Problem
While designing a SQL Server database, the primary key column is often set to auto-increment. To do this, the IDENTITY constraint is set on the primary key column. The starting position and the increment step are passed as parameters to the IDENTITY column. Then whenever a new record is inserted, the value of the IDENTITY column is incremented by the pre-defined step, usually a number. Now if a record is deleted, the IDENTITY column value for that record is also deleted. If a new record is inserted, its value for the IDENTITY column will be incremented from the previous figure in the column. It is not possible to reuse the value that was originally used by the now deleted record. If you try to specify the value for the IDENTITY column, an error will be thrown. So how do you reuse the value that was assigned to the deleted record?
Solution
The solution to this problem is to switch on the SET IDENTITY INSERT flag, which is off by default. Switching the SET IDENTITY INSERT flag to ON allows for the insertion of any random value to the IDENTITY column, as long as it doesn’t already exist.
In this article, I will explain (with the help of an example) how to insert a missing value into the IDENTITY column.
Setup Example Table and Data
First let’s create some dummy data. We will execute our sample queries on this new database.
CREATE DATABASE School
GO
USE School
GO
CREATE TABLE Students
(
Id INT PRIMARY KEY IDENTITY(2,2),
StudentName VARCHAR (50),
StudentAge INT
)
GO
INSERT INTO Students VALUES ('Sally', 25 )
INSERT INTO Students VALUES ('Edward', 32 )
INSERT INTO Students VALUES ('Jon', 24 )
INSERT INTO Students VALUES ('Scot', 21)
INSERT INTO Students VALUES ('Ben', 33 )
In the script, we create a dummy database “School”. Next, we execute the script that creates a table named “Students”. If you look at the table design, you can see that it contains three columns Id, StudentName and StudentAge. The Id column is the primary key column with an IDENTITY constraint. Both the seed and step values for IDENTITY are set to 2. This means that the first record in the “Students” database will have the Id value of 2 and each subsequent record will have a value incremented by 2. Finally, we insert 5 random records into the Students table.
Now if you select all the records from the Students table, you will see that Id column will contain a sequence of values starting at 2 and incremented by 2 in each row. Execute the following script:
SELECT * FROM Students
The output looks like this:

You can see that the first record has an id value of 2 while the 5th has a value of 10.
Now, suppose one of the students leaves the school and we want to delete his record. We can do so using a simple DELETE statement. Let’s delete the record of Jon:
DELETE FROM Students WHERE StudentName = 'Jon'
Now if you again look at all the records in the Students table using SELECT statement, you will see the following output:
SELECT * FROM Students

You can see from the output that record of the student “Jon” with Id 6 has been deleted.
Now let’s try to insert a record of a new student and see what Id it gets:
INSERT INTO Students VALUES ('Jessica', 27 )
The above script inserts a record of a new student named “Jessica”, aged 27, to the Students table.
To see the Id assigned to the Jessica, again retrieve all records from the Students table using the SELECT statement as shown below:
SELECT * FROM Students
The output looks like this:
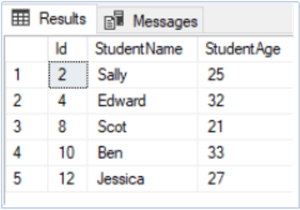
You can see from the output that Jessica has been assigned the Id 12 instead of the Id 6 vacated by Jon. The reason for this behavior is the fact that by default IDENTITY column assigns a value to a new record by adding the step to previous maximum value in the column instead of filling the vacant values in the column. Since the previous maximum value in the Id column was 10, therefore Jessica is assigned 12, since the step is 2.
Depending upon the business rules of the application being developed, this behavior can be correct. For instance, a School may have a rule that even if a student leaves the school, his/her Id cannot be assigned to a new student. On the other hand, there can be a school that reassigns the Id of a student who leaves the school, to a new student.
Manually Insert Record with specific ID value
In the latter case, one of the solutions is to manually insert the Id value for the new student.
Let’s try to add a record of a new student and manually set the value for the Id column to 6 as shown below:
INSERT INTO Students VALUES (6, 'Nick', 22 )
The above script inserts a record of a new student named “Nick”, aged 22, and Id 6, to the students table. When you try to execute the above script, an error will be thrown which looks likes this:
An explicit value for the identity column
in table 'Students' can only be specified when a column list is used
and IDENTITY_INSERT is ON.
In simple words, the error says that since the flag IDENTITY_INSERT is off for the Id column, we cannot manually insert any values. Another important consideration is that we need to specify the column names as well while inserting data to IDENTITY column.
If we try to just specify the column names as mentioned in the above error message as follows:
INSERT INTO Students(Id, StudentName, StudentAge) VALUES (6, 'Nick', 22 )
We get this error message.
Cannot insert explicit value for identity
column in table ‘Students’ when IDENTITY_INSERT is set to OFF.
To manually insert a new value into the Id column, we first must set the IDENTITY_INSERT flag ON as follows:
SET IDENTITY_INSERT Students ON;
To set the IDENTIT_INSERT flag ON we need to use the SET statement followed by the flag name and the name of the table.
Now if we again try to insert the record of the student “Nick” with Id 6, no error will be thrown. Execute the following statement again:
INSERT INTO Students(Id, StudentName, StudentAge) VALUES (6, 'Nick', 22 )
You can see that we have specified the name of the columns as well for inserting a record.
Now again use SELECT statement to retrieve all records from students table in order to view if our new record has been inserted or not. The SELECT statement will return the following records.
SELECT * FROM Students

You can see from the output that record of a new student named “Nick”, aged 22, and Id 6 has been inserted to the Students table.
Try Inserting Duplicate Values
If we try to insert duplicate values as follows:
INSERT INTO Students(Id, StudentName, StudentAge) VALUES (6, 'Nick', 22 )
We will get this error, since ID is the primary key for the table which has to be a unique value.
Violation of PRIMARY KEY constraint ‘PK__Students__3214EC071AD8EC3F’. Cannot insert duplicate key in object ‘dbo.Students’. The duplicate key value is (6).
The statement has been terminated.
Note, that if the ID column was not a Primary Key we would be able to insert duplicate records.
Turn IDENTITY INSERT off
When you SET INDENTITY_INSERT ON it will stay on for the entire session (the time the query window is open). So once this is set you can insert as many records as you want. Also, this only applies for the session where this is turned on, so if you open another query window you would need to set this ON for that query window.
To turn off this option for the session, you would issue the following statement.
SET IDENTITY_INSERT Students OFF;
Next Steps
- In this article, we saw that how we can use the SET IDENTITY_INSERT flag as ON in order to insert a record in the IDENTITY column which is not possible with default settings.
- Check out these related articles:

Ben is the owner of Acuity Training an IT training business based in the UK. Acuity offers a wide variety of IT training courses including a full range of SQL training. These range from introductory querying courses through to advanced administration and BI courses. He is a relatively recent convert to MSSQL Server and been working with it for 6 years. He was a previously a venture capitalist investing in software businesses for a number of years and before that a banker and accountant. He blogs occasionally on a variety of IT related topics at Acuity’s blog.
perfect