Problem
SQL Server 2014 introduces hash indexes for Memory-Optimized tables, but you may not know what they are and the differences between hash indexes and standard SQL Server indexes. Also, you may be asking why there are no clustered indexes on Memory-Optimized tables. Keep reading to find the answers.
Solution
We all know the importance of proper indexing on tables. The introduction of hash indexes for Memory-Optimized tables on SQL Server 2014 brings us new possibilities to achieve maximum performance, but there are some considerations. After reading this tip you will understand the pros and cons of this new type of index.
What is a hash index?
Basically, a hash index is an array of N buckets or slots, each one containing a pointer to a row. Hash indexes use a hash function F(K, N) in which given a key K and the number of buckets N , the function maps the key to the corresponding bucket of the hash index. I want to emphasize that the buckets do not store the keys or its hashed value. They only store the memory address in which the data is placed.
What is a hash function?
A hash function is any algorithm that maps data of variable length to data of a fixed length in a deterministic and close to random way. A very simple hash function would be a string that returns its length, so F(“John”) = 4 and F(“Ed”) = 2. If we define a hash index of 5 buckets using this function then the pointers that point to “John” and “Ed” are stored at buckets 4 and 2 respectively. The following image will help you understand.
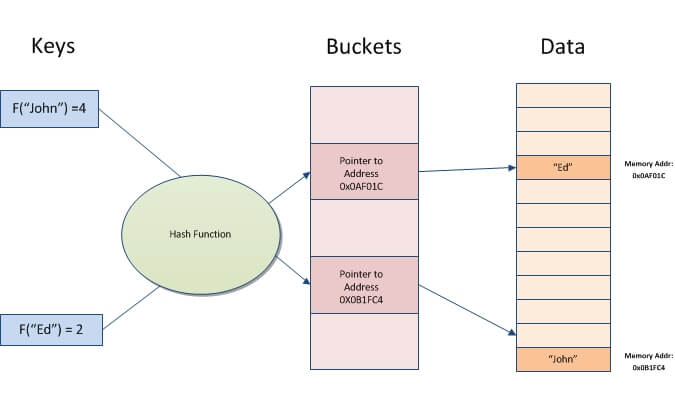
At this point everything seems clear, but what happens when we apply this simple hash function on “Bill”? The length of string “Bill” is 4, so F(“Bill”) = 4 which is the same as F(“John”) = 4. Don’t get confused, the fact that two keys have the same Hash value doesn’t mean the keys are the same. This is called a “collision” and is very common in hash functions. Of course the more collisions a function has the worse a function is because a large number of hash collisions can have a performance impact on read operations. Also collisions may be caused when the number of buckets is too small compared with the number of distinct keys.
SQL Server Hekaton Collision Management
There are many ways to solve hash collisions, but I will focus on how the Hekaton engine handles them.
The way Microsoft has chosen to handle hash collisions is chaining with linked lists. In order to explain this concept I need to show you how data and indexes are organized on Memory-Optimized Tables.
SQL Server Hekaton Hash Indexes and Row Addressing
In my previous tip Overcoming storage speed limitations with Memory-Optimized Tables for SQL Server I briefly explained Hekaton’s structure and now it is time to go deeper.
Memory-Optimized tables consist of two structures: indexes and rows. See image below.

The only way rows are combined into a table is by linking them with index pointers. I mean rows aren’t necessarily stored in an orderly fashion. That’s why clustered index are nonsense. On Memory-Optimized tables space is not pre-allocated. Instead when a row is inserted or updated the Hekaton engine allocates space from RAM’s heap on the fly. Also you won’t find covering indexes because for Memory-Optimized tables all indexes are inherently covered.
SQL Server Hekaton Row Header
To make it simple to understand I will omit some fields of the row header and will focus only on those that are more relevant for this tip.
As the default isolation level for Memory-Optimized tables is SNAPSHOT, it is easy to understand why the row header keeps timestamps of the rows in order to handle optimistic multiversion concurrency.
For new transactions a row is valid if the end timestamp is set to the special value referred as “infinity”.
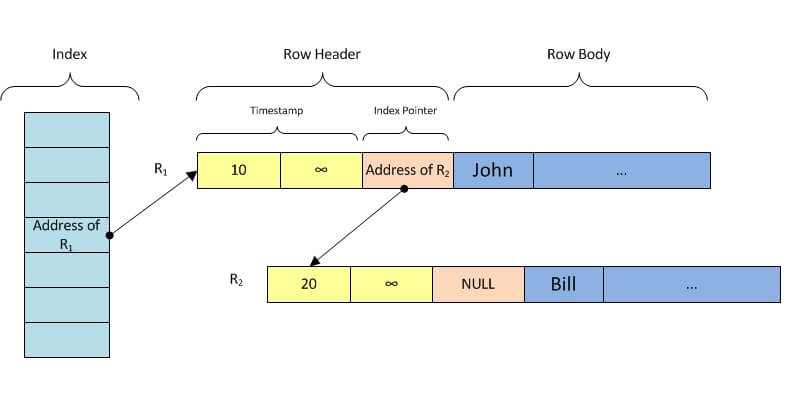
Remember when I told you about chaining to solve collisions? That’s when index pointers for a row header come to light. When a row is inserted and hashes to a non-empty bucket Hekaton links the new row to the existing one by setting a pointer to the new row on the existing one.
Coming back to the previous example, suppose that at timestamp T0 = 10 we insert a row R1 with “John” as the key that maps to bucket number 4.

Then at timestamp T1 = 20 we insert a new row R2 with “Bill” as the key that also maps to bucket number 4. To handle this hash collision Hekaton will set a pointer on R1 to R2. See the next image to get a clearer vision of this scenario.
SQL Server Hekaton Row Chaining and Multiversioning
Now consider that we have the same row R1 whose key hash maps to bucket 4 at timestamp T0 = 10. Next at timestamp T2 = 30 the row R1 is updated. As I told you in my previous tip about Memory-Optimized tables, Hekaton handles updates as a delete followed by an insert, so updates don’t modify the existing row data; instead, the engine sets the row end timestamp to T2 which makes the row outdated for new transactions and inserts a new row, R3 containing the updated data with a begin timestamp equal to T3. Look at the image below for a graphical explanation.

Now putting it all together: whenever a row’s key matches an occupied bucket, either if it is a new row or an updated one, it is linked at the end of the pointer chain of the matching bucket.
This brings up this question: How does the engine identify the proper row?
SQL Server Hekaton Row Identification
Suppose we perform the following SELECT statement on a Hash indexed table.
SELECT * FROM Customer WHERE CustomerId = 'John'
To identify this row in a Hash indexed table by an INDEX SEEK operation the Hekaton engine uses the following algorithm:
1 – Calculate the bucket in which the key, if exists, should be stored.
To do so, the Engine applies the Hash function H(x) to the search predicate “John”, so H(“John”) = h. Then, to get the bucket number (a number between 0 and BUCKET_COUNT − 1) Hekaton calculates the remainder of the division between h and the number of buckets. So:
Bucket = H(“John”) % BUCKET_COUNT
If you wonder why Hekaton rounds the number of buckets specified on BUCKET_COUNT to the next power of two, here lies the answer: if BUCKET_COUNT is a power of two then the modulo operation can be replaced by a masking operation. In computing, performing a division to obtain the modulo is more expensive (I mean it uses more cycles per instruction) than a masking operation.
Being BUCKET_COUNT is a power of two, the previous formula is rewritten as follows:
Bucket = H(“John”) & (BUCKET_COUNT -1)
Where & is a bitwise AND operation. You can test this math shortcut by yourself with the following SQL script.
DECLARE @BUCKET_COUNT INT = 8 SELECT 8458 % @BUCKET_COUNT SELECT 8458 & (@BUCKET_COUNT -1)
2 – After that the Engine checks at the given position if there is a pointer to a row. If so then it checks for a key value match and if the end timestamp isn’t set.
3 – If row key doesn’t match or end timestamp is set then the engine looks at the row’s index pointer. If pointer is null then the searched key doesn’t exist. Otherwise it repeats step 2 until the searched key is found or the end of pointer chain has been reached.
Here you have a flow chart showing these steps.

Pros and Cons of Hash Indexes in SQL Server Hekaton
Now I will show you with examples in which circumstances Hash indexes are the right choice. Also I will include screen captures with the execution plans so you can see the difference in query cost.
First we need to create our test database
CREATE DATABASE TestDB
ON PRIMARY
(NAME = TestDB_file1,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Data\TestDB_1.mdf',
SIZE = 100MB,
FILEGROWTH = 10%),
FILEGROUP TestDB_MemoryOptimized_filegroup CONTAINS MEMORY_OPTIMIZED_DATA
( NAME = TestDB_MemoryOptimized,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Data\TestDB_MemoryOptimized')
LOG ON
( NAME = TestDB_log_file1,
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Data\TestDB_1.ldf',
SIZE = 100MB,
FILEGROWTH = 10%)
GO
Then we create some sample tables pairs.
USE TestDB
GO
IF OBJECT_ID('dbo.sample_memoryoptimizedtable_Hash','U') IS NOT NULL
DROP TABLE dbo.sample_memoryoptimizedtable_Hash
GO
CREATE TABLE dbo.sample_memoryoptimizedtable_Hash
(
c1 int NOT NULL,
c2 float NOT NULL,
c3 decimal(10, 2) NOT NULL
CONSTRAINT PK_sample_memoryoptimizedtable_Hash PRIMARY KEY NONCLUSTERED HASH
(
c1
)WITH ( BUCKET_COUNT = 1024)
)WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
GO
----------------------------------------------------------------
IF OBJECT_ID('dbo.sample_memoryoptimizedtable_Range','U') IS NOT NULL
DROP TABLE dbo.sample_memoryoptimizedtable_Range
GO
CREATE TABLE dbo.sample_memoryoptimizedtable_Range
(
c1 int NOT NULL,
c2 float NOT NULL,
c3 decimal(10, 2) NOT NULL
CONSTRAINT PK_sample_memoryoptimizedtable_Range PRIMARY KEY NONCLUSTERED
(
c1 ASC
)
)WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
GO
/*----------------------------------------------------------------*/
/*----------------------------------------------------------------*/
IF OBJECT_ID('dbo.StringTable_Hash','U') IS NOT NULL
DROP TABLE dbo.StringTable_Hash
GO
CREATE TABLE dbo.StringTable_Hash
(
PersonID nvarchar(50) COLLATE Latin1_General_100_BIN2 NOT NULL ,
Name nvarchar(50) COLLATE Latin1_General_100_BIN2 NOT NULL,
CONSTRAINT PK_StringTable_Hash PRIMARY KEY NONCLUSTERED HASH (PersonID)
WITH (BUCKET_COUNT = 1024)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
----------------------------------------------------------------
IF OBJECT_ID('dbo.StringTable_Range','U') IS NOT NULL
DROP TABLE dbo.StringTable_Range
GO
CREATE TABLE dbo.StringTable_Range
(
PersonID nvarchar(50) COLLATE Latin1_General_100_BIN2 NOT NULL,
Name nvarchar(50) COLLATE Latin1_General_100_BIN2 NOT NULL,
CONSTRAINT PK_StringTable_Range PRIMARY KEY NONCLUSTERED (PersonID ASC)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
/*----------------------------------------------------------------*/
/*----------------------------------------------------------------*/
IF OBJECT_ID('dbo.Composite_Key_Hash','U') IS NOT NULL
DROP TABLE dbo.Composite_Key_Hash
GO
CREATE TABLE dbo.Composite_Key_Hash
(
c1 int NOT NULL,
c2 float NOT NULL,
c3 decimal(10, 2) NOT NULL
CONSTRAINT PK_Composite_Key_Hash PRIMARY KEY NONCLUSTERED HASH
(
c1, c2
)WITH ( BUCKET_COUNT = 1024)
)WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
GO
----------------------------------------------------------------
IF OBJECT_ID('dbo.Composite_Key_Range','U') IS NOT NULL
DROP TABLE dbo.Composite_Key_Range
GO
CREATE TABLE dbo.Composite_Key_Range
(
c1 int NOT NULL,
c2 float NOT NULL,
c3 decimal(10, 2) NOT NULL
CONSTRAINT PK_Composite_Key_Range PRIMARY KEY NONCLUSTERED
(
c1 ASC, c2 ASC
)
)WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
GO
As you can see each table in the pair has the same structure, but differs on index type.
Now we load some test data.
USE TestDB GO INSERT INTO dbo.sample_memoryoptimizedtable_Hash(c1, c2, c3) SELECT 1, 1, 1 UNION ALL SELECT 2, 1, 1 UNION ALL SELECT 8, 1, 1 UNION ALL SELECT 3, 1, 1 UNION ALL SELECT 4, 1, 1 UNION ALL SELECT 5, 1, 1 UNION ALL SELECT 6, 1, 1 UNION ALL SELECT 7, 1, 1 -------------------------------------------------- INSERT INTO dbo.sample_memoryoptimizedtable_Range(c1, c2, c3) SELECT 1, 1, 1 UNION ALL SELECT 2, 1, 1 UNION ALL SELECT 8, 1, 1 UNION ALL SELECT 3, 1, 1 UNION ALL SELECT 4, 1, 1 UNION ALL SELECT 5, 1, 1 UNION ALL SELECT 6, 1, 1 UNION ALL SELECT 7, 1, 1 /*----------------------------------------------*/ /*----------------------------------------------*/ INSERT INTO dbo.StringTable_Hash(PersonID, Name) SELECT 'A101054', 'John' UNION ALL SELECT 'A184848', 'Tim' UNION ALL SELECT 'C154887', 'Bill' UNION ALL SELECT 'B101054', 'Henry' UNION ALL SELECT 'B109854', 'Douglas' UNION ALL SELECT 'D101054', 'Charles' UNION ALL SELECT 'CA01054', 'Ben' -------------------------------------------------- INSERT INTO dbo.StringTable_Range(PersonID, Name) SELECT 'A101054', 'John' UNION ALL SELECT 'A184848', 'Tim' UNION ALL SELECT 'C154887', 'Bill' UNION ALL SELECT 'B101054', 'Henry' UNION ALL SELECT 'B109854', 'Douglas' UNION ALL SELECT 'D101054', 'Charles' UNION ALL SELECT 'CA01054', 'Ben' /*----------------------------------------------*/ /*----------------------------------------------*/ INSERT INTO dbo.Composite_Key_Hash(c1, c2, c3) SELECT 1, 1, 1 UNION ALL SELECT 2, 1, 1 UNION ALL SELECT 8, 1, 1 UNION ALL SELECT 3, 1, 1 UNION ALL SELECT 4, 1, 1 UNION ALL SELECT 5, 1, 1 UNION ALL SELECT 6, 1, 1 UNION ALL SELECT 7, 1, 1 -------------------------------------------------- INSERT INTO dbo.Composite_Key_Range(c1, c2, c3) SELECT 1, 1, 1 UNION ALL SELECT 2, 1, 1 UNION ALL SELECT 8, 1, 1 UNION ALL SELECT 3, 1, 1 UNION ALL SELECT 4, 1, 1 UNION ALL SELECT 5, 1, 1 UNION ALL SELECT 6, 1, 1 UNION ALL SELECT 7, 1, 1
Finally we are ready to perform the tests.
- Hash indexes don’t support range searches like <, > and BETWEEN. This is done by an index scan.
USE TestDB GO -- Range searches SELECT c1 FROM dbo.sample_memoryoptimizedtable_Hash WHERE c1 > 4 SELECT c1 FROM dbo.sample_memoryoptimizedtable_Range WHERE c1 > 4

- Inequality searches are not supported. They perform a table scan.
USE TestDB GO -- Equality comparisons SELECT c1 FROM dbo.sample_memoryoptimizedtable_Hash WHERE c1 = 4 SELECT c1 FROM dbo.sample_memoryoptimizedtable_Range WHERE c1 = 4

- Hash indexes aren’t ordered, so an ORDER BY operation will add a SORT step on the execution plan.
USE TestDB GO -- ORDER BY operation SELECT c1 FROM dbo.sample_memoryoptimizedtable_Hash WHERE c1 = 4 OR c1 = 7 ORDER BY c1 SELECT c1 FROM dbo.sample_memoryoptimizedtable_Range WHERE c1 = 4 OR c1 = 7 ORDER BY c1

- With Hash indexes only whole keys can be used to search for a row. For example if you have a table with a composite key like (C1, C2) then searching by C1 will result in an index scan.
USE TestDB GO -- Composite Key Behavior SELECT c1 FROM dbo.Composite_Key_Hash WHERE c1 = 4 SELECT c1 FROM dbo.Composite_Key_Range WHERE c1 = 4

- A corollary of the above is that LIKE comparisons are not supported and will result in an index scan.
USE [TestDB] GO SELECT PersonID FROM dbo.StringTable_Hash WHERE PersonID LIKE 'C%' SELECT PersonID FROM dbo.StringTable_Range WHERE PersonID LIKE 'C%'

Conclusion
Although Hash indexes are a very powerful tool and can be very helpful in some situations, Hash indexing requires more planning than range indexing. In order to take full advantage of Memory-Optimized tables a SQL Server specialist must fully understand the difference between Hash and Range indexes
References
- Hekaton: SQL Server’s Memory-Optimized OLTP Engine, Diaconu C., Freedman C., Ismert E, Larson P., Mittal P., Stonecipher R., Verma N., Zwilling M. (http://research.microsoft.com/pubs/193594/Hekaton%20-%20Sigmod2013%20final.pdf).
- Delaney K. SQL Server In-Memory OLTP Internals Overview for CTP2 (http://download.microsoft.com/download/F/5/0/F5096A71-3C31-4E9F-864E-A6D097A64805/SQL_Server_Hekaton_CTP1_White_Paper.pdf).
Next Steps
- Take a look at my previous tip about migrating to Memory-Optimized Tables: Overcoming storage speed limitations with Memory-Optimized Tables for SQL Server.
- This is a good tip to start getting in touch with indexes: SQL Server Indexing Basics.
- Also, this one would give you more insight: Understanding SQL Server Indexing.
- After those tips you are ready for this one: SQL Server Index Checklist.
- In this tip you will learn how to deal with composite indexes: SQL Server Index Column Order – Does it Matter.
- To perform tests on your indexes you can read about Using Hints To Test SQL Server Indexes.
- For ORDER BY queries this is very important: Building SQL Server Indexes in Ascending vs Descending Order
- If you don’t understand execution plans, this tutorial is for you: Graphical Query Plan Tutorial.
- Take a look at Indexing Tips Category.
- Also take a look at Performance Tuning Tips Category.

Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning. He studied at Universidad de Buenos Aires. Daniel started working as a programmer at a young age. Over the years he specialized in databases, particularly SQL Server and Oracle. Now with 30 years of age, his work experience includes working with various technologies like VB, C, .NET, web development, Windows and Linux systems. He likes to read about science, psychology, philosophy and many other things. In his spare time, he trains powerlifting aiming to compete.
- MSSQLTips Awards: Author of the Year – 2018 | Champion (100+ tips) – 2018 | Author Contender – 2015-2017, 2019