Problem
In this tip we compare Serializable and Snapshot transaction isolation levels. Both Serializable and Snapshot isolation levels exclude concurrency issues such as Dirty Reads, Non-repeatable Reads and Phantoms – which are also called phenomena in a RDBMS. Moreover, none of the other isolation levels (Read Uncommitted, Read Committed and Repeatable Read) prevent the mentioned phenomena.
However, Serializable and Snapshot isolation levels avoid these issues in quite different ways. We will explain the differences between snapshot and serializable isolation levels and illustrate with examples. It is assumed that you are familiar with the main concepts of database isolation (database engine isolation levels, transaction phenomena and so on).
Solution
Let’s see this with an example, so we will first create database TestDB and table TestTable:
USE master GO CREATE DATABASE TestDB GO USE TestDB GO CREATE TABLE TestTable ( ID INT, DateChanged DATETIME DEFAULT GETDATE() ) INSERT INTO TestTable(ID) VALUES (1),(2),(3)
SQL Server Serializable Isolation Test
Serializable isolation level provides full data consistency. It means that SELECTs in a transaction with serializable isolation level can read only committed data (eliminating dirty reads), in addition issuing the same SELECT statement more than once in the current transaction we will receive the same values for the rows that have already been read in this transaction (eliminating non-repeatable reads), moreover the number of rows returned by the same SELECT statement will be the same during the transaction (eliminating phantoms).
Serializable isolation level achieves this consistency by placing a range lock or table level lock during the transaction, so other transactions cannot change data used by this transaction. The locks are held until the transaction completes.
Now, in TestDB database we start a transaction with Serializable isolation level:
--Query 1 USE TestDB GO SELECT @@SPID AS ProcessID SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRANSACTION SELECT * FROM TestTable SELECT GETDATE() AS 'Time T1' WAITFOR DELAY '00:00:10' SELECT * FROM TestTable SELECT GETDATE() AS 'Time T3' ROLLBACK
While the transaction is running, we open a new query window and run “Query 2”:
--Query 2 --Execute while "Query 1" is running USE TestDB GO SELECT @@SPID AS ProcessID INSERT INTO TestTable(ID) VALUES (4),(5) SELECT ID, DateChanged AS 'Time T4' FROM TestTable WHERE ID IN (4,5)
While “Query 1” and “Query 2” are still running, we run “Query 3” in a new query window to monitor locks:
--Query 3
--Execute while "Query 1" is running
USE TestDB
GO
SELECT OBJECT_ID('TestTable') AS TestTableID
GO
sp_lock
SELECT GETDATE() AS 'Time T2'
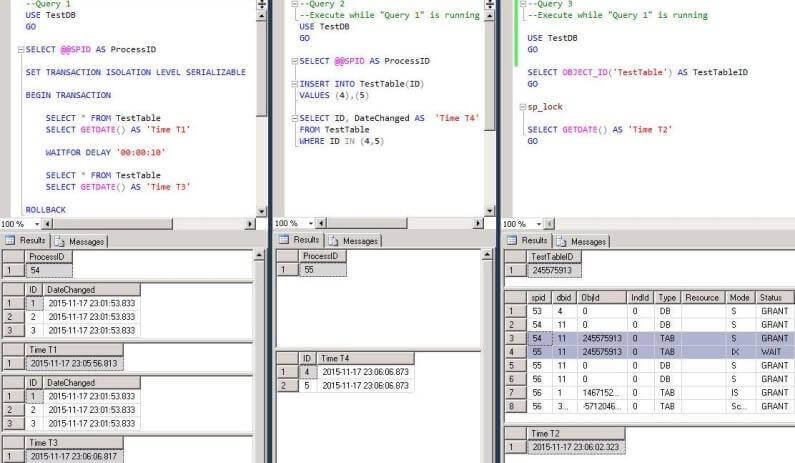
GOWe can see that “Query 2” finishes only after “Query 1” is finished and ‘Time T4’ which is the data insertion time into TestTable is greater than ‘Time T3’. Therefore “Query 2” waits for the transaction in “Query 1” to finish and only then inserts the data. In other words, the transaction in “Query 1” locks the table during the whole transaction (it doesn’t release the lock after the first SELECT statement finishes) and releases only when the transaction is finished. After that “Query 2” is able to insert rows into the table.
We can see in the result set for “Query 3” that “Query 1” places a shared lock on TestTable (the transaction only reads the data, so the lock is shared, in the case of an insert or update the lock will be exclusive) and “Query 2” waits to place an Intent Exclusive (IX) lock:
SQL Server Snapshot Isolation Test
As opposed to Serializable isolation level, Snapshot isolation level does not block other transactions from accessing the rows that are used by the transaction, thus reducing concurrency problems. It uses row versioning to provide data consistency. It means that when a row is changed by another transaction, the old version of that row is stored in the tempdb database and the current transaction sees the modified data as it was when the transaction started. In other words, the transaction with Snapshot isolation level can see only changes which have been committed before the transaction starts and any changes which have been made by other transactions after the start of the current transaction are invisible to it.
Now we will illustrate the behavior of a transaction with snapshot isolation level. First we must set ALLOW_SNAPSHOT_ISOLATION option to ON, to be able to use Snapshot isolation level in the database. We execute “Query 4” and while it is running and before the second SELECT statement will start executing, we execute “Query 5” and after that ( while “Query 4” is still running ) we run “Query 6” to monitor locks.
--Query 4 USE master GO ALTER DATABASE TestDB SET ALLOW_SNAPSHOT_ISOLATION ON USE TestDB GO SELECT @@SPID AS ProcessID SET TRANSACTION ISOLATION LEVEL SNAPSHOT BEGIN TRANSACTION SELECT * FROM TestTable SELECT GETDATE() AS 'T1' WAITFOR DELAY '00:00:10' SELECT * FROM TestTable SELECT GETDATE() AS 'T3' ROLLBACK
Inserting the data while “Query 4” is running:
--Query 5 --Execute while "Query 4" is running USE TestDB GO SELECT @@SPID AS ProcessID INSERT INTO TestTable(ID) VALUES (6),(7) SELECT ID, DateChanged AS 'Time T4' FROM TestTable WHERE ID IN (6,7)
Monitoring locks:
--Query 6
--Execute while "Query 4" is running
USE TestDB
GO
SELECT OBJECT_ID('TestTable') AS TestTableID
GO
sp_lock
SELECT GETDATE() AS 'Time T2'
GOAs we can see “Query 5” has not been blocked by “Query 4”. It successfully inserts the data, however these new rows are not visible for statements in transaction in “Query 4”. Comparing the completion times we can see that data was inserted between SELECT statements for the transaction, however both SELECT statements return the same result. Moreover, we can see that there are no locks on data which is used by our transaction:
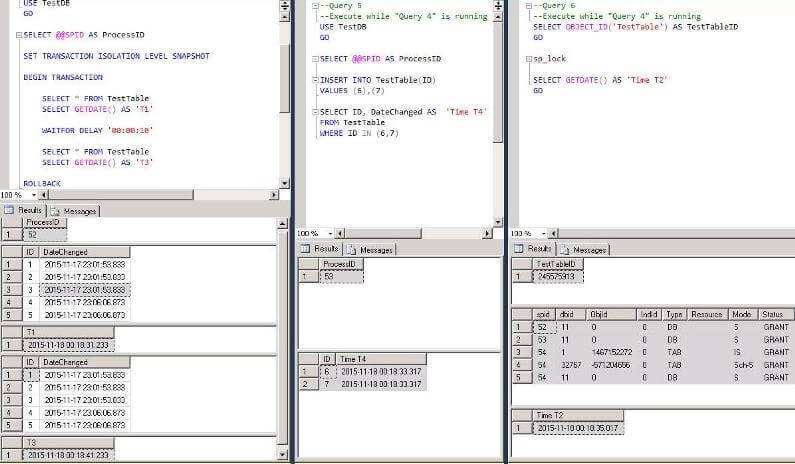
Now let’s see what will happen when we try to update a row in a transaction with Snapshot isolation level which has been already updated by another transaction, after the start of the first transaction. We start “Query 8” after “Query 7” starts and while the latter is still in progress:
--Query 7 USE TestDB GO SET TRANSACTION ISOLATION LEVEL SNAPSHOT BEGIN TRANSACTION SELECT * FROM TestTable SELECT GETDATE() AS 'T1' WAITFOR DELAY '00:00:10' UPDATE TestTable SET ID=9 WHERE ID=5 SELECT GETDATE() AS 'T3' COMMIT
--Query 8 --Execute while "Query 7" is running USE TestDB GO UPDATE TestTable SET ID=8 WHERE ID=5 SELECT GETDATE() AS 'Time T2'
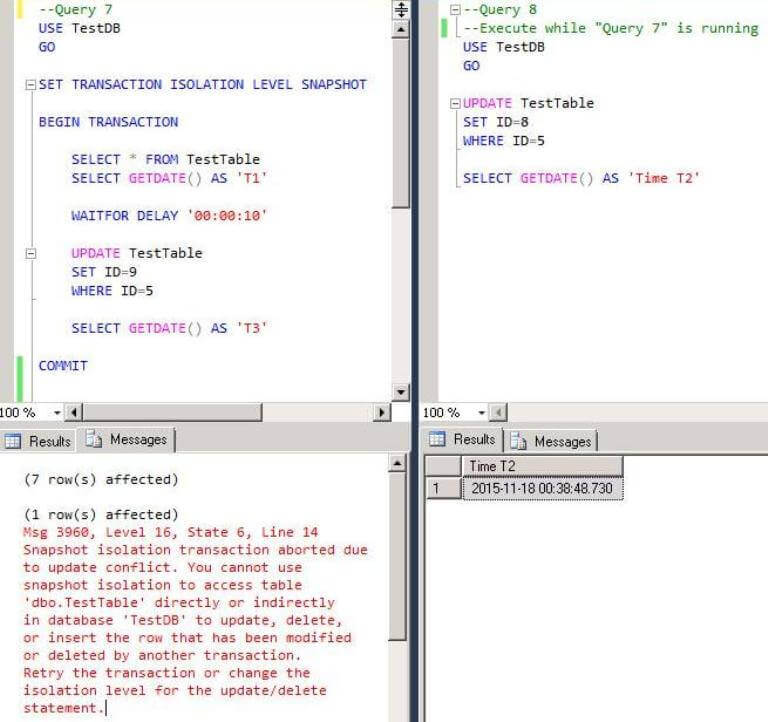
As a result we receive an error which notes that it is not possible to modify the row which has already been modified by another transaction which was committed after the start of the transaction with Snapshot isolation level:
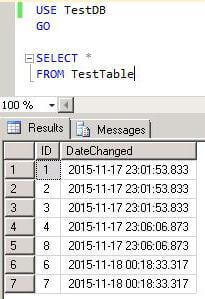
And we can see that the row with ID equal to “5”, now becomes “8”:
USE TestDB GO SELECT * FROM TestTable
But if we change the order of the SELECT and UPDATE statements in “Query 7” and then try to update a row with another transaction we can see that the second transaction waits until the first finishes and then starts the update:
--Query 9 USE TestDB GO SET TRANSACTION ISOLATION LEVEL SNAPSHOT BEGIN TRANSACTION SELECT @@SPID AS ProcessID UPDATE TestTable SET ID=9 WHERE ID=8 SELECT GETDATE() AS 'T1' WAITFOR DELAY '00:00:10' SELECT * FROM TestTable SELECT GETDATE() AS 'T3' COMMIT
--Query 10 --Execute while "Query 9" is running USE TestDB GO SELECT @@SPID ProcessID UPDATE TestTable SET ID=10 WHERE ID=8 SELECT GETDATE() AS 'Time T2'
--Query 11
--Execute while "Query 9" is running
USE TestDB
GO
SELECT OBJECT_ID('TestTable') AS TestTableID
GO
sp_lock
SELECT GETDATE() AS 'Time T2'
GO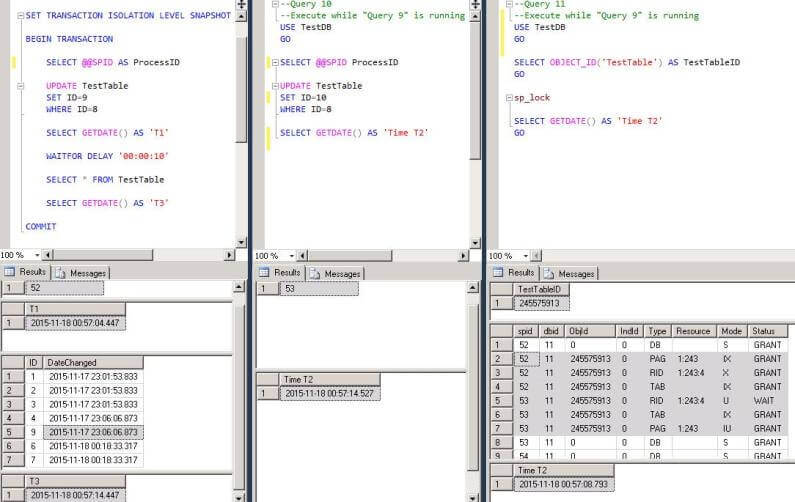
As a result, the updated value is 9, which is updated by the transaction with snapshot isolation level, and the second transaction cannot find the row equal to 8, therefore nothing is updated by it:
USE TestDB GO SELECT * FROM TestTable

The result of “Query 11” shows, that locks are placed by the first transaction and the second waits to place an Update lock. It is important to understand that in the case of snapshot isolation level, writes do not block reads and reads do not block writes, but writes block each other.
Test Using the Same SQL Server Isolation Levels for Both Sessions
Now we will illustrate one more difference between Snapshot and Serializable isolation levels. In the previous examples the second query which is running while the first one is in progress, uses the default isolation level – Read Committed. Let’s see the transactions behavior when both transactions use the same isolation level – Snapshot or Serializable. First, we will update the data using two transactions with Snapshot isolation level and see what happens.
Let’s truncate TestTable and insert two rows:
USE TestDB GO TRUNCATE TABLE TestTable INSERT INTO TestTable(ID) VALUES (1), (2)
We run the first transaction with Snapshot isolation level and while it is in progress, we start the second also using Snapshot isolation level:
--Query 12 USE TestDB GO SET TRANSACTION ISOLATION LEVEL SNAPSHOT BEGIN TRANSACTION UPDATE TestTable SET ID= 2, DateChanged=GETDATE() WHERE ID=1 SELECT GETDATE() AS 'Time T1' WAITFOR DELAY '00:00:10' SELECT GETDATE() AS 'Time T3' COMMIT SELECT * FROM TestTable
--Query 13 USE TestDB GO SET TRANSACTION ISOLATION LEVEL SNAPSHOT BEGIN TRANSACTION UPDATE TestTable SET ID = 1, DateChanged=GETDATE() WHERE ID= 2 SELECT GETDATE() AS 'Time T2' COMMIT

From the result we can that “Query 12” updated the row with ID=1 to ID=2. After that, “Query 13” updated the row with ID=2 to ID=1, but for this transaction there was only one row with ID=2, because the transaction read from the snapshot and the row which was updated by “Query 12” was not visible to this transaction.
In the case of transactions using Serializable isolation level, the result is different.
USE TestDB GO TRUNCATE TABLE TestTable INSERT INTO TestTable(ID) VALUES (1), (2)
We run “Query 14”:
--Query 14 USE TestDB GO SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRANSACTION UPDATE TestTable SET ID= 2, DateChanged=GETDATE() WHERE ID=1 SELECT GETDATE() AS 'Time T1' WAITFOR DELAY '00:00:10' SELECT GETDATE() AS 'Time T3' COMMIT SELECT * FROM TestTable
While “Query 14” is in progress, we run “Query 15”
--Query 15 USE TestDB GO SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRANSACTION UPDATE TestTable SET ID = 1, DateChanged=GETDATE() WHERE ID= 2 SELECT GETDATE() AS 'Time T2' COMMIT

The result shows that in this case the table was updated only by the first transaction and a deadlock occurred. The reason for the deadlock is that both transactions wait for each other to update the same data.
Conclusion
As we can see Serializable and Snapshot isolation levels protect against all phenomena, however they achieve it by different methods. We should consider that using Serializable isolation level can cause concurrency problems, because it uses locks to achieve full data consistency. In case of Snapshot isolation level we avoid more locking and blocking, however, as old versions of rows are stored in tempdb database more storage is needed and it increase some overhead.
Next Steps
- SET TRANSACTION ISOLATION LEVEL (Transact-SQL)
- Transaction Isolation Levels
- Isolation Levels in the Database Engine

Sergey Gigoyan (LinkedIn) is a Senior Technical Architect specializing in data and databases with more than 15 years of experience. Sergey focuses on modern data architectures, database design and development, performance tuning and optimization, high availability solutions, BI development and DW design. He has worked with SQL Server, Oracle, and PostgreSQL databases, as well as cloud-based data solutions (AWS and Azure). Sergey also has extensive experience with modern data stacks such as Snowflake and dbt.
Sergey’s experience spans various industries. He had the privilege of working with IT giants such as Oracle as a Principal Data Engineer and BlackBerry as well as innovative startups. He helped deliver complex database solutions and advanced data strategies.
Sergey is also the author of “Building a Successful Career in IT – How I Did It” where he provides actionable advice on thriving in the ever-evolving IT industry.
- MSSQLTips Awards: Champion (100+ tips) – 2024 | Author of the Year – 2020


