Problem
Referential integrity is a set of rules that enforces a relationship between data in tables and is aimed at keeping SQL Server databases consistent. Usually referential integrity is implemented by using foreign key constraints, however there can be situations when it is not possible to create a foreign key constraint and we need to find alternate ways to enforce referential integrity. In this article we will investigate solutions for implementing referential integrity other than foreign keys.
Solution
Assume a situation when two tables are related to each other with logical rules which cannot be enforced by a foreign key constraint. These rules can be checked in code, but this may not be the best solution because the data can be changed directly in the table or modified from different parts of code, hence creating possible issues if the code is not kept consistent. So, we will not discuss this approach and concentrate on two others: enforcing referential integrity using check constraints with user defined functions and the second approach – using triggers.
Let’s see an example.
Suppose we have a UserList and AdvancedUserList tables in database TestDB. Advanced users have additional attributes, so they are stored in a separate table. In our example a user is considered advanced only when the value of the UserType column in the UserList table equal to 1. In other words, all users that exist in the AdvancedUserList table must exist in the UserList table as well the value of their UserType column in the UserList table must equal 1. We cannot enforce this rule by using a foreign key, because in this way we would not be able to eliminate insertion of users with a type other than 1 into the AdvancedUserList table.
Let’s create a test environment to demonstrate:
USE master GO CREATE DATABASE TestDB GO USE TestDB GO CREATE TABLE UserList ( UserID INT, UserType INT NOT NULL, CONSTRAINT PK_UserList_UserID PRIMARY KEY CLUSTERED (UserID) ) GO CREATE TABLE AdvancedUserList ( UserID INT, UserRank INT, CONSTRAINT PK_AdvancedUserList_UserID PRIMARY KEY CLUSTERED (UserID) ) GO INSERT INTO UserList(UserID, UserType) VALUES(1,1),(2,1),(3,2),(4,3),(5,3) GO
We will use these tables to illustrate our solutions with examples. Let’s investigate each solution in detail.
Enforcing SQL Server Referential Integrity using a User Defined Function and Check Constraint
This approach allows us to enforce that the data in the column of the second table will be the subset of filtered data in the first table (users in the second table are the subset of users with UserType = 1 in the first table). First of all we will create a user defined function which checks the existence of the given parameter among UserIDs with UserType = 1 in UserList table. Secondly, we will create a check constraint on the AdvancedUserList table which uses the mentioned function to check if any user in the AdvancedUserList table has a UserType value equal to 1 in the UserList table.
USE TestDB GO --Creating function for check constraint CREATE FUNCTION udfCheckUserID ( @pUserID INT ) RETURNS TINYINT AS BEGIN IF EXISTS ( SELECT UserID FROM AdvancedUserList WHERE @pUserID IN (SELECT UserID FROM UserList WHERE UserType=1) ) RETURN 1 RETURN 0 END GO --Creating check constraint which uses the function ALTER TABLE AdvancedUserList ADD CONSTRAINT CheckUserID CHECK(dbo.udfCheckUserID(UserID)=1)
By running the following script we can check how our enforcement works:
USE TestDB GO INSERT INTO AdvancedUserList(UserID, UserRank) VALUES (1,100), (2,100) INSERT INTO AdvancedUserList(UserID, UserRank) VALUES (3,100) SELECT * FROM AdvancedUserList
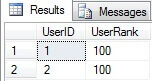
We can see that only the first INSERT statement succeeds, because for users with UserID=1 and UserID=2, the UserType value for these two rows is equal to 1 in the UserList table. But for the user with UserID=3, the UserType value is equal to 2, so the check constraint does not allow us to insert this user’s data into the AdvancedUserList table:

As a result, the AdvancedUserList table contains only two rows:
Altering a SQL Server User Defined Function when it is used as a Check Constraint
It is important to mention some essential points of this solution. Firstly, if the function is used by a check constraint, it cannot be altered. Below you see the error message if we try to ALTER this function.
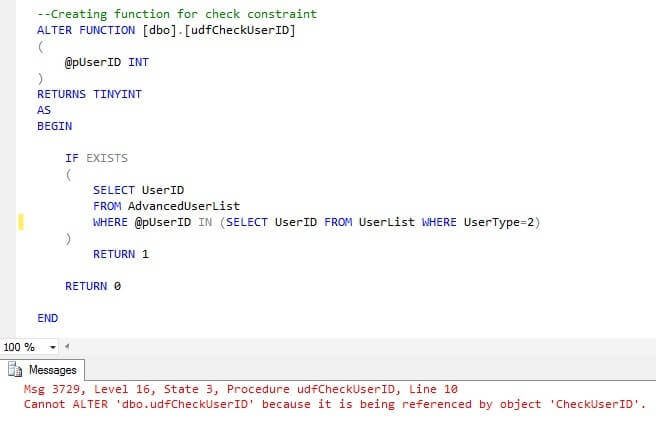
To modify the function, we need to drop the check constraint first, alter the function and then recreate the check constraint.
Referential Integrity Not Fully Enforced with User Defined Function Check Constraint
However the most important point of this approach is that it does not fully enforce referential integrity. It does not deny data deletion from the first-parent table, which also exists in the second table:
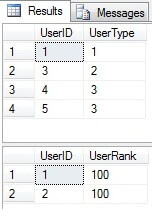
Use TestDB GO --Deleting user from UserList table which exists in AdvancedUserList table DELETE FROM UserList WHERE UserID=2 SELECT * FROM UserList SELECT * FROM AdvancedUserList
The user from the UserList table is successfully deleted despite the fact that it exists in the AdvancedUserList table:
Moreover we cannot a create check constraint on the UserList table which will deny deletion of records existing in the AdvancedUserList table, because during DELETE statements check constrains are not validated. In case of foreign keys we can define what action should be taken when data is deleted or updated in the parent table. By default it is “NO ACTION” which means when a referenced row is deleted (updated) from the parent table the database engine raises an error and the transaction is rolled back.
In the current example it is possible to use a foreign key and check constraint together: we can create a foreign key on table AdvancedUserList which enforces users in this table to be a subset of users in the UserList table. This will eliminate the deletion of referenced rows from the UserList table and the check constraint ensures insertion of only advanced users into the AdvancedUserList table (only users with UserType=1).
However there could be situations when the creation of a foreign key is not possible. For example, when related columns, unlike our example, have a large varchar data type and the creation of unique index is not possible. It is also a possible case that we may need to implement referential integrity when data in the second table is referred to data from more than one table.
So, generally this approach solves our problem partly. It ensures referential integrity only when data is inserted into the second table. If further modifications of existing referenced rows in the parent table are possible, the referential integrity will be damaged.
Enforcing SQL Server Referential Integrity using Triggers
Now we will use triggers to enforce referential integrity.
In the following code we drop the constraint on the AdvancedUserList table, reinitialize the data and create a trigger on the AdvancedUserList table:
USE TestDB --Dropping the check constraint ALTER TABLE AdvancedUserList DROP CONSTRAINT CheckUserID GO --Reinitializing data TRUNCATE TABLE AdvancedUserList TRUNCATE TABLE UserList GO INSERT INTO UserList(UserID, UserType) VALUES(1,1),(2,1),(3,2),(4,3),(5,3) GO --Creating the trigger CREATE TRIGGER trgCheckUserIDAdvancedUserList ON AdvancedUserList AFTER INSERT, UPDATE AS BEGIN IF EXISTS ( SELECT UserID FROM inserted WHERE UserID NOT IN (SELECT UserID FROM UserList WHERE UserType=1) ) ROLLBACK TRANSACTION END
This trigger ensures that any insert or update into the AdvancedUserList table will be rolled back if the inserted (updated) UserID doesn’t exist in the UserList table where UserType=1:
USE TestDB INSERT INTO AdvancedUserList(UserID, UserRank) VALUES (1,100), (2,100) INSERT INTO AdvancedUserList(UserID, UserRank) VALUES (3,100) GO SELECT * FROM AdvancedUserList
The result shows that the last insert is rolled back in the trigger, because for user with UserID=3 the UserList table has UserType = 2:

Therefore only two rows are inserted into the AdvancedUserList table:

To eliminate deleting rows from the UserList table that exist in the AdvancedUserList table we will create a trigger on the UserList table as well:
USE TestDB CREATE TRIGGER trgCheckUserIDUserList ON UserList AFTER DELETE AS BEGIN IF EXISTS ( SELECT UserID FROM deleted WHERE UserID IN (SELECT UserID FROM AdvancedUserList) ) ROLLBACK TRANSACTION END
Let’s try to delete rows from the UserList table:
SELECT * FROM UserList SELECT * FROM AdvancedUserList DELETE FROM UserList WHERE UserID=5 DELETE FROM UserList WHERE UserID=2 GO SELECT * FROM UserList SELECT * FROM AdvancedUserList
The row with UserID=5 is successfully deleted, because this user doesn’t have data in the AdvancedUserList table. However deletion of row with UserID=2 is rolled back in the trigger, because it exists in the AdvancedUserList table:

As we can see the row with UserID=5 has been successfully deleted:

So, unlike the first approach, using triggers we will not only ensure that data in the column of the second table will be the subset of the data in the corresponding column of the first table, but it also eliminates deletion of referenced data in the first (parent) table.
Conclusion
In conclusion, besides using foreign keys there are other ways to implement referential integrity. Moreover in some cases using foreign keys is impossible, so we need to choose alternatives. Using check constraints with user defined function is one approach, but it does not offer a full solution to ensuring data integrity. Implementing referential integrity using triggers is also a solution and in this way we can enforce full integrity.
Next Steps
Read this related information:
- Constraint Tips
- FOREIGN KEY Constraints
- Unique Constraints and Check Constraints
- Primary and Foreign Key Constraints

Sergey Gigoyan (LinkedIn) is a Senior Technical Architect specializing in data and databases with more than 15 years of experience. Sergey focuses on modern data architectures, database design and development, performance tuning and optimization, high availability solutions, BI development and DW design. He has worked with SQL Server, Oracle, and PostgreSQL databases, as well as cloud-based data solutions (AWS and Azure). Sergey also has extensive experience with modern data stacks such as Snowflake and dbt.
Sergey’s experience spans various industries. He had the privilege of working with IT giants such as Oracle as a Principal Data Engineer and BlackBerry as well as innovative startups. He helped deliver complex database solutions and advanced data strategies.
Sergey is also the author of “Building a Successful Career in IT – How I Did It” where he provides actionable advice on thriving in the ever-evolving IT industry.
- MSSQLTips Awards: Champion (100+ tips) – 2024 | Author of the Year – 2020