By: Greg Robidoux | Updated: 2022-02-18 | Comments (39) | Related: 1 | 2 | > Identities
Problem
I have a database table that has a lot of data already in the table and I need to add a new column to this table to include a new sequential number. In addition to adding the column, I also need to populate the existing records with an incremental counter what options are there to do this?
Solution
The first approach that may come to mind is to add an identity column to your table if the table does not already have an identity column. We will take a look at this approach as well as looking at how to do this with a simple UPDATE statement.
Using an Identity Column to Increment the Value by 1
In this example we are going to create a table (to mimic a table that already exists), load 100,000 records and then alter the table to add the identity column with an increment of 1.
CREATE TABLE accounts ( fname VARCHAR(20), lname VARCHAR(20))
GO
INSERT accounts VALUES ('Fred', 'Flintstone')
GO 100000
SELECT TOP 10 * FROM accounts
GO
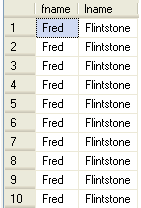
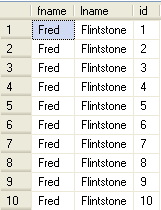
ALTER TABLE accounts ADD id INT IDENTITY(1,1) GO SELECT TOP 10 * FROM accounts GO
The statistics time and statistics i/o show this did about 23K logical reads and took about 48 seconds to complete.
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 17 ms.
Table 'accounts'. Scan count 1, logical reads 23751, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 6281 ms, elapsed time = 48701 ms.
SQL Server Execution Times:
CPU time = 6281 ms, elapsed time = 48474 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Using Variables To Update and Increment the Value by 1
In this example we create a similar table (to mimic a table that already exists), load it with 100,000 records, alter the table to add an INT column and then do the update.
CREATE TABLE accounts2 ( fname VARCHAR(20), lname VARCHAR(20))
GO
INSERT accounts2 VALUES ('Barney', 'Rubble')
GO 100000
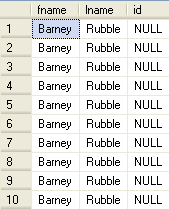
SELECT TOP 10 * FROM accounts2
GO

After the table has been created and the data loaded we add a new INT column to the table that is not an identity column.
ALTER TABLE accounts2 ADD id INT GO SELECT TOP 10 * FROM accounts2 GO
In this step we are doing an UPDATE to the table and for each row that is updated we are updating the variable by 1 as well as the id column in the table. This can be seen here (SET @id = id = @id + 1) where we are making the @id value and the id column equal to the current @id value + 1.
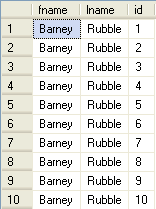
DECLARE @id INT SET @id = 0 UPDATE accounts2 SET @id = id = @id + 1 GO SELECT * FROM accounts2 GO
Below we can see the results where each record gets an incrementing value by 1.
The statistics time and statistics i/o show this did about 26K logical reads and took about 4.8 seconds to complete.
CPU time = 0 ms, elapsed time = 247 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Table 'accounts2'. Scan count 1, logical reads 26384, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 4781 ms, elapsed time = 4856 ms.
(100000 row(s) affected)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
If we compare the statistics time and statistics i/o from the the update with the identity column to this approach the overall number of logical reads is just about the same, but the overall duration is about 10 times faster doing the update versus having to maintain the identity value.
Using Variables To Update and Increment the Value by 10
Let's say we want to increment by 10 instead of by 1. We can do the update as we did above, but use a value of 10 to have the ids in increments of 10 for each record.
For clarity purposes, I am going to first make the id column NULL for all records and then do the update.
UPDATE accounts2 SET id = NULL GO DECLARE @id INT SET @id = 0 UPDATE accounts2 SET @id = id = @id + 10 GO SELECT * FROM accounts2 GO
Below we can see the id values now increment by 10 instead of 1. You can use any value you want to do the increment (1, 2, 5, 10, etc.).
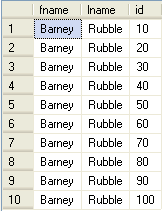
Warning: Possible Duplicate Values
Two of our readers Tillman Dickson and Steve Ash have noted that they have run into an issue where duplicate values are created if this processs is run in parallel. Tillman noted this issue on a table that had over 11 million rows and Steve mentioned this issue on a very large table as well. I tried to duplicate the issue, but on the systems I tested with I was not able to recreate the issue. This doesn't mean that on your systems you won't possibly face the same issue, so to avoid having duplicate values Tillman and Steve have suggested these approaches.
-- use MAXDOP of 1 - Steve Ash -- this will run the update using only one processor avoiding the issue of duplicates DECLARE @id INT SET @id = 0 UPDATE accounts2 SET @id = id = @id + 1 OPTION ( MAXDOP 1 ) GO
-- use SERIALIZABLE isolation level - Tillman Dickson -- this means that no other transactions can modify data that has been read -- by the current transaction until the current transaction completes. SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRANSACTION DECLARE @id INT SET @id = 0 UPDATE accounts2 SET @id = id = @id + 1 COMMIT TRANSACTION
Another approach to update the sequence values
Here is another approach by another reader Ervin Steckl.
-- update rows using a CTE - Ervin Steckl ;WITH a AS( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) as rn, id FROM accounts2 ) UPDATE a SET id=rn OPTION (MAXDOP 1)
Summary
Once you have created an identity column there is no easy way to renumber all of your values for each row. With the update approach you could do this over and over again by just rerunning the query and changing the values. This should work with all versions of SQL Server and the CTE versions with SQL Server 2005 and later.
Next Steps
- If you have the need to add a new sequential value to your tables or have the need to update an existing value in a sequential manner don't forget about this approach
- Look for other T-SQL tips and tricks here






About the author
 Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.
Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-02-18
