Problem
As you may have heard or experienced, not setting a process to regularly clean your MSDB database can slow down your backups and negatively impact your SQL Server. If you’ve been there, you may know your options are either running sp_delete_backuphistory (which is painfully slow and causes blocking and fills the log, but it does work, check out this tip) or truncate the tables and end up losing all your history data. However, another option is to partition the tables and drop the data you don’t need, if you want to know more on this topic, you can check these tips on partitioning.
So I’ve been tasked to purge the SQL Server MSDB database across all our instances in the most efficient way, one that doesn’t cause blocking, doesn’t fill the transaction log, and that also completes during our maintenance window. How can I complete this?
Solution
By using the following scripts, I was able to cut down the time to less than 1/3 compared with using “sp_delete_backuphistory”, and because it works in all SQL Server versions from 2005 to 2017, with a multi-server query we can purge all MSDB databases at once, if you’re brave enough. Note that I’m not encouraging you to do so, in fact, you shouldn’t run any code without making sure you understand what it is doing, and testing it properly. After you’ve done that, because this script receives the number of days to keep, it can be scheduled to run automatically in a SQL Server Agent Job.
NOTE: Since we are using table partitioning, this approach will only work with SQL Server Enterprise edition and Developer edition.
SQL Server MSDB Index Creation Script
Before we get started there is one thing to know, the indexes across SQL Server versions are different from 2005 to 2008 to 2014 to 2016, so before running the script, we have to make sure that all of the necessary indexes are in place. To accomplish this task, you must run the script below which:
- Checks if there’s any non-standard index you need to delete, as these won’t allow moving the data out of the table. The results only provide the table and index name, you must drop them accordingly to their type.
- Checks if all standard indexes are created, and if not the script provides you with the commands to create them.
If you run the below script, it will show which expected indexes are missing in the msdb database.
USE [msdb]
GO
CREATE TABLE #Expected ([Table] VARCHAR(200), [Constraint] VARCHAR(200), [Command] VARCHAR(1000))
INSERT INTO #Expected VALUES ('backupfile', 'PK__backupfi', 'ALTER TABLE [backupfile] ADD PRIMARY KEY CLUSTERED ([backup_set_id], [file_number])')
INSERT INTO #Expected VALUES ('backupfilegroup', 'PK__backupfi', 'ALTER TABLE [backupfilegroup] ADD PRIMARY KEY CLUSTERED ([backup_set_id], [filegroup_id])')
INSERT INTO #Expected VALUES ('backupmediafamily', 'backupmediafamilyuuid', 'CREATE NONCLUSTERED INDEX [backupmediafamilyuuid] ON [backupmediafamily] ([media_family_id])')
INSERT INTO #Expected VALUES ('backupmediafamily', 'PK__backupme', 'ALTER TABLE [backupmediafamily] ADD PRIMARY KEY CLUSTERED ([media_set_id], [family_sequence_number], [mirror])')
INSERT INTO #Expected VALUES ('backupmediaset', 'backupmediasetuuid', 'CREATE NONCLUSTERED INDEX [backupmediasetuuid] ON [backupmediaset] ([media_uuid])')
INSERT INTO #Expected VALUES ('backupmediaset', 'FK__backupmed__media', 'ALTER TABLE [backupmediafamily] WITH CHECK ADD FOREIGN KEY([media_set_id]) REFERENCES [backupmediaset] ([media_set_id])')
INSERT INTO #Expected VALUES ('backupmediaset', 'FK__backupset__media', 'ALTER TABLE [backupset] WITH CHECK ADD FOREIGN KEY([media_set_id]) REFERENCES [backupmediaset] ([media_set_id])')
INSERT INTO #Expected VALUES ('backupmediaset', 'PK__backupme', 'ALTER TABLE [backupmediaset] ADD PRIMARY KEY CLUSTERED ([media_set_id])')
INSERT INTO #Expected VALUES ('backupset', 'backupsetDate', 'CREATE NONCLUSTERED INDEX [backupsetDate] ON [backupset] ([backup_finish_date])')
INSERT INTO #Expected VALUES ('backupset', 'backupsetMediaSetId', 'CREATE NONCLUSTERED INDEX [backupsetMediaSetId] ON [backupset] ([media_set_id])')
INSERT INTO #Expected VALUES ('backupset', 'backupsetuuid', 'CREATE NONCLUSTERED INDEX [backupsetuuid] ON [backupset] ([backup_set_uuid])')
INSERT INTO #Expected VALUES ('backupset', 'backupsetDatabaseName', 'CREATE NONCLUSTERED INDEX [backupsetDatabaseName] ON [backupset] ([database_name]) INCLUDE ([backup_set_id], [media_set_id])')
INSERT INTO #Expected VALUES ('backupset', 'FK__backupfil__backu', 'ALTER TABLE [backupfilegroup] WITH CHECK ADD FOREIGN KEY([backup_set_id]) REFERENCES [backupset] ([backup_set_id])')
INSERT INTO #Expected VALUES ('backupset', 'FK__backupfil__backu', 'ALTER TABLE [backupfile] WITH CHECK ADD FOREIGN KEY([backup_set_id]) REFERENCES [backupset] ([backup_set_id])')
INSERT INTO #Expected VALUES ('backupset', 'FK__restorehi__backu', 'ALTER TABLE [restorehistory] WITH CHECK ADD FOREIGN KEY([backup_set_id]) REFERENCES [backupset] ([backup_set_id])')
INSERT INTO #Expected VALUES ('backupset', 'PK__backupse', 'ALTER TABLE [backupset] ADD PRIMARY KEY CLUSTERED ([backup_set_id])')
INSERT INTO #Expected VALUES ('logmarkhistory', 'logmarkhistory1', 'CREATE NONCLUSTERED INDEX [logmarkhistory1] ON [logmarkhistory] ([database_name], [mark_name])')
INSERT INTO #Expected VALUES ('logmarkhistory', 'logmarkhistory2', 'CREATE NONCLUSTERED INDEX [logmarkhistory2] ON [logmarkhistory] ([database_name], [lsn])')
INSERT INTO #Expected VALUES ('restorefile', 'restorefileRestoreHistoryId', 'CREATE NONCLUSTERED INDEX [restorefileRestoreHistoryId] ON [restorefile] ([restore_history_id])')
INSERT INTO #Expected VALUES ('restorefilegroup', 'restorefilegroupRestoreHistoryId', 'CREATE NONCLUSTERED INDEX [restorefilegroupRestoreHistoryId] ON [restorefilegroup] ([restore_history_id])')
INSERT INTO #Expected VALUES ('restorehistory', 'FK__restorefi__resto', 'ALTER TABLE [restorefilegroup] WITH CHECK ADD FOREIGN KEY([restore_history_id]) REFERENCES [restorehistory] ([restore_history_id])')
INSERT INTO #Expected VALUES ('restorehistory', 'FK__restorefi__resto', 'ALTER TABLE [restorefile] WITH CHECK ADD FOREIGN KEY([restore_history_id]) REFERENCES [restorehistory] ([restore_history_id])')
INSERT INTO #Expected VALUES ('restorehistory', 'PK__restoreh', 'ALTER TABLE [restorehistory] ADD PRIMARY KEY CLUSTERED ([restore_history_id])')
INSERT INTO #Expected VALUES ('restorehistory', 'restorehistorybackupset', 'CREATE NONCLUSTERED INDEX [restorehistorybackupset] ON [restorehistory] ([backup_set_id])')
SELECT * FROM #Expected [e]
FULL OUTER JOIN (
SELECT [i].[name] [Constraint], [t].[name] [Table]
FROM [sys].[indexes] [i]
INNER JOIN [sys].[tables] [t] ON [t].[object_id] = [i].[object_id]
WHERE [t].[name] IN ('backupfile', 'backupfilegroup', 'restorefile', 'restorefilegroup', 'restorehistory', 'backupset', 'logmarkhistory', 'backupmediafamily', 'backupmediaset')
AND [i].[type_desc] <> 'HEAP'
UNION ALL
SELECT OBJECT_NAME([f].[constraint_object_id]), [t].[name]
FROM [sys].[foreign_key_columns] [f]
INNER JOIN [sys].[tables] [t] ON [t].[object_id] = [f].[referenced_object_id]
WHERE [t].[name] IN ('backupfile', 'backupfilegroup', 'restorefile', 'restorefilegroup', 'restorehistory', 'backupset', 'logmarkhistory', 'backupmediafamily', 'backupmediaset')
) [a] ON [a].[Constraint] LIKE [e].[Constraint]+'%' AND [a].[Table] = [e].[Table]
WHERE [a].[Constraint] IS NULL
OR [e].[Constraint] IS NULL
DROP TABLE #Expected
This script can be run as a multi-server query, and depending on your results you can create your own script to create the missing indexes across all instances, something like:
IF @@VERSION LIKE 'Microsoft SQL Server 2005%'
BEGIN
CREATE INDEX ...
END
SQL Server MSDB Purge Script
For the main script, the only value that needs to be set is @DaysInterval. For example if you set the value to 30, only 30 days of data will be kept.
The script first calculates the current date minus @DaysInterval and then it calculates the value for the backup_set_id, media_set_id, restore_history_id, and mark_time. We can safely do this because these fields are identities, so we can get the max value before the specified interval and we then partition the data from that point.
Next, for each set of tables, it performs:
- Create the partition function and scheme
- Drops any foreign key constraints (just disabling does not work)
- Align all indexes to the partition and create a clustered index if missing
- Create a copy of the table structure and create the clustered index in the copy
- Move the data out of the table into the copy table, count the number of rows to delete, and drop the copy table
- Remove the partitioning from the table and drop any clustered index that was added
- Recreate any foreign key constraints previously dropped
- Drop the partition scheme and function
There are some things you must take note of in the script:
- If there is a primary key with a system generated name, it performs a CREATE UNIQUE CLUSTERED INDEX with the same name, but with DROP_EXISTING, and aligns it to the partition. This is the case, for example, in the tables “backupfile” and “backupfilegroup”.
- If there is no primary key, but a named nonclustered index, it is re-created as a clustered index aligning it to the partition. There is no command to convert it again to a nonclustered index, so in order to revert our changes, we first need to rebuild it removing the partition, then drop the index, and finally re-create it as a nonclustered index. This is the case, for example, for tables “restorefile” and “restorefilegroup”.
- If there is any nonclustered index, it needs to be re-created aligning it to the partition, so we need to add the column used to partition the table. These indexes aren’t required in the copy table, so these are not created. The process to revert this operation is to re-create the index without the column used to partition the table and removing the partition.
- For the table “logmarkhistory” we have to use the field “mark_time” to partition it, which is of type datetime, but because it is not unique and the other fields are nullable, we can’t create a primary key. So we create a clustered index that is not unique, and this is enough to partition the table.
- If there’s any error, everything is rolled back.
Here is the final script:
DECLARE
@DaysInterval INT,
@DateStart DATETIME,
@BackupSetId INT,
@MediaSetId INT,
@RestoreHistoryId INT,
@PKName NVARCHAR(128),
@FKName NVARCHAR(128),
@SqlCmd VARCHAR(8000),
@Output VARCHAR(MAX)
SET @DaysInterval = 30
SET @Output = ''
BEGIN
SET NOCOUNT ON
-- Calculate values
SET @DateStart = DATEADD(DD, -@DaysInterval, GETDATE())
SELECT @BackupSetId = MAX([backup_set_id]), @MediaSetId = MAX([media_set_id]) FROM [backupset] WHERE [backup_finish_date] < @DateStart
SELECT @RestoreHistoryId = MAX([restore_history_id]) FROM [restorehistory] WHERE [backup_set_id] <= @BackupSetId
SELECT @DateStart = MAX([mark_time]) FROM [logmarkhistory] WHERE [mark_time] <= @DateStart
BEGIN TRANSACTION
BEGIN TRY
IF @BackupSetId IS NOT NULL
BEGIN
CREATE PARTITION FUNCTION BackupSetId (INT) AS RANGE LEFT FOR VALUES (@BackupSetId)
CREATE PARTITION SCHEME BackupSetId AS PARTITION BackupSetId ALL TO ([PRIMARY])
-- [backupfile]
SET @PKName = (SELECT [name] FROM [sys].[indexes] WHERE [object_id] = OBJECT_ID(N'backupfile') AND [name] LIKE N'PK__backupfi%' AND [type_desc] = 'CLUSTERED')
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupfile] ([backup_set_id], [file_number]) WITH (DROP_EXISTING = ON) ON BackupSetId([backup_set_id])'
EXEC (@SqlCmd)
SELECT TOP 0 * INTO [partition] FROM [backupfile]
ALTER TABLE [partition] ADD PRIMARY KEY CLUSTERED ([backup_set_id], [file_number])
ALTER TABLE [backupfile] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [backupfile]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupfile] ([backup_set_id], [file_number]) WITH (DROP_EXISTING = ON) ON [PRIMARY]'
EXEC (@SqlCmd)
-- [backupfilegroup]
SET @PKName = (SELECT [name] FROM [sys].[indexes] WHERE [object_id] = OBJECT_ID(N'backupfilegroup') AND [name] LIKE N'PK__backupfi%' AND [type_desc] = 'CLUSTERED')
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupfilegroup] ([backup_set_id], [filegroup_id]) WITH (DROP_EXISTING = ON) ON BackupSetId([backup_set_id])'
EXEC (@SqlCmd)
SELECT TOP 0 * INTO [partition] FROM [backupfilegroup]
ALTER TABLE [partition] ADD PRIMARY KEY CLUSTERED ([backup_set_id], [filegroup_id])
ALTER TABLE [backupfilegroup] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [backupfilegroup]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupfilegroup] ([backup_set_id], [filegroup_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]'
EXEC (@SqlCmd)
END
IF @RestoreHistoryId IS NOT NULL
BEGIN
CREATE PARTITION FUNCTION RestoreHistoryId (INT) AS RANGE LEFT FOR VALUES (@RestoreHistoryId)
CREATE PARTITION SCHEME RestoreHistoryId AS PARTITION RestoreHistoryId ALL TO ([PRIMARY])
-- [restorefile]
CREATE CLUSTERED INDEX [restorefileRestoreHistoryId] ON [restorefile] ([restore_history_id]) WITH (DROP_EXISTING = ON) ON RestoreHistoryId([restore_history_id])
SELECT TOP 0 * INTO [partition] FROM [restorefile]
CREATE CLUSTERED INDEX [partition] ON [partition] ([restore_history_id])
ALTER TABLE [restorefile] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [restorefile]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
CREATE CLUSTERED INDEX [restorefileRestoreHistoryId] ON [restorefile] ([restore_history_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
DROP INDEX [restorefileRestoreHistoryId] ON [restorefile]
CREATE NONCLUSTERED INDEX [restorefileRestoreHistoryId] ON [restorefile] ([restore_history_id]) ON [PRIMARY]
-- [restorefilegroup]
CREATE CLUSTERED INDEX [restorefilegroupRestoreHistoryId] ON [restorefilegroup] ([restore_history_id]) WITH (DROP_EXISTING = ON) ON RestoreHistoryId([restore_history_id])
SELECT TOP 0 * INTO [partition] FROM [restorefilegroup]
CREATE CLUSTERED INDEX [partition] ON [partition] ([restore_history_id])
ALTER TABLE [restorefilegroup] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [restorefilegroup]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
CREATE CLUSTERED INDEX [restorefilegroupRestoreHistoryId] ON [restorefilegroup] ([restore_history_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
DROP INDEX [restorefilegroupRestoreHistoryId] ON [restorefilegroup]
CREATE NONCLUSTERED INDEX [restorefilegroupRestoreHistoryId] ON [restorefilegroup] ([restore_history_id]) ON [PRIMARY]
-- [restorehistory]
SET @FKName = (SELECT OBJECT_NAME([fk].[constraint_object_id]) FROM [sys].[foreign_key_columns] [fk] WHERE [fk].[referenced_object_id] = OBJECT_ID('restorehistory') AND [fk].[parent_object_id] = OBJECT_ID('restorefilegroup'))
SET @SqlCmd = 'ALTER TABLE [restorefilegroup] DROP CONSTRAINT ['+@FKName+']'
EXEC (@SqlCmd)
SET @FKName = (SELECT OBJECT_NAME([fk].[constraint_object_id]) FROM [sys].[foreign_key_columns] [fk] WHERE [fk].[referenced_object_id] = OBJECT_ID('restorehistory') AND [fk].[parent_object_id] = OBJECT_ID('restorefile'))
SET @SqlCmd = 'ALTER TABLE [restorefile] DROP CONSTRAINT ['+@FKName+']'
EXEC (@SqlCmd)
SET @PKName = (SELECT [name] FROM [sys].[indexes] WHERE [object_id] = OBJECT_ID(N'restorehistory') AND [name] LIKE N'PK__restoreh%' AND [type_desc] = 'CLUSTERED')
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [restorehistory] ([restore_history_id]) WITH (DROP_EXISTING = ON) ON RestoreHistoryId([restore_history_id])'
EXEC (@SqlCmd)
CREATE NONCLUSTERED INDEX [restorehistorybackupset] ON [restorehistory] ([backup_set_id], [restore_history_id]) WITH (DROP_EXISTING = ON) ON RestoreHistoryId([restore_history_id])
SELECT TOP 0 * INTO [partition] FROM [restorehistory]
ALTER TABLE [partition] ADD PRIMARY KEY CLUSTERED ([restore_history_id])
ALTER TABLE [restorehistory] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [restorehistory]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [restorehistory] ([restore_history_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]'
EXEC (@SqlCmd)
CREATE NONCLUSTERED INDEX [restorehistorybackupset] ON [restorehistory] ([backup_set_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
ALTER TABLE [restorefilegroup] WITH CHECK ADD FOREIGN KEY([restore_history_id]) REFERENCES [restorehistory] ([restore_history_id])
ALTER TABLE [restorefile] WITH CHECK ADD FOREIGN KEY([restore_history_id]) REFERENCES [restorehistory] ([restore_history_id])
DROP PARTITION SCHEME RestoreHistoryId
DROP PARTITION FUNCTION RestoreHistoryId
END
IF @BackupSetId IS NOT NULL
BEGIN
-- [backupset]
SET @FKName = (SELECT OBJECT_NAME([fk].[constraint_object_id]) FROM [sys].[foreign_key_columns] [fk] WHERE [fk].[referenced_object_id] = OBJECT_ID('backupset') AND [fk].[parent_object_id] = OBJECT_ID('backupfilegroup'))
SET @SqlCmd = 'ALTER TABLE [backupfilegroup] DROP CONSTRAINT ['+@FKName+']'
EXEC (@SqlCmd)
SET @FKName = (SELECT OBJECT_NAME([fk].[constraint_object_id]) FROM [sys].[foreign_key_columns] [fk] WHERE [fk].[referenced_object_id] = OBJECT_ID('backupset') AND [fk].[parent_object_id] = OBJECT_ID('backupfile'))
SET @SqlCmd = 'ALTER TABLE [backupfile] DROP CONSTRAINT ['+@FKName+']'
EXEC (@SqlCmd)
SET @FKName = (SELECT OBJECT_NAME([fk].[constraint_object_id]) FROM [sys].[foreign_key_columns] [fk] WHERE [fk].[referenced_object_id] = OBJECT_ID('backupset') AND [fk].[parent_object_id] = OBJECT_ID('restorehistory'))
SET @SqlCmd = 'ALTER TABLE [restorehistory] DROP CONSTRAINT ['+@FKName+']'
EXEC (@SqlCmd)
SET @PKName = (SELECT [name] FROM [sys].[indexes] WHERE [object_id] = OBJECT_ID(N'backupset') AND [name] LIKE N'PK__backupse%' AND [type_desc] = 'CLUSTERED')
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupset] ([backup_set_id]) WITH (DROP_EXISTING = ON) ON BackupSetId([backup_set_id])'
EXEC (@SqlCmd)
CREATE NONCLUSTERED INDEX [backupsetDate] ON [backupset] ([backup_finish_date], [backup_set_id]) WITH (DROP_EXISTING = ON) ON BackupSetId([backup_set_id])
CREATE NONCLUSTERED INDEX [backupsetMediaSetId] ON [backupset] ([media_set_id], [backup_set_id]) WITH (DROP_EXISTING = ON) ON BackupSetId([backup_set_id])
CREATE NONCLUSTERED INDEX [backupsetuuid] ON [backupset] ([backup_set_uuid], [backup_set_id]) WITH (DROP_EXISTING = ON) ON BackupSetId([backup_set_id])
CREATE NONCLUSTERED INDEX [backupsetDatabaseName] ON [backupset] ([database_name]) INCLUDE ([backup_set_id], [media_set_id]) WITH (DROP_EXISTING =ON) ON BackupSetId([backup_set_id])
SELECT TOP 0 * INTO [partition] FROM [backupset]
ALTER TABLE [partition] ADD PRIMARY KEY CLUSTERED ([backup_set_id])
ALTER TABLE [backupset] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [backupset]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupset] ([backup_set_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]'
EXEC (@SqlCmd)
CREATE NONCLUSTERED INDEX [backupsetDate] ON [backupset] ([backup_finish_date]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [backupsetMediaSetId] ON [backupset] ([media_set_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [backupsetuuid] ON [backupset] ([backup_set_uuid]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [backupsetDatabaseName] ON [backupset] ([database_name]) INCLUDE ([backup_set_id], [media_set_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
ALTER TABLE [backupfilegroup] WITH CHECK ADD FOREIGN KEY([backup_set_id]) REFERENCES [backupset] ([backup_set_id])
ALTER TABLE [backupfile] WITH CHECK ADD FOREIGN KEY([backup_set_id]) REFERENCES [backupset] ([backup_set_id])
ALTER TABLE [restorehistory] WITH CHECK ADD FOREIGN KEY([backup_set_id]) REFERENCES [backupset] ([backup_set_id])
DROP PARTITION SCHEME BackupSetId
DROP PARTITION FUNCTION BackupSetId
END
IF @DateStart IS NOT NULL
BEGIN
CREATE PARTITION FUNCTION DateStart (DATETIME) AS RANGE LEFT FOR VALUES (@DateStart)
CREATE PARTITION SCHEME DateStart AS PARTITION DateStart ALL TO ([PRIMARY])
-- [logmarkhistory]
CREATE CLUSTERED INDEX [PK_logmarkhistory_martim] ON [logmarkhistory] ([mark_time]) ON DateStart([mark_time])
CREATE NONCLUSTERED INDEX [logmarkhistory1] ON [logmarkhistory] ([database_name], [mark_name], [mark_time]) WITH (DROP_EXISTING = ON) ON DateStart([mark_time])
CREATE NONCLUSTERED INDEX [logmarkhistory2] ON [logmarkhistory] ([database_name], [lsn], [mark_time]) WITH (DROP_EXISTING = ON) ON DateStart([mark_time])
SELECT TOP 0 * INTO [partition] FROM [logmarkhistory]
CREATE CLUSTERED INDEX [partition] ON [partition] ([mark_time])
ALTER TABLE [logmarkhistory] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [logmarkhistory]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
CREATE CLUSTERED INDEX [PK_logmarkhistory_martim] ON [logmarkhistory] ([mark_time]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
DROP INDEX [PK_logmarkhistory_martim] ON [logmarkhistory]
CREATE NONCLUSTERED INDEX [logmarkhistory1] ON [logmarkhistory] ([database_name], [mark_name]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [logmarkhistory2] ON [logmarkhistory] ([database_name], [lsn]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
DROP PARTITION SCHEME DateStart
DROP PARTITION FUNCTION DateStart
END
IF @MediaSetId IS NOT NULL
BEGIN
CREATE PARTITION FUNCTION MediaSetId (INT) AS RANGE LEFT FOR VALUES (@MediaSetId)
CREATE PARTITION SCHEME MediaSetId AS PARTITION MediaSetId ALL TO ([PRIMARY])
-- [backupmediafamily]
SET @PKName = (SELECT [name] FROM [sys].[indexes] WHERE [object_id] = OBJECT_ID(N'backupmediafamily') AND [name] LIKE N'PK__backupme%' AND [type_desc] = 'CLUSTERED')
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupmediafamily] ([media_set_id], [family_sequence_number], [mirror]) WITH (DROP_EXISTING = ON) ON MediaSetId([media_set_id])'
EXEC (@SqlCmd)
CREATE NONCLUSTERED INDEX [backupmediafamilyuuid] ON [backupmediafamily] ([media_family_id], [media_set_id]) WITH (DROP_EXISTING = ON) ON MediaSetId([media_set_id])
SELECT TOP 0 * INTO [partition] FROM [backupmediafamily]
ALTER TABLE [partition] ADD PRIMARY KEY CLUSTERED ([media_set_id], [family_sequence_number], [mirror])
ALTER TABLE [backupmediafamily] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [backupmediafamily]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupmediafamily] ([media_set_id], [family_sequence_number], [mirror]) WITH (DROP_EXISTING = ON) ON [PRIMARY]'
EXEC (@SqlCmd)
CREATE NONCLUSTERED INDEX [backupmediafamilyuuid] ON [backupmediafamily] ([media_family_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
-- [backupmediaset]
SET @FKName = (SELECT OBJECT_NAME([fk].[constraint_object_id]) FROM [sys].[foreign_key_columns] [fk] WHERE [fk].[referenced_object_id] = OBJECT_ID('backupmediaset') AND [fk].[parent_object_id] = OBJECT_ID('backupmediafamily'))
SET @SqlCmd = 'ALTER TABLE [backupmediafamily] DROP CONSTRAINT ['+@FKName+']'
EXEC (@SqlCmd)
SET @FKName = (SELECT OBJECT_NAME([fk].[constraint_object_id]) FROM [sys].[foreign_key_columns] [fk] WHERE [fk].[referenced_object_id] = OBJECT_ID('backupmediaset') AND [fk].[parent_object_id] = OBJECT_ID('backupset'))
SET @SqlCmd = 'ALTER TABLE [backupset] DROP CONSTRAINT ['+@FKName+']'
EXEC (@SqlCmd)
SET @PKName = (SELECT [name] FROM [sys].[indexes] WHERE [object_id] = OBJECT_ID(N'backupmediaset') AND [name] LIKE N'PK__backupme%' AND [type_desc] = 'CLUSTERED')
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupmediaset] ([media_set_id]) WITH (DROP_EXISTING = ON) ON MediaSetId([media_set_id])'
EXEC (@SqlCmd)
CREATE NONCLUSTERED INDEX [backupmediasetuuid] ON [backupmediaset] ([media_uuid], [media_set_id]) WITH (DROP_EXISTING = ON) ON MediaSetId([media_set_id])
SELECT TOP 0 * INTO [partition] FROM [backupmediaset]
ALTER TABLE [partition] ADD PRIMARY KEY CLUSTERED ([media_set_id])
ALTER TABLE [backupmediaset] SWITCH PARTITION 1 TO [partition]
SET @Output = @Output + (SELECT CAST(COUNT(1) AS VARCHAR)+' rows to delete from [backupmediaset]' FROM [partition]) + CHAR(13) + CHAR(10)
DROP TABLE [partition]
SET @SqlCmd = 'CREATE UNIQUE CLUSTERED INDEX ['+@PKName+'] ON [backupmediaset] ([media_set_id]) WITH (DROP_EXISTING = ON) ON [PRIMARY]'
EXEC (@SqlCmd)
CREATE NONCLUSTERED INDEX [backupmediasetuuid] ON [backupmediaset] ([media_uuid]) WITH (DROP_EXISTING = ON) ON [PRIMARY]
ALTER TABLE [backupmediafamily] WITH CHECK ADD FOREIGN KEY([media_set_id]) REFERENCES [backupmediaset] ([media_set_id])
ALTER TABLE [backupset] WITH CHECK ADD FOREIGN KEY([media_set_id]) REFERENCES [backupmediaset] ([media_set_id])
DROP PARTITION SCHEME MediaSetId
DROP PARTITION FUNCTION MediaSetId
END
SET @Output = @Output + 'All/Any rows deleted successfully.'
END TRY
BEGIN CATCH
SET @Output = @Output + 'Truncate partition failed due to error. ErrorMessage: ' + ISNULL(ERROR_MESSAGE(), '')
IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION
END CATCH
PRINT @Output
IF @@TRANCOUNT > 0 COMMIT TRANSACTION
END
Testing Results
After creating and testing the script locally, I searched for a large msdb databases using the following multi-server query and I found a msdb database that was 40GB.
USE [msdb]
GO
SELECT SUM([size])/128/1024 FROM [sys].[database_files]
To test this process on this database, I restored it locally with the database name “test” and updated the stored procedure “sp_delete_backuphistory” in the restored database to reference the database name “test” instead of “msdb”. This way I can test my new approach versus the system stored procedure that is in the msdb database.

I tested the time it took using stored procedure “sp_delete_backuphistory” to complete:
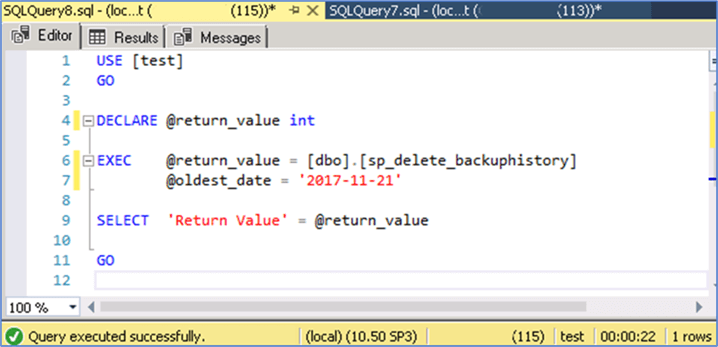
Before I tested my script, I restored the database again and then ran the script to find any missing indexes and then created those missing indexes.

Then I ran the script to partition the table and delete the older data.

We can see that the first approach took 22 seconds and the second approach took 5 seconds. The other advantage of my approach is that it does not cause blocking or filling the transaction log. Since this was a copy of the database there was no other database activity, so we didn’t see any blocking issues, but this would be the case for a busy mdsb database.
I noticed I didn’t get any deletes for the “logmarkhistory” table, so I ran a second multi-server query:
USE [msdb]
GO
SELECT COUNT(1) FROM [logmarkhistory]
I found another msdb database that had around 300K records in this table, so I restored this database and then ran the stored procedure “sp_delete_backuphistory”:

I restored this database again, checked for missing indexes, created the missing indexes and ran the purge using partitions:

As you can see, it took around 28% of the time and without causing blocking or filling the transaction log.
Testing Actual Databases
The last step was to run it against the live databases:
- For SQL Server 2005, after running the first script to find missing indexes, I had to create 4 missing indexes.
- For SQL Server 2008 to 2012, after running the first script to find missing indexes, I had to create 3 missing indexes.
- For SQL Server 2014, after running the first script to find missing indexes, I had to create 1 missing index.
- For SQL Server 2016 and 2017, after running the first script to find missing indexes, I had to create 0 missing indexes.
Next Steps
- To optimize the script for SQL Server 2016, check out this tip.
- You can also modify the script to purge the job history as well.

Pablo Echeverria has worked for more than 10 years as a software programmer and analyst, during which time I studied parallel programming and became a senior programmer specialist. Afterward, he switched to a DBA position implementing new processes and creating better monitoring tools, while growing his data scientist skills to improve my customer’s businesses. Check out Pablo’s most recent book, “Hands-on Data Virtualization with Polybase“. This book brings exciting coverage on establishing and managing data virtualization using Polybase. It teaches how to configure Polybase on almost all relational and nonrelational databases, to setup a test environment for any tool or software instantly without any hassle, and to rapidly design and build high performing data warehousing solutions.
- MSSQLTips Awards: Rising Star (50+ tips) – 2024 | Author Contender – 2018, 2022, 2023 | Rookie Contender – 2017
