Problem
SQL Server has many features that assist with providing the best query performance and one of these features is read ahead reads or prefetching. In this tip we look at how this relates to SQL Server query performance and if there is an impact to query performance.
Solution
SQL Server tries to respond to a user’s query as quickly as possible. To achieve this, SQL Server tries hard at multiple levels of operation to make the query plan efficient. However, most of the performance related work done by the query optimizer is to get the best access method of the data, like what join is best, which physical join type is appropriate, should it scan or seek the index, etc. Even if the query optimizer comes up with the best execution method, the query can still suffer because there could be a considerable CPU or I/O performance gap, to reduce some of this SQL Server uses the read ahead read mechanism.
The read ahead mechanism is SQL Servers ability to bring data pages into the buffer cache even before the data is requested by the relational engine. Whenever the relational engine asks for rows from the storage engine, it first looks for those pages that contain the rows in the buffer cache. If not found, it then copies those pages from physical storage to the buffer cache. The storage engine can anticipate that more pages might be required by the relational engine and it initiates the read ahead read mechanism. There are two read ahead read mechanisms; sequential read ahead reads and random prefetching.
A sequential read ahead read tries to read pages in a specific order either in allocation order or index order. Heaps are always scanned in the allocation order as heaps don’t store data in any specified order. Indexes scan in the key order on which they are sorted, unless it’s running on the read uncommitted isolation level or the nolock hint is used and the relation engine doesn’t ask for an ordered scan. SQL Server supports random IOs as well. On a conventional rotating disk, random IOs are much slower than sequential IOs, thus for better performance throughput it has to support read ahead reads, which is called random prefetching.
Usually random IOs are generated by a nested loop join physical join type. In a nested loop join the outer table generates random IOs to the inner table for the matching rowset. In a nested loop join prefetching is only enabled if the outer table’s estimated number of rows is more than 25. Random prefetching can be further categorized as ordered and unordered prefetching.
Let’s try to understand RAR (Read Ahead Read) with examples, that we will build a test table with some random data. To view the read ahead read phenomena we will enable statistics IO when we run the queries. Also, I will run DBCC DROPCLEANBUFFERS to flush all the data pages before each run, so the read ahead reads take place.
Note: DBCC DROPCLEANBUFFERS is not recommended on production servers, unless there is an absolute need. Running this command flushes the buffer cache.
Build Test Data
CREATE TABLE DBO.TestTable ( ID int IDENTITY (1, 1) NOT NULL, IDvarchar AS CAST(ID AS varchar(50)) PERSISTED NOT NULL, intcolumn int, NAME varchar(50) NOT NULL, Age int NOT NULL, Randomvalue bigint ); INSERT INTO TestTable (intcolumn, NAME, AGE) SELECT s1.number, 'Some Random Data..', s1.number % 10 + 25 FROM master.dbo.spt_values s1 CROSS JOIN master.dbo.spt_values s2; UPDATE TestTable SET Randomvalue = CAST(RAND(CHECKSUM(NEWID())) * ID AS int); ALTER TABLE TestTable ALTER COLUMN Randomvalue int NOT NULL; CREATE UNIQUE CLUSTERED INDEX CI_TestTable_ID ON DBO.TestTable (ID)
SQL Server Read Ahead Read Example
Now that the test data has been built, we can start the test.
In the below query, we will first clean the buffer cache by using DBCC DROPCLEANBUFFERS, so there will be nothing in the buffer cache and the reads will be physical reads, so read ahead reads can take place.
To check whether the read ahead read mechanism occurred, we will can check the output of statistics io. Look at the read-ahead reads information below, we can see that 2 read-ahead read pages were brought into the buffer pool.
DBCC DROPCLEANBUFFERS;SET STATISTICS IO ON; SELECT * FROM TestTable WHERE ID <300; --Table 'TestTable'. Scan count 1, logical reads 5, physical reads 1, read-ahead reads 2, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Now run the same query again without clearing the buffer cache. There is no need for read ahead reads, because those pages are already in the buffer pool.
SET STATISTICS IO ON;SELECT * FROM TestTable WHERE ID <300; --Table 'TestTable'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Now run another query with a different value. The query is asking for different data pages which are not in the buffer cache already, so the RAR mechanism started and placed those pages into the buffer pool.
SELECT * FROM TestTable WHERE ID <600; --Table 'TestTable'. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 2, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0
SQL Server Random Prefetching Example
Now we will try to understand random prefetching with some examples. For this we need to build another table with some random data. Random prefetching can be experienced with a nested loop join, thus I will force the optimizer to choose a nested loop join so if you are testing this you will get the same physical join type.
SELECT * INTO Testtable2 FROM TestTable t1;CREATE unique clustered INDEX ix_id_testtable2 ON testtable2 (IDvarchar);
CREATE unique INDEX ix_IDVARCHAR ON testtable2 (IDvarchar);
DBCC DROPCLEANBUFFERS;
SET STATISTICS IO ON;
SELECT *
FROM TestTable t1
WHERE IDvarchar IN
(SELECT IDvarchar
FROM testtable2 t2)
AND ID < 27
OPTION (loop join);
--Table 'Testtable2'. Scan count 0, logical reads 143, physical reads 1, read-ahead reads 240, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
--Table 'TestTable'. Scan count 1, logical reads 3, physical reads 2, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The statistics io shows there is no read-ahead reads on the TestTable, but there are on TestTable2.
In the execution plan, the outer table, TestTable, estimated rows is 26 thus the random prefetching is enabled for the inner table TestTable2. Prefetching can be confirmed by right clicking on the Nested Loops Inner Join and selecting Properties. In the properties there is a property named WithUnorderedPrefetch which is equal to TRUE.
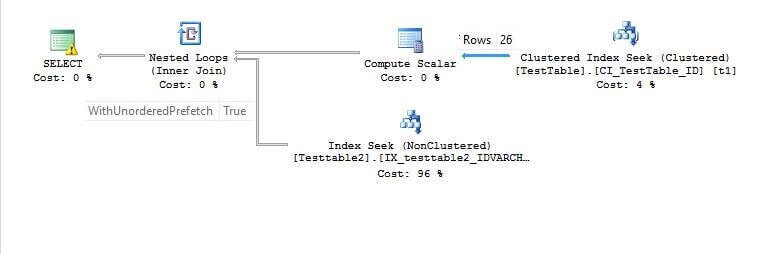
A quick test to see when random prefetching is not enabled is to use a row count less than 26.
DBCC DROPCLEANBUFFERS;
SET STATISTICS IO ON;
SELECT *
FROM TestTable t1
WHERE IDvarchar IN
(SELECT IDvarchar
FROM testtable2 t2)
AND ID < 26
OPTION (loop join);
--Table 'Testtable2'. Scan count 0, logical reads 75, physical reads 30, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
--Table 'TestTable'. Scan count 1, logical reads 3, physical reads 2, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Read-ahead reads don’t occur for either table and we also confirm in the execution plan if we look at the properties for the Nested Loops Inner Join, we can see the WithUnorderedPrefetch property does not exist.

System Under Pressure Test
What happens when the system is heavily used, what kind of performance difference do we get with and without read ahead reads? Also, in our simple tests we were only using one or two tables, so think about the impact when there are more table joins.
To show a system under pressure, we will use diskspd.exe which is Microsoft’s storage subsystem testing tool. We will use this to put pressure on the disk sub-system, so we can understand why the read ahead read mechanism is desirable under disk pressure. To disable the read ahead reads we will use some documented trace flags.
Below I am running diskspd.exe and we can confirm the storage is under pressure by looking at Windows Task Manager.

Now that the disk is under pressure, let’s run some queries with and without read ahead reads.
First we will test the sequential read ahead read. To disable sequential read ahead reads, we will use the documented and supported trace flag 652.
SET STATISTICS IO OFF; SET STATISTICS TIME ON; -------------------------- -- test with trace flags -------------------------- DBCC DROPCLEANBUFFERS; DBCC TRACEON (652); SELECT * FROM TestTable WHERE ID < 300000; PRINT ' RAR disable' --elapsed time = 13978 ms. DBCC TRACEOFF (652); -------------------------- -- test without trace flags -------------------------- DBCC DROPCLEANBUFFERS; SELECT * FROM TestTable WHERE ID < 300000; PRINT ' RAR enabled' --elapsed time = 2587 ms.
On my system after disabling sequential read ahead reads, the query took roughly 14 seconds to execute and with it enabled it took only 2.5 seconds which is a big performance margin.
Now let’s test random prefetching. To disable random prefetching we will use trace flag 8744. This trace flag is also documented and supported. We are forcing the optimizer to choose a loop join, so we all get a Nested Loops join as the physical join. We are also using maxdop = 1 to disable parallelism, so we all get the same execution plan regardless of how many processors your system has.
SET STATISTICS TIME ON;
--------------------------
-- test with trace flags
--------------------------
DBCC DROPCLEANBUFFERS;
DBCC TRACEON (8744);
SELECT *
FROM TestTable t1
WHERE IDvarchar IN
(SELECT IDvarchar
FROM testtable2 t2)
AND ID < 1000
OPTION (RECOMPILE, LOOP JOIN, MAXDOP 1);
PRINT 'prefetching disable' -- elapsed time = 37398 ms.
DBCC TRACEOFF (8744);
--------------------------
-- test without trace flags
--------------------------
DBCC DROPCLEANBUFFERS;
SELECT *
FROM TestTable t1
WHERE IDvarchar IN
(SELECT IDvarchar
FROM testtable2 t2)
AND ID < 1000
OPTION (RECOMPILE, LOOP JOIN, MAXDOP 1);
PRINT 'prefetching enable' -- elapsed time = 2565 ms.
We can see an even more dramatic difference when prefetching is disabled. The query took more than 37 seconds to execute when disabled and only 2.5 seconds when enabled. This is quite a big performance difference.
Read ahead reads are enabled by default, so do we really need to be concerned about this feature? Usually not, unless the scan or seek cardinality estimation is too low compared to the actual cardinality and because of that the read ahead read mechanism is not started which can have a negative impact on query execution.
Next Steps

Neeraj Prasad Sharma is a Dot Net developer, who is amazed by the SQL Server query optimizer. For the last six years he has been experimenting and testing its default behavior and if something goes wrong his goal is to fix it.


