By: Tim Smith | Comments | Related: > In Memory OLTP
Problem
We've been at presentations where people showed us the in-memory table feature in SQL Server and we've considered whether it might be appropriate in an ETL architectural context where we extract and load data into several steps of tables before delivering data to clients, or allowing them to directly report on the data. What are some steps to help us identify if this SQL Server feature might be useful in our ETL architecture?
Solution
Since Microsoft released in-memory tables, I've seen and heard some confusion about when this solution should be applied or considered. Before we consider this feature for our ETL project, let's consider the most sensible purpose of in-memory tables within the architecture.
Example scenarios for and against in memory tables.
When we consider the feature of in-memory tables, we want to consider what tables or what part of our architecture concurrently experiences a significant volume of both reads and writes. The below examples show a contrast between where we'd expect to see this and where we wouldn't:
- A live report showing the temperature changes of the weather in an average location by the minute with one location as the measuring point.
- Production warehouse where the orders determine the type of items produced and where millions of orders are being placed per second.
- Live bids and sales on available homes.
While we could use an in-memory table in all of these examples for the final report table, the first example (weather) would be the least appropriate.
The second example is the most appropriate, as the demand for types of products dictates what products are created, making a delay potentially costly.
In the last example, the benefit depends on the area, turnover rate and number of bids. Another way of looking at whether in-memory tables should be used in architecture is what is the cost from the time the data are received to the time that the data are reported?
A minute-by-minute reporting of the weather only means we write once per minute and the report or reports read that write; it is unlikely that one write per minute will delay reports on those data. In the other case of live orders dictating what products are created when millions of orders are entered per second, the reporting reads of those written orders carries significant costs the longer the delay.
Considerations before switching to an in memory table.
When I consider using in-memory tables for ETL purposes, I consider the following points:
- Is read-write concurrency the bottleneck of the ETL architecture? If I find a read-write contention causing delays, assuming ceteris paribus, this may be a place where in-memory tables can assist. Think of the analogy with a sand timer: both the top and bottom ends can hold a lot of sand, but the middle part limits the amount of sand that can move at any given time. If the bottleneck isn't concurrency, adding in-memory tables is like making the top or bottom parts of a sand timer even larger. This also applies to the overall process; I want to optimize the point of data contention.
- Can I use in-memory tables? In some cases, I can't. Some features are not supported on them, such as replication, DDL triggers, schema changes, etc. Likewise, not all data are supported for in-memory tables, such as geography, image, xml, varchar(max), varbinary(max), sql_variant, and text. Finally, I must consider the hardware of where I am using in-memory tables - I must have the needed resources available.
- How can I delineate this from existing applications or database processes? My own preference with any in-memory table usage is to separate it, if I'm using it for live reporting. The purpose of this is that I can create administrative templates for types of databases, as some administrative features like CHECKDB don't check in memory tables and some monitoring might not be needed for all types of databases.
Techniques for identifying a candidate.
Now that we know the best scenarios for using in memory tables and we're aware of their limitations, we can begin the next step of identifying the candidates:
- Identifying heavily used indexes is one place to start, provided that these tables experience a heavy read volume as well. In the tip, we can identifying indexes not being used, so we can use the same queries to identify the inverse - indexes that experience significant data changes.
- Search our code for the query hint WITH (NOLOCK). The common assumption
underlying this query hint when developers use it often involves read-write
data contention. If we see many procedures, views or reports using this query
hint on tables and we see those table's indexes with frequent data changes,
we may have found a candidate. The below code will loop through SQL files and
find code with either with (nolock) or with(nolock)
- If you have third party software, you can use it to identify blocking or expensive read-write queries where the underlying table is involved in both the read and write contention. If not, you can run traces that may help you identify candidates. Remember that both traces and third party software can come with performance costs.
- Draw or map out the entire ETL flow. In the below image, we identify the "holding table" as the in-memory table candidate because of how the data flow in our design. The ETL loaders move data into smaller tables where scaled data transformations and validations occur to reduce data contention. From these small tables, data are moved into the holding table where either reports execute from (such as live reports), or data are delivered directly to clients - both of these requiring heavy reads. The table receives significant write load from the smaller loading tables while also receiving heavy read load from the live and delivered reports.
$sqlfiles = Get-ChildItem "C:\OurSourcePath\OurSqlFilesPath\" -Filter *.sql -Recurse
foreach ($sqlfile in $sqlfiles)
{
$check = Get-Content $sqlfile.FullName
if (($check.ToLower() -like "*with(nolock)*") -or ($check.ToLower() -like "*with (nolock)*"))
{
$sqlfile.FullName
}
}
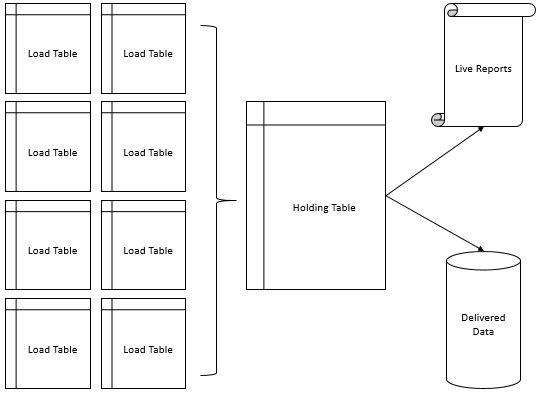
Once we've completed these steps - compare examples where in-memory is appropriate, consider where we may be able to use in-memory tables in our ETL process, and identify pain points, we can begin testing. While I've heard and seen significant performance gains with in-memory tables of up to five multiples in speed, these assume that we've identified the appropriate bottleneck. Using the above image as an example, if our "delivered data" server can't accept data very quickly (ASYNC_NETWORK_IO wait), for that server an in-memory table won't show major performance gains - the receiving server is the bottleneck.
Next Steps
- Always consider your architectural design in the context of your client. If you only deliver reports at timed-intervals and you experience no delay, you may not need to change or add any new feature. On the other hand, if you're experiencing some delays, or you're concerned the data are growing and will cause growing pains, this may be a feature worth testing.
- Consider the limitations of in-memory tables and what these will mean - from data types to features that aren't supported. If you can't live with these limitations, don't proceed.
- Work with the database administration team if you're on the development team, as they will want to create alerting, rules and other monitoring in these environments.
- In my experience, some ETL performance issues are caused by unnecessary migrations of data - such as loading an entire set of data again, when this isn't required (i.e.: "We're going to reload 1 billion records of data" when only 100,000 records changed). In these situations where some data may be changed (and the developer prefers to load it again), an in-memory table might be useful in accepting write updates from the new data, provided that the loaded table of data does not become the bottleneck when submitting new data for updates.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
