Problem
I need to merge two similar tables from different SQL Server databases and also merge the child tables that are connected by foreign key relationships. The parent tables use an identity for their primary key, so I need to track and maintain the relationships when I copy the data over. How can I do this, preferably in a set-based fashion?
Solution
It is common in databases to use a surrogate key to identify each row. Using a surrogate key instead of a natural key has both advantages and disadvantages. The two most common surrogate keys in SQL Server are its uniqueidentifier and IDENTITY. SQL Servers unique identifiers are globally unique, but IDENTITY fields are obviously not unique. So, if you try to merge two tables that use identities, the identity value of many of the rows will change. This is not a problem if there is nothing with a persistent dependence on those identity values, but foreign keys create a persistent dependence. So, if there is a child table with foreign keys, when it is merged it needs to still point to the correct row in the merged parent table even though the identity will change.
As with many things in SQL Server, this is clearer with an example. So, say we have two separate stores that each maintain their own customer tables, using an identity as a primary key. A customer may have more than one phone number, so phone numbers are tracked in a separate child table linked by a foreign key. In a simple form, this could look like:
use test
GO
create table dbo.customers
(
Id int identity(1,1) primary key,
FName varchar(25),
LName varchar(25)
)
create table dbo.phoneNumbers
(
Id int identity(1,1) primary key,
CustId int,
PhoneNumber varchar(12)
)
alter table dbo.phoneNumbers add constraint
FK_phonenumbers_customers foreign key (CustId) references dbo.customers(Id)
insert into dbo.customers (FName, LName)
values
('Albert','Einstein'),
('Archimedes','Syracuse')
insert into dbo.phoneNumbers (CustId, PhoneNumber)
values
(1, '299-792-4580'),
(1, '992-297-0854'),
(2, '314-159-2653'),
(2, '413-951-3562')
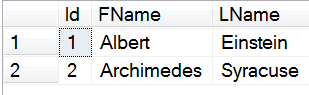
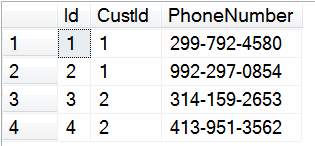
Now say we have a second location that uses the same database structure and same applications, but it has different data. For instance, its data might look like:
use test2
GO
create table dbo.customers
(
Id int identity(1,1) primary key,
FName varchar(25),
LName varchar(25)
)
create table dbo.phoneNumbers
(
Id int identity(1,1) primary key,
CustId int,
PhoneNumber varchar(12)
)
alter table dbo.phoneNumbers add constraint
FK_phonenumbers_customers foreign key (CustId) references dbo.customers(Id)
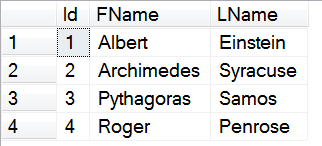
insert into dbo.customers (FName, LName)
values
('Pythagoras','Samos'),
('Roger','Penrose')
insert into dbo.phoneNumbers (CustId, PhoneNumber)
values
(1, '141-421-3562'),
(1, '141-124-2653'),
(2, '161-803-3988'),
(2, '161-308-8893')
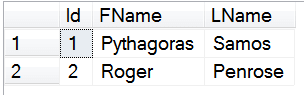
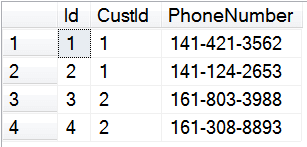
Eventually, there may be a need to merge this data. Trying to do a direct insert like:
--This does not work properly use test GO insert into dbo.customers (FName, LName) select FName, LName from test2.dbo.customers insert into dbo.phoneNumbers (CustId, PhoneNumber) select CustId, PhoneNumber from test2.dbo.phoneNumbers
does not work because of the identity for a primary key. If we actually did this, it would give us a situation where all four phone numbers are attributed to the two customers that were in the dbo.customers table first and none are attributed to the customers being imported.

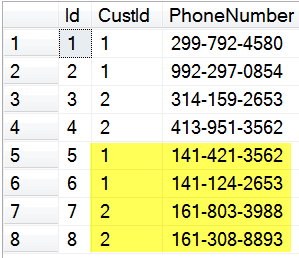
So, we need to keep track of the old and new customer IDs to be able to properly move the data from the phoneNumbers table. We could do this by writing a script that copies the rows over one at a time and retrieves the new identity with @@IDENTITY or SCOPE_IDENTITY. But those functions can interact in complex ways with triggers and replication, not to mention that doing it that way means handling the data row-by-agonizing-row which is less than ideal. Using the OUTPUT clause with the insert statement would seem ideal, but that does not give access to the source table so we do not have an easy way to match the newly inserted IDs with the original ID. Fortunately, in SQL Server 2008 and later, the output clause with the MERGE statement allows access to the newly inserted rows as well as the source rows. So, the code to fully merge the tables would look like:
--Create a table variable to track the ID matchups declare @matchTableVar table (OriginalId int, insertedId int); merge into test.dbo.customers as tgt using test2.dbo.customers as src on 1 != 1 --Always false, ensures all rows copied when not matched then insert (FName, LName) values (src.FName, LName) output src.Id, --We have access to the source table inserted.Id into @matchTableVar; --Merge statements must end with a ; insert into test.dbo.phoneNumbers (CustId, PhoneNumber) select m.insertedId, --The id that was populated in tgt p.PhoneNumber from test2.dbo.phoneNumbers p left join @matchTableVar m --LEFT join is important, otherwise may not copy all rows on p.CustId = m.OriginalId --Make sure it is matching on the FK, not the PK here
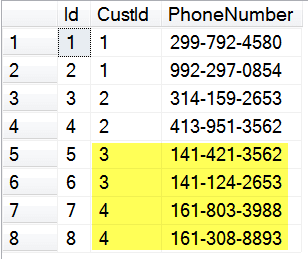
There are a few things to note here. In the merge statement, the 1 != 1 is there to ensure that the not matched condition is always met and it performs the insert for all rows. It then uses the output clause, which for merge has access to the source tables as well as the inserted virtual table, to send the new and old IDs to a table variable. Note that the merge statement, unlike most statements for T-SQL, must be terminated with a semicolon. After performing the merge, it uses that table variable to join with the child table to do the insert and provide the new ID. When doing the insert, you need to use a left or right join as appropriate to make sure all the rows from the child table are matched. If you do an inner join, some rows may be skipped. Also, the match with the table variable needs to be on the foreign key row (CustId in this example) and not on the primary key of the child table. I have made both of those mistakes at various times.
At least for later versions of SQL Server, the MERGE command with its versatile output clause provides a convenient way to move data even when identities that are tied to foreign keys are involved.
Next Steps
- Arshad Ali provides another example of using merge in his article Using MERGE in SQL Server to insert, update and delete at the same time
- Adam Machanic explains in detail how to use the merge statement, including some of its limitations and its use with the OUTPUT clause in Dr. OUTPUT or: How I Learned to Stop Worrying and Love the MERGE

Tim Wiseman is a SQL Server DBA and developer in Las Vegas with over 6 years of database experience. He holds a BS in mathematics along with MCDBA and MCITP certifications. In his nearly nonexistent free time, he attends grad school, plays Go, enjoys time with his wonderful wife and kids, and writes about technical topics. His LinkedIn profile is available here. And his new blog is on WordPress.


