the reference list. If a match is found, the term is sent to the output together with its frequency count.
A similar use case is described in chapter 4 of the book Professional Microsoft SQL Server 2014 Integration Services, pages 154-164. In the book they use the Term Extraction component to extract terms about product models and their issues from customer services notes. Then the Term Lookup component is used to find the exact customer service notes that interest us. Other uses cases described by the development team of the transformations can be found in this blog post: Text Mining with Term Lookup and Term Extraction.
Getting Started with the Integration Services Term Lookup Component
Using the Term Lookup component is pretty straight forward. First of all we will create the reference list. This is done with the following T-SQL statement:
CREATE TABLE dbo.TermsReference
(ID INT IDENTITY(1,1) NOT NULL
,[Term] NVARCHAR(100) NOT NULL);
INSERT INTO dbo.TermsReference(Term)
VALUES ('SSIS')
,('MSSQLTIPS')
,('SQL Server')
,('#sqlserver')
,('sql2012');
The destination table is created with this statement:
CREATE TABLE dbo.Tweet_TermLookup(
ID INT IDENTITY(1,1) NOT NULL
,[Term] NVARCHAR(100)
,[Frequency] INT
,[TweetsMatching] NVARCHAR(150)
);
The control flow of the SSIS package only needs one data flow.
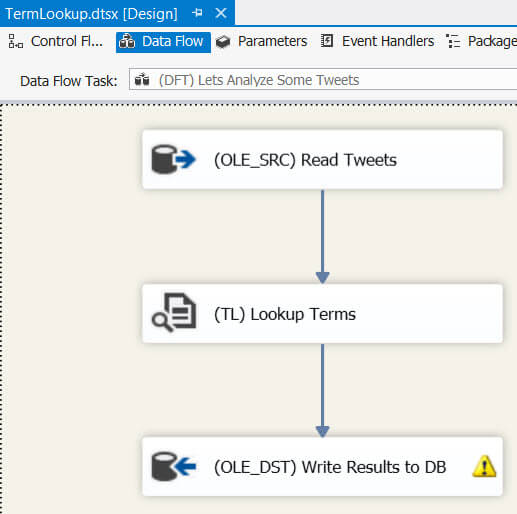
The data flow itself is also very simple: a source to read the text, the Term Extraction transformation and a destination to write the results back to the database.
The tweets are read from the source with the following SELECT statement:
SELECT tweets = CONVERT(NVARCHAR(150),[text]) FROM [dbo].[tweets];
Just like the Term Extraction component, the Term Lookup transformation expects a Unicode input - this means the data flow data types DT_WSTR or DT_NTEXT - so a little conversion is added to the SQL statement. If your incoming text exceeds 8000 characters, you need to choose DT_NTEXT.
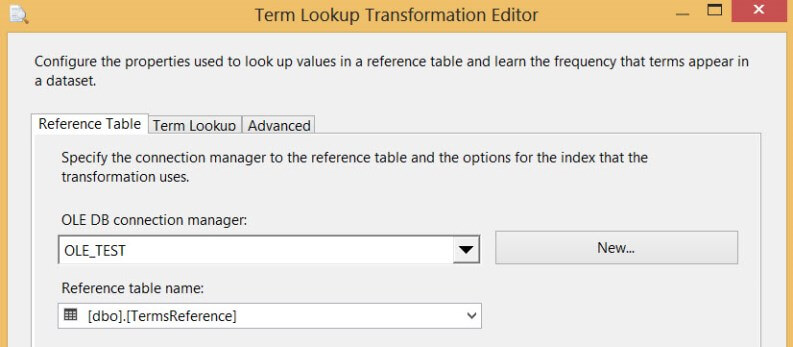
Let's edit the component itself. First you need to supply the reference table that contains the terms you want to lookup. The transformation only accepts an OLE DB connection and you need to select the table from a dropdown. You cannot write a SQL query.
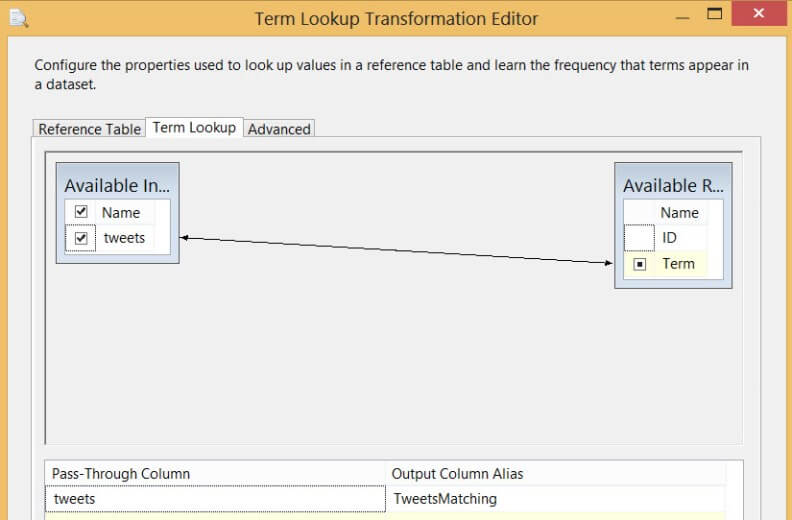
In the next pane you configure the lookup itself. You need to drag the column from the input to the field of the reference table you want to match on. You need to select at least one column of the input as a pass-through column.
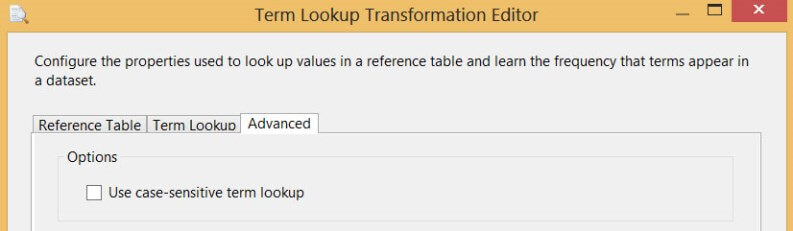
In the final pane - the advanced configuration - you can only decide if the transformation is case-sensitive or not.
As with the Term Extraction component, the transformation error configuration is by default set to Redirect row. This gives a warning when you close the editor.
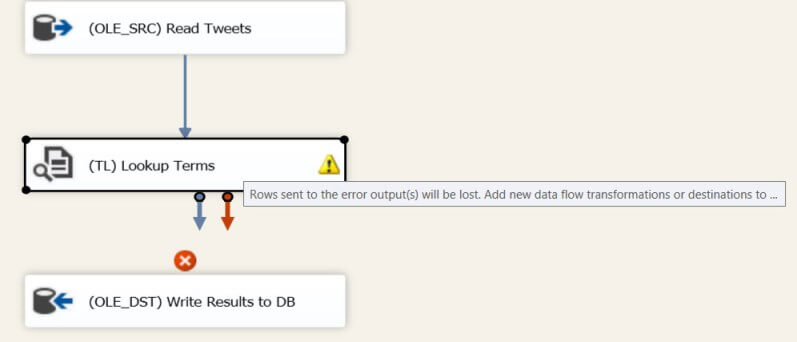
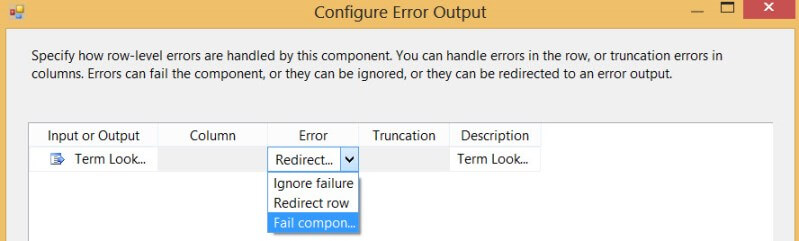
You can get rid of this warning by connecting the error output of course, or by changing the behavior to Ignore Failure or Fail Component in the Configure Error Output screen in the transformation editor.
The output is connected to an OLE DB Destination which will write the results to a table. The data flow still gives a warning because for some reason the transformation outputs the terms as strings of length 128, while they are defined in the reference table with length 100.
Using the SSIS Term Lookup
On a fairly decent laptop, the data flow takes less than one second to return 1,549 matches from 7,241 tweets. Let's take a look at the results.
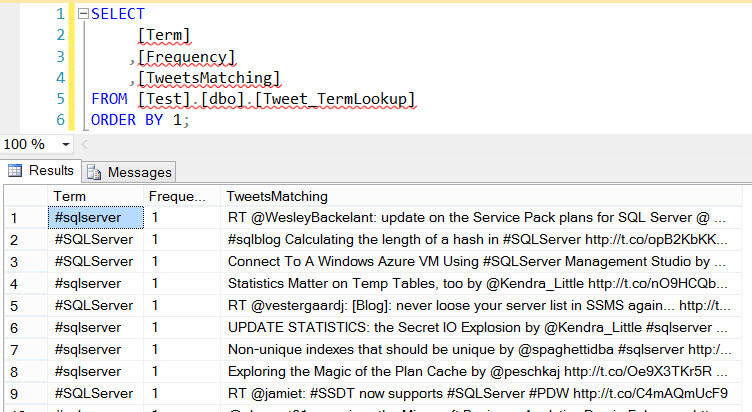
As you can see in the screenshot, the results are case insensitive as #sqlserver and #SQLServer are considered the same. The frequency statistic indicates how many times the term occurred in a single tweet. If you want to know how many times a term occurred in the entire text, you'll need to aggregate the results.
Remarks
The Term Lookup is a semi-blocking transformation, meaning it is not blocking like the Term Extraction, but it is still an asynchronous component, which can have an impact on performance. If the data set is too large to be processed efficiently, you could try to split up the text in smaller chunks and run the term lookup on each separate part.
Another issue is that it also - like the Term Extraction - behaves like a black box. You have no control whatsoever on how to algorithm extracts the terms from the input text. You can only configure it the matching is case sensitive or not.
When two different terms overlap, such as SQL and SQL Server, the term lookup will only return 1 match. An advantage of this transformation is that it deal with special characters. This means we can lookup terms such as hash tags and handles, like #sqlserver and @mssqltips.
Conclusion
The Term Lookup transformation is very easy to use and it can give results quickly give great insights into what people are saying about different subjects. The combination with the Term Extraction is very powerful and can lead to interesting results. Mind though that both components need the Enterprise edition of SQL Server.
Next Steps
- For more details on the transformation check out the MSDN documentation.
- The tip Simple Text Mining with the SSIS Term Extraction Component tells you everything you need to know about the Term Extraction component.
- Think about how you could use the text analysis transformations in your environment and what benefits they could bring.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
