Problem
We have online games that allow user input when answering questions, offer multiple choice quizzes, or challenge our users with timed practices. We want to add an increased difficulty feature to our games that track’s the most commonly missed answers for specific questions from user input and uses these as options in our other quizzes with multiple choice. This will continuously make the wrong answers more challenging and make it more difficult for the user to correctly pick the right answer.
Since we’re retaining the user input on both questions where the user enters information or misses information on a multiple choice quiz, we will be using SQL Server to retain this information. We want to know how to use SQL Server to present incorrect answers that most users miss on each question for our most difficult setting over randomly picking a word on the easy setting.
Solution
In this tip, we’ll look at one way we can do this in SQL Server and we’ll use an English learning game as the example.
In our example, we’ll have a dictionary of words stored in the database with an ID field for random selection, which is the easy setting. If the game features a word in a multiple choice question on the easy setting, it generates these with a select query on the ID fields from randomly chosen numbers in the application or database layer. What we want to do is add a feature which allows us to increase the difficultly of our game.
For an example, suppose our game asks a multiple choice question on the easy setting:
Select the correct possessive for the sentence: They took ______ dog with them to New York.
The choices for the question are:
A. there B. hope C. their D. to
In the question, two of those choices may not be challenging. We want to track the most commonly missed choices for the word “their” and have those be the top choices, rather than randomly selecting three words. What we’re essentially solving is capturing related data to a data point by saving the related data to a table, then returning the related data associated most often to that data point.
We’ll create three tables for this exercise. The first table, tblWords, is where we hold words for questions we’ll ask, or for incorrect words on challenges that offer options (like multiple choice challenges). The second table, tblErrorTracking, logs the incorrect responses. Using the example question above this, if a user chose “hope” – which is incorrect – the tblErrorTracking would log the ID of the incorrect word (what was chosen by the user) and the ID of the correct word (what should have been chosen by the user). I’ve added a date and time field that allows us the option of time-based relevancy, such as users making different errors as they learn. Since this requires additional space and may not be necessary for the application, this column may be removed.
The tblErrorTracking table in general will consume little space, as even with 1 million users a week generating 10 errors each, that’s only 10 million records per week for the table. Integers in SQL Server only consume 4 bytes of storage, and depending on the application, we may have the option of using a smallint. Because the English language has over 1 million words and a challenging application might store 25,000 or more words with a possibility for growth, we’ll use integer in our example. The third table we’ll use for the final demo only and populate it with one record.
Here is the code to create the tables and insert some data.
CREATE TABLE tblWords(
WordId INT IDENTITY(1,1) PRIMARY KEY,
Word VARCHAR(100)
)
CREATE TABLE tblErrorTracking(
CorrectWordId INT FOREIGN KEY REFERENCES tblWords (WordId),
ErrorWordId INT FOREIGN KEY REFERENCES tblWords (WordId),
DateError DATETIME DEFAULT GETDATE()
)
---- FOR FINAL DEMO PURPOSES ONLY:
CREATE TABLE tblQuestion(
QuestionID INT IDENTITY(1,1) PRIMARY KEY,
RelatedWordID INT FOREIGN KEY REFERENCES tblWords (WordId),
Question VARCHAR(1000)
)
INSERT INTO tblWords (Word)
VALUES ('to')
, ('two')
, ('too')
, ('their')
, ('there')
, ('they''re')
, ('one')
, ('from')
, ('of')
INSERT INTO tblErrorTracking (CorrectWordId,ErrorWordId)
VALUES (1,2)
, (1,2)
, (1,2)
, (1,3)
, (1,9)
, (4,5)
, (4,5)
, (4,6)
, (4,6)
, (4,6)
, (4,6)
, (4,8)
---- FOR FINAL DEMO PURPOSES ONLY:
INSERT INTO tblQuestion (RelatedWordID,Question)
VALUES (4,'Select the correct plural possessive for the sentence: They took ______ dog with them to New York.')
, (5,'What five letter adverb answers the question at, in, or where involving a place or location?')
, (1,'Select the English two letter preposition for expressing motion in the direction of or identifying the object affected.')
---- if we want to retain user input:
CREATE PROCEDURE addUserInput
@word VARCHAR(100)
AS
BEGIN
IF NOT EXISTS (SELECT 1 FROM tblWords WHERE Word = @word)
BEGIN
INSERT INTO tblWords (Word) VALUES (@word)
END
END
EXEC addUserInput 'test'
SELECT * FROM tblWords
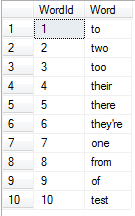
If we want to retain user input, I’ve added a procedure which will add a word to tblWords. Depending on the game, I recommend against this for several reasons:
- In the case of this example application – English – an incorrect input may not be valid English. For an example, the typo thei4 isn’t a word for “their” so by saving words entered, we would be retaining invalid English data. Do we want to do this? It depends on our business rules. I add this procedure because there may be situations where this is called for – like a biology application allowing for user input, even if that input is unrelated or wrong.
- If we tried to validate data, such as validating whether a word is English in this example, we’d add complexity and reduce performance of our application. It’s possible that we find millions of typos over a period of time, none of which are mistaken very often.
- If we don’t offer user input in our games, this won’t matter since some challenges may be a preset selection – such as multiple choice or true or false.
Still, this is case-by-case and ultimately should comply with the business rules of the application. For this example, I include it to show how it can be done, but for the example of an English learning game, I would recommend against it.
SELECT *
FROM tblErrorTracking

We’ve populated some sample errors to begin solving the problem of returning related data (incorrect choices). Using the word their, we query the tblErrorTracking table to return the related errors for the word. We inner join tblWords to filter for the correct word (WHERE t2.Word = @word). We want the related data for this data point – in this case, the incorrect words that were chosen when the correct word was their. We inner join tblWords again on the ErrorWordId to get the erroneously chosen words.
The result is shown below this.
---- We want to return all the incorrect values for the word 'their'
DECLARE @word VARCHAR(100) = 'their'
SELECT
*
FROM tblErrorTracking t
INNER JOIN tblWords t2 ON t.CorrectWordId = t2.WordId
INNER JOIN tblWords t3 ON t.ErrorWordId = t3.WordId
WHERE t2.Word = @word

Next, we want to aggregate these data by getting the most frequently missed words for their in order of how many times they were answered incorrectly by users. I show the counts also in the below query for demonstration purposes, but for the application and returning the word, we would only return the words.
---- Next, we want to order the incorrect words by the most frequent times they were missed
DECLARE @word VARCHAR(100) = 'their'
SELECT
t3.Word
, COUNT(t3.Word) CountError ---- this is only for demo; if the application selects, it would only return the word t3.Word
FROM tblErrorTracking t
INNER JOIN tblWords t2 ON t.CorrectWordId = t2.WordId
LEFT JOIN tblWords t3 ON t.ErrorWordId = t3.WordId
WHERE t2.Word = @word
GROUP BY t3.Word
ORDER BY COUNT(t3.Word) DESC

Finally, we want to execute a demo only on the back-end of populating some data to the tblErrorTracking table to simulate a user getting the incorrect selection in a question – whether through user input, multiple choice, or some other format.
In the below demo, we have a stored procedure which passes in the correct word that should have been chosen by the user with the incorrect word that was chosen by the user. The procedure validates that the incorrect word exists first, then adds the CorrectWordId and ErrorWordId to the tblErrorTracking table. This if statement may not be necessary in situations where the user chose from a pre-selected set of possible answers, but if we allow user entry and we want to prevent invalid data, this is a necessary step. From here, we execute our stored procedure a few times and query our data again looking for the word their.
CREATE PROCEDURE addErroneousResponse
@wordtrue VARCHAR(100),
@wordfalse VARCHAR(100)
AS
BEGIN
IF EXISTS (SELECT 1 FROM tblWords WHERE Word = @wordfalse)
BEGIN
DECLARE @wordtrueid INT, @wordfalseid INT
SELECT @wordtrueid = WordId FROM tblWords WHERE Word = @wordtrue
SELECT @wordfalseid = WordId FROM tblWords WHERE Word = @wordfalse
INSERT INTO tblErrorTracking (CorrectWordId,ErrorWordId)
VALUES (@wordtrueid,@wordfalseid)
END
END
EXEC addErroneousResponse 'their','they''re'
EXEC addErroneousResponse 'their','they''re'
EXEC addErroneousResponse 'there','their'
EXEC addErroneousResponse 'there','their'
EXEC addErroneousResponse 'there','their'
EXEC addErroneousResponse 'there','their'
---- Increases the count:
DECLARE @word VARCHAR(100) = 'their'
SELECT
t3.Word
, COUNT(t3.Word) CountError
FROM tblErrorTracking t
INNER JOIN tblWords t2 ON t.CorrectWordId = t2.WordId
INNER JOIN tblWords t3 ON t.ErrorWordId = t3.WordId
WHERE t2.Word = @word
GROUP BY t3.Word
ORDER BY COUNT(t3.Word) DESC

And we query for the word there:
---- look at the new word there
DECLARE @word VARCHAR(100) = 'there'
SELECT
t3.Word
, COUNT(t3.Word) CountError
FROM tblErrorTracking t
INNER JOIN tblWords t2 ON t.CorrectWordId = t2.WordId
INNER JOIN tblWords t3 ON t.ErrorWordId = t3.WordId
WHERE t2.Word = @word
GROUP BY t3.Word
ORDER BY COUNT(t3.Word) DESC
I added the last query as an example of what might happen if we don’t have enough related errors. Suppose that our question involved the word “three” and no one missed questions or challenges involving three, so we had no data with errors for that word. In this case, even in our hard mode, we would randomly select words from the table.
Finally, we’ll tie all this together with a stored procedure that our test application will use to get the question, the correct answer, and 3 incorrect responses by first checking if 3 common incorrect responses exist. We’ll assume our application is using XML for organization on this return output where each component is wrapped in its description. We also pass in the integer for the example – the application would either generate a random number in the application layer and pass it to the procedure, or generate a random number on the back-end and use it to return the question, correct answer, and 3 incorrect responses.
----- FINAL RETURN DEMO:
CREATE PROCEDURE getQuestion_Hard
AS
BEGIN
---- random number generator either on back-end or from application; in example, we'll use "their" or 4
DECLARE @example INT = 4, @rowcount INT
DECLARE @return TABLE (OrderID INT, ReturnQuestionDetails VARCHAR(1000))
INSERT INTO @return
SELECT 1, '<question>' + Question + '</question>' ReturnQuestionDetails FROM tblQuestion WHERE RelatedWordID = @example
INSERT INTO @return
SELECT 2, '<true>' + Word + '</true>' AS ReturnQuestionDetails FROM tblWords WHERE WordId = @example
INSERT INTO @return
SELECT TOP 3
3, '<false>' + t3.Word + '</false>' AS ReturnQuestionDetails
FROM tblErrorTracking t
INNER JOIN tblWords t2 ON t.CorrectWordId = t2.WordId
INNER JOIN tblWords t3 ON t.ErrorWordId = t3.WordId
WHERE t2.WordId = @example
GROUP BY t3.Word
ORDER BY COUNT(t3.Word) DESC
SET @rowcount = @@ROWCOUNT
IF @rowcount <> 3
BEGIN
INSERT INTO @return
SELECT TOP 4 4, '<false>' + Word + '</false>' AS ReturnQuestionDetails FROM tblWords WHERE WordId <> @example ORDER BY NEWID()
END
;WITH GetNoDupeFalses AS(
SELECT ROW_NUMBER() OVER (PARTITION BY ReturnQuestionDetails ORDER BY ReturnQuestionDetails) DupeFalseId
, *
FROM @return
)
SELECT TOP 5 ReturnQuestionDetails
FROM GetNoDupeFalses
WHERE DupeFalseId = 1
ORDER BY OrderId
END

In the variable table, OrderId is used in case we only get 0, 1, or 2 returns from the third insert seen inside the stored procedure (the related errors to the word). Since this example is looking for the question, the correct word, and 3 possible incorrect responses, we can SELECT TOP 5 and by using an order skip any extra records, like if there were 2 records returned in the third insert and 4 records returned in the final insert – it would still only return the top 5, 2 of which are related errors. Even with 50,000 records or more in this game, it’s possible we return duplicates from the third and fourth query, because the third query looks for related errors to the word, while the fourth query returns any word, except the correct word. The final query removes any duplicates.
This uses an English word game as an example of using TSQL to capture related data and return aggregates. This can help add a layer of difficulty to games by using popular incorrect answers as options in questions, but we can use it for other applications where we need related data for a data point.
Consider the following use case and how similar it is to our example game:
- We see an error regularly in our environment involving access to a folder. This error means one of three possibilities.
- 95% of the time, the first possibility is the problem, which is the drive was detached or the folder became unavailable.
- 3% of the time, an AD error happened and the user lost permission.
- 2% of the time, something else happened.
Based on the instances above this, we would want to validate the first two before troubleshooting three. If an increase in the third happened, moving it to the second position or third, we could adjust as needed – our tracking of related errors allows us to dynamically solve problems. Fundamentally, this game is a data point which has related data that may be constantly changing and the returned data set related to the data point must change based on the input from the users.
Next Steps
- Review the business rules for your application – how do you want to track errors, do you want to include the time of the error, do you want to capture user input? There are costs and benefits of each of these routes.
- Consider that this is one possible solution that costs little in terms of storage. For instance, storing 1,000,000 records in the tblErrorTracking table (including the date and time) consumes less than 30MB. Without date and time, that reduces by 50%.
- Other considerations when tracking errors in games such as this example on the back-end are tracking the user information, region information, etc. Some errors may be more common in some areas or to some users instead of overall. The business use determines what is needed and what is not needed.

Tim consults for FinTek Development and teaches the course Automating ETL on Udemy. He’s worked with technology since high school, helping his school win its first TCEA award and continues to work in automation, data architecture, back-end development, and smart contract architecture. Tim enjoys testing new technologies early in the diffusion of innovation curve and was an early adopter of NoSQL and smart contract development. He has a blog at http://www.fintekdev.com/ and helps contribute to local technical and financial events in Texas.


