Problem
You have a csv file that you would like to import into SQL Server on Linux. What prechecks and massaging of the data can be done first using Linux tools?
Solution
Here is a tip that will show you some Linux tools to use to precheck your csv file. Then we will look at how to work with bcp, the bulk copy program, to import the csv file into SQL Server.
Sample Table Structure for Import
This is the structure of the destination table in SQL Server.
CREATE TABLE [dbo].[Sample] ( [primarykey] [int] NOT NULL, [phase] [varchar] (28) NULL, [GIPIO1] [varchar] (1) NULL, [GIPIO2] [varchar] (1) NULL, [GIPIO3] [varchar] (1) NULL, [GIPIO4] [varchar] (1) NULL, [GIPIO5] [varchar] (1) NULL, [GIPIO6] [varchar] (1) NULL ) ON [PRIMARY] GO
Organization in Linux
I am placing all the work on this task into a folder name import. The ~/import means a folder called import under my home directory.
Prechecks that can be done in Linux
We will look at various commands below.
Number of Rows in File
How many rows are in the csv file?
wc -l sample.csv
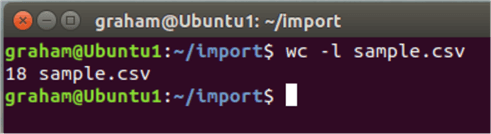
How it works… wc means word count and the -l option says how many lines.
Issue this command man wc to see the manual entry.

Number of Fields Separated by Commas
How many fields, separated by commas, are there in each line?
cat sample.csv | awk -F, '{ print NF }'
The NF flag indicates the number of fields in a row.

From this output we can determine that most rows have 8 fields, but the last few rows are inconsistent.
How awk works in Linux
Awk is a tool that can be given commands to manipulate files. The -F, means that the comma is the field separator.
If we use the uniq command, we can see a summary of the output of the awk command.

uniq -c
This uniq command returns results like the T-SQL SELECT distinct command.
The –c returns the number of each type.
But it will be easier to add the sort command as well to see how many of each type we have.

So, we have one line with 9 fields in it. But before we do anything at all let’s do a backup.
Backup the file first
Let’s copy the file first to have a roll back position.
cp sample.csv sample.csv.$$

The $$ command is the current process number. In that screen shot I have copied the file easily.
View the file contents
We can view the file contents easily:
- cat will concatenate or display the whole file with no controls.
- cat is not a good option for big files.
- more will display a file with keyboard controls. But the more command loads the whole file into memory.
- less is a newer command that has the advantage of not loading the entire file into memory.
As our sample file is small so I chose to use cat to display the file.

We can see the last three rows are rubbish and can be removed.
Remove Bad Lines from File
We can load this little file into an editor and remove the lines. But how would we do that with a large file?
The sed command helps here. We concatenate the sample.csv file through a pipe symbol and into the sed command. The $d means delete the last row.
cat sample.csv | sed '$d' > sample.csv.trimed
Or the -i option operates on the file directly.
sed -i '$d' sample.csv
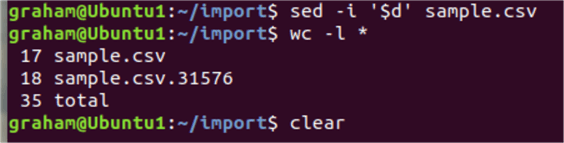
Using wc -l we can see the sample.csv file has been reduced by one line.
We can find row numbers in the file using the cat -n option.

That allows us to pick out the rows to remove using the sed command again. Here we directly name the rows that we wish to delete. And the -i option operates directly on the file again.
sed -i '14d;15d;16d;17d' sample.csv

We have made progress, but now we check again to find if we have a file of similar field counts.
Notice that we only have one row with an extra field.
But what row is it? We can find a row number using awk again. The NF displays the number of fields and the NR shows the row number. Very helpful when the file is large.
cat sample.csv | awk '{ print NF " " NR } '

But if we have a 100,000-line file it would be difficult to spot. So, we can find the row with 9 in it easily. Line 12.

And to display the line we use $0.
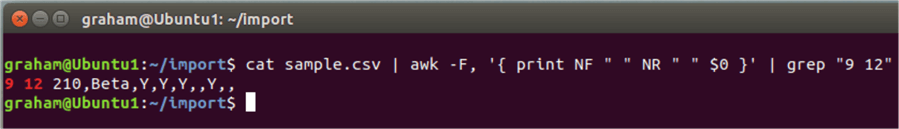
As there is no data to worry about in that extra field so we can do some final formatting. Using the awk command this is easy on a file that is not too wide.
Notice we insert a FS or field separator between each field. The $number variable is for each field read into the awk command.


Loading the File into SQL Server
There are a few methods to load the file.
See tip 1027 for some options.
Here is a link on the Microsoft site for advice on bulk copy with SQL Server on Linux.
Now we can load the final.csv file into SQL Server using the bcp command. You will need to have the command in your PATH variable for that to work.
echo $PATH will show that and whereis will confirm the location of the bcp command.

Now we issue the command:
bcp dbo.sample in ~/import/final.csv -S localhost -U sa -D Administrate -C -T ','

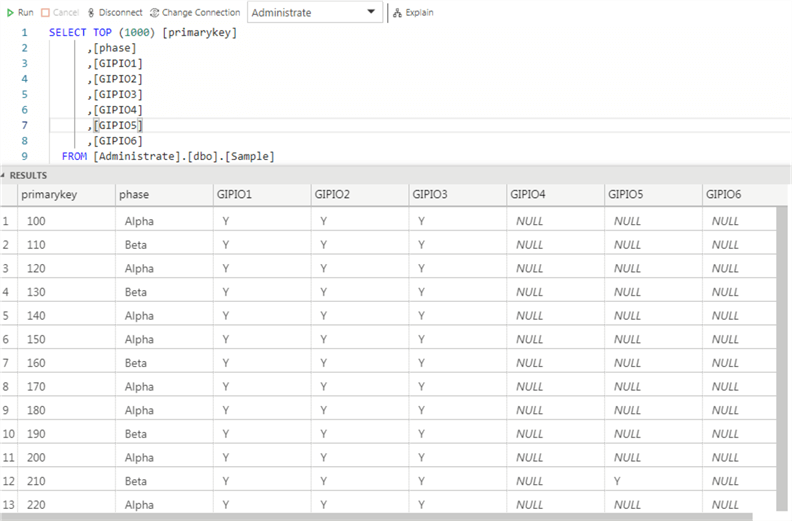
The data is loaded. We can confirm this by checking with SQL Operations Studio.
Automation
Because each flat file may be different we may not be able to automate this massaging. But if your input files are consistently faulty you may not be able to automate the whole process. A neat feature of Linux is to be able to recall your command history. Just type history to see all the commands. To automatically push all your history to a file and edit the file to build your automated command.
history > massage_1.sh
Next Steps
- More Linux tips at MSSQLTips.
- See my tip 5660 on a Status report for SQL Server on Linux.
- A Microsoft site on using SSIS with Linux.
- Have a look at awk.
- This is the Microsoft site for advice on bulk copy with SQL Server on Linux.
- See tip 3208 by Tim Smith for Automating Flat File SQL Server Imports with PowerShell.

Graham is currently a SQL Server DBA and has been working with database systems since 1984. He has been specializing in SQL Server since 2007. He earned a Bachelor of Applied Science Information Technology (With Distinction) from RMIT University in 2006. He is a DBA who has worked for various companies in Western Australia including the government and private sector including mining, oil and gas, health, an ISP and educational institutions. He has worked for Fujitsu as a DBA team leader and at Computer Sciences Corporation as a DBA contractor.
- MSSQLTips Awards: Author of the Year Contender – 2018
