By: Armando Prato | Comments (38) | Related: 1 | 2 | 3 | 4 | > Identities
Problem
I'm designing a table and I've decided to create an auto-generated primary key value as opposed to creating my own scheme or using natural keys. I see that SQL Server offers globally unique identifiers (GUIDs) as well as identities to create these values. What are the pros and cons of these approaches?
Solution
Yes, there are a number of ways you can auto-generate key values for your tables. The most common ways are via the use of the IDENTITY column property or by specifying a uniqueidentifier (GUID) data type along with defaulting with either the NEWID() or NEWSEQUENTIALID() function. Furthermore, GUIDs are heavily used in SQL Server Replication to uniquely identify rows in Merge Replication or Transactional Replication with updating subscriptions.
The most common, well known way to auto-generate a key value is via the use of the IDENTITY column property on a column that's typically declared as an integer. Once defined, the engine will automatically generate a sequential number based on the way the property has been declared on the column. The IDENTITY property takes an initial seed value as its first parameter and an increment value as its second parameter.
Consider the following example which creates and inserts into identity based tables that define the primary key as a clustered index:
SET NOCOUNT ON
GO
USE MASTER
GO
CREATE DATABASE MSSQLTIPS
GO
USE MSSQLTIPS
GO
-- Start at 1 and increment by 1
CREATE TABLE IDENTITY_TEST1
(
ID INT IDENTITY(1,1) PRIMARY KEY,
TESTCOLUMN CHAR(2000) DEFAULT REPLICATE('X',2000)
)
GO
-- Start at 10 and increment by 10
CREATE TABLE IDENTITY_TEST2
(
ID INT IDENTITY(10,10) PRIMARY KEY,
TESTCOLUMN CHAR(2000) DEFAULT REPLICATE('X',2000)
)
GO
-- Start at 1000 and increment by 5
CREATE TABLE IDENTITY_TEST3
(
ID INT IDENTITY(1000,5) PRIMARY KEY,
TESTCOLUMN CHAR(2000) DEFAULT REPLICATE('X',2000)
)
GO
-- INSERT 1000 ROWS INTO EACH TEST TABLE
DECLARE @COUNTER INT
SET @COUNTER = 1
WHILE (@COUNTER <= 1000)
BEGIN
INSERT INTO IDENTITY_TEST1 DEFAULT VALUES
INSERT INTO IDENTITY_TEST2 DEFAULT VALUES
INSERT INTO IDENTITY_TEST3 DEFAULT VALUES
SET @COUNTER = @COUNTER + 1
END
GO
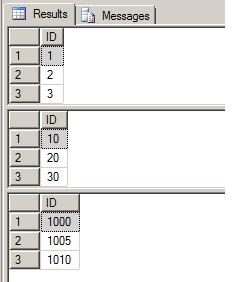
SELECT TOP 3 ID FROM IDENTITY_TEST1
SELECT TOP 3 ID FROM IDENTITY_TEST2
SELECT TOP 3 ID FROM IDENTITY_TEST3
GO
Another way to auto-generate key values is to specify your column as a type of uniqueidentifier and DEFAULT using NEWID() or NEWSEQUENTIALID(). Unlike IDENTITY, a DEFAULT constraint must be used to assign a GUID value to the column.
How do NEWID() and NEWSEQUENTIALID() differ? NEWID() randomly generates a guaranteed unique value based on the identification number of the server's network card plus a unique number from the CPU clock. In contrast, NEWSEQUENTIALID() generates these values in sequential order as opposed to randomly.
Let's create new tables that use a uniqueidentifier along with both NEWID() and NEWSEQUENTIALID()
USE MSSQLTIPS
GO
CREATE TABLE NEWID_TEST
(
ID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
TESTCOLUMN CHAR(2000) DEFAULT REPLICATE('X',2000)
)
GO
CREATE TABLE NEWSEQUENTIALID_TEST
(
ID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
TESTCOLUMN CHAR(2000) DEFAULT REPLICATE('X',2000)
)
GO
-- INSERT 1000 ROWS INTO EACH TEST TABLE
DECLARE @COUNTER INT
SET @COUNTER = 1
WHILE (@COUNTER <= 1000)
BEGIN
INSERT INTO NEWID_TEST DEFAULT VALUES
INSERT INTO NEWSEQUENTIALID_TEST DEFAULT VALUES
SET @COUNTER = @COUNTER + 1
END
GO
SELECT TOP 3 ID FROM NEWID_TEST
SELECT TOP 3 ID FROM NEWSEQUENTIALID_TEST
GO
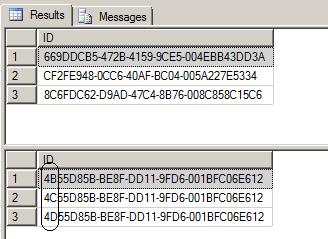
As you can see, the first table which uses NEWID() generates random values while the second table that uses NEWSEQUENTIALID() generates sequential values. As opposed to the integers generated by the IDENTITY approach, the GUID values generated are not as friendly to look at or work with. There is one other item to note. SQL Server keeps the last generated identity value in memory which can be retrieved right after an INSERT using SCOPE_IDENTITY(), @@IDENTITY, or CHECK_IDENT (depending on the scope you require). There is nothing similar to capture the last generated GUID value. If you use a GUID, you'll have to create your own mechanism to capture the last inserted value (i.e. retrieve the GUID prior to insertion or use the SQL Server 2005 OUTPUT clause).
Now that we understand how to auto generate key values and what they look like, let's examine the storage impacts of each approach. As part of the previously created table definitions, I added a column of CHAR(2000) to mimic the storage of additional column data. Let's examine the physical storage of the data:
USE MSSQLTIPS GO SELECT OBJECT_NAME([OBJECT_ID]) as tablename, avg_fragmentation_in_percent, fragment_count, page_count FROM sys.dm_db_index_physical_stats (DB_ID(), null, null, null, null) ORDER BY tablename GO
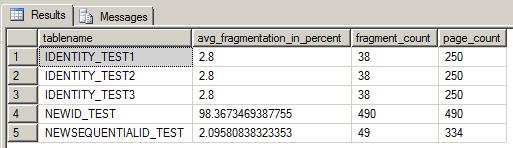
Looking at this output, you can see that the NEWID() test table is very fragmented as evidenced by its fragmentation percentage of 98%. Furthermore, you can see that the rows were dispersed among 490 pages. This is due to the page splitting that occurred due to the random nature of the key generation. In contrast, the IDENTITY and NEWSEQUENTIALID() test tables show minimal fragmentation since their auto generated keys occur in sequential order. As a result, they don't suffer from the page splitting condition that plagues the NEWID() approach. Though you can defragment the NEWID() table, the random nature of the key generation will still cause page splitting and fragmentation with all future table INSERTs. However, page splitting can be minimized by specifying an appropriate FILL FACTOR.
Looking at the NEWSEQUENTIALID() test table, we see it generated fewer pages than the NEWID() approach but it still generated more pages than the IDENTITY approach. Why is this? It's because the uniqueidentifier data type consumes 16 bytes of disk space as opposed to the 4 bytes used by the integer data type that was used for the IDENTITY. Considering that SQL Server pages are generally capped at 8K or roughly 8060 bytes (as of SQL Server 2005, there is a row-overflow mechanism that can kick in but that's for another discussion), this leads to more pages generated for the NEWSEQUENTIALID() approach as opposed to the IDENTITY approach.
Examining the database table space used, we see that the tables using the IDENTITY approach used the least amount disk space.
exec sp_spaceused IDENTITY_TEST1 GO exec sp_spaceused IDENTITY_TEST2 GO exec sp_spaceused IDENTITY_TEST3 GO exec sp_spaceused NEWID_TEST GO exec sp_spaceused NEWSEQUENTIALID_TEST GO
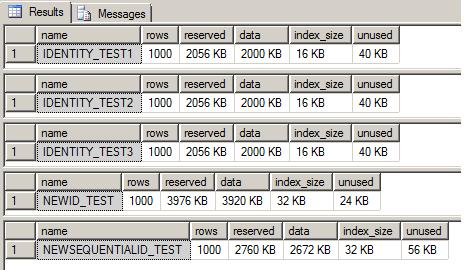
Now also consider this, since a uniqueidentifier data type consumes 16 bytes of data, the size of any defined non-clustered indexes on a table using a GUID as a clustered index are also affected because the leaf level of these non-clustered indexes contains the clustered index key as a pointer. As a result, the size of any non-clustered indexes would end up being larger than if an IDENTITY were defined as integer or bigint.
It's evident that using IDENTITY to auto-generate key values offers a few advantages over the GUID approaches:
- IDENTITY generated values are configurable, easy to read, and easier to work with
- Fewer database pages are required to satisfy query requests
- In comparison to NEWID(), page splitting (and its associated overhead) is eliminated
- Database size is minimized
- System functions exist to capture the last generated IDENTITY value (i.e. SCOPE_IDENTITY(), etc)
- Some system functions - such as MIN() and MAX(), for instance - cannot be used on uniqueidentifier columns
Next Steps
- Read more about NEWSEQUENTIALID() in the SQL Server 2005 Books Online
- Read Using uniqueidentifier Data in the SQL Server 2005 Books Online
- If you're not in a situation where you require a globally unique value, consider if an IDENTITY makes sense for auto-generating your key values.
- Regardless if you decide on a GUID or IDENTITY, consider adding a meaningful UNIQUE key based on the real data in your table.






About the author
 Armando Prato has close to 30 years of industry experience and has been working with SQL Server since version 6.5.
Armando Prato has close to 30 years of industry experience and has been working with SQL Server since version 6.5.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
