Problem
As a part of the data cleaning process we can use the data flow transformations Fuzzy Lookup and Fuzzy Grouping. Both can be used to standardize and correct data during the load process. A developer may confuse these two options due to similarities between the two transformations, so I will demonstrate the differences between these two components.
Solution
The Fuzzy Lookup performs standardization of data by correcting and providing missing values. While the Fuzzy Grouping transformation performs data cleaning tasks by identifying rows of data that are likely to be duplicated and selecting a canonical row of data to use in standardizing the data. We will demonstrate both of these transformations.
Setup SQL Server Test Environment
First, we will setup a test database Fuzzy_lookup with master table CustomerData and insert some test data.
USE MASTER GO CREATE DATABASE Fuzzy_lookup GO USE Fuzzy_lookup GO CREATE TABLE CustomerData ( custID INT PRIMARY KEY IDENTITY(1,1), SAPCODE INT, customerName NVARCHAR(200), email varchar(100) ) GO INSERT INTO CustomerData SELECT 101,'Bv patel','bv@abc.com' UNION ALL SELECT 102,'su patel','su@gt.com' UNION ALL SELECT 103,'test','test@st.com' UNION ALL SELECT 104,'kb patel','kb@rt.com' UNION ALL SELECT 105,'kkb patel','kkb@kst.com' UNION ALL SELECT 106,'bv patela','kkb@kst.com' GO
Fuzzy Lookup Transformation in SQL Server Integration Services
The Fuzzy Lookup transformation is used for fuzzy matching (not exact but close matching). The lookup transformation uses an equi-join to locate matching records in the reference tables. To be more specific, it returns records with at least one matching record and also returns records with no matching records. However, the transformation requires at least one column match to be configured for fuzzy matching. If you want to use only exact matching, use the Lookup transformation instead.

There are three features for customizing this lookup.
Maximum number of matches to output per lookup
You can set this threshold based on a lookup per column. It means if you set the maximum number of matches to a value greater than 1, the output of the transformation may include more than one row per lookup and some of the rows may be duplicates.

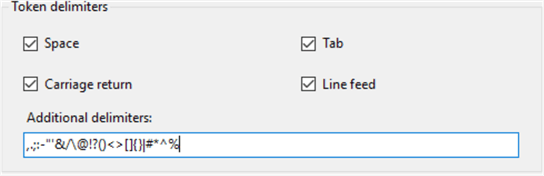
Token delimiters
This provides a default set of delimiters. It’s used to tokenize the data, but you can add custom token delimiters based on requirements to screening your data.
Similarity thresholds
This similarity threshold provides a decimal value between 0 and 1. The value 1 means an exact match between the values of fuzzy matching criteria for desired inputs. The confidence score 0 to 1, indicates the confidence in the match. If no usable match is found, similarity and confidence scores of 0 are assigned to the row and the output columns copied from the reference table will contain null values.

It provides two outputs:
- _Similarity, a column that describes the similarity between values in the input and reference columns.
- _Confidence, a column that describes the quality of the match.
Fuzzy Lookup Example in SQL Server Integration Services
I have CSV file “customerData” shown below. It has two columns name and customerPoints. We also have the Master table CustomerData that we created above. We will use the CSV file and match up against the CustomerData table for our matching.
This is what my finished package will look like:
Flat File Source
As mentioned, I am trying to demonstrate the Fuzzy Lookup transformation with respect to my use case. First, I will use a data flow task to perform this action which I named “GettingCustData”.

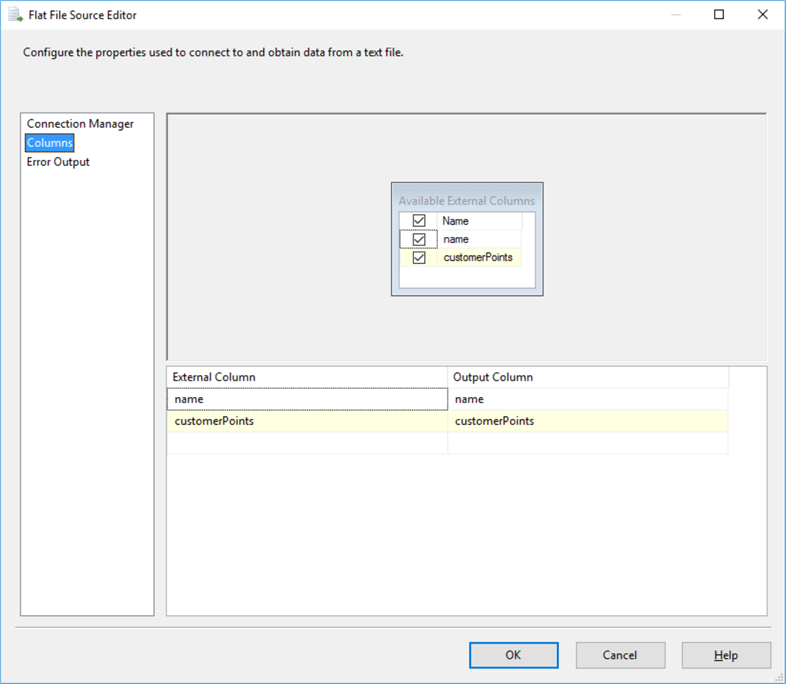
As part of the data flow task, I will use a flat file data source in order to get the customer file “customerData”.

Now in the data flow “GettingCustData” I have configured the above file as a flat file source. As an output of this, I have two columns name and customerPoints.
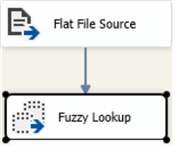
Now, I am going to add the Fuzzy Lookup transformation and link to Flat File Source.
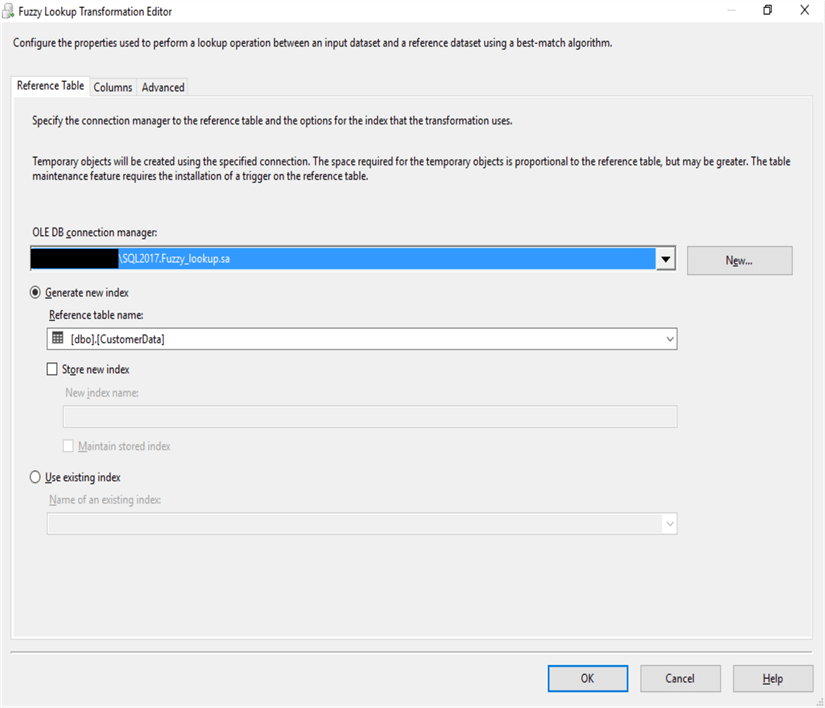
Fuzzy Lookup: Reference Table
As properties of the reference table, I have used the sample master table “CustomerData” column name to link with the flat file column name.
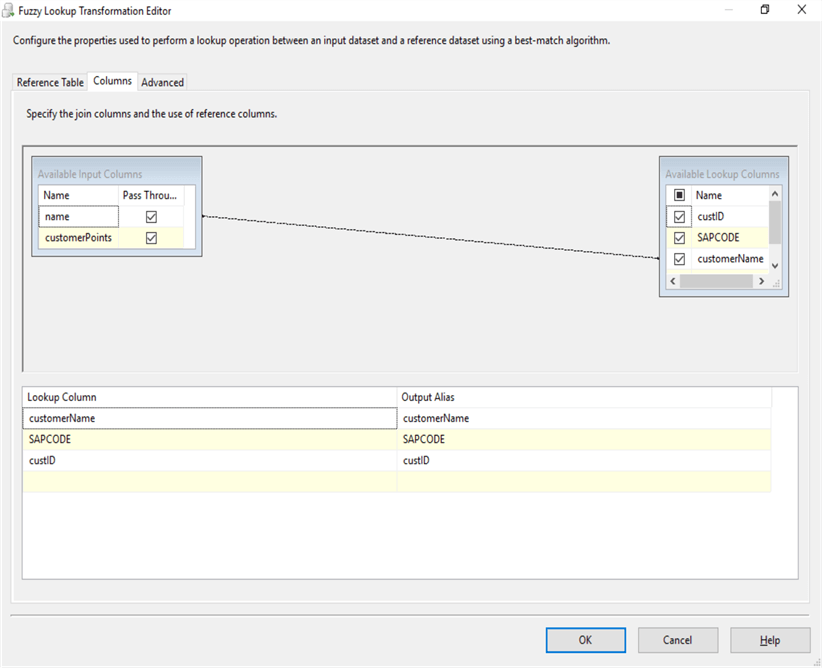
Fuzzy Lookup: Columns
Here, we can configure the column mapping needed for the fuzzy matching.
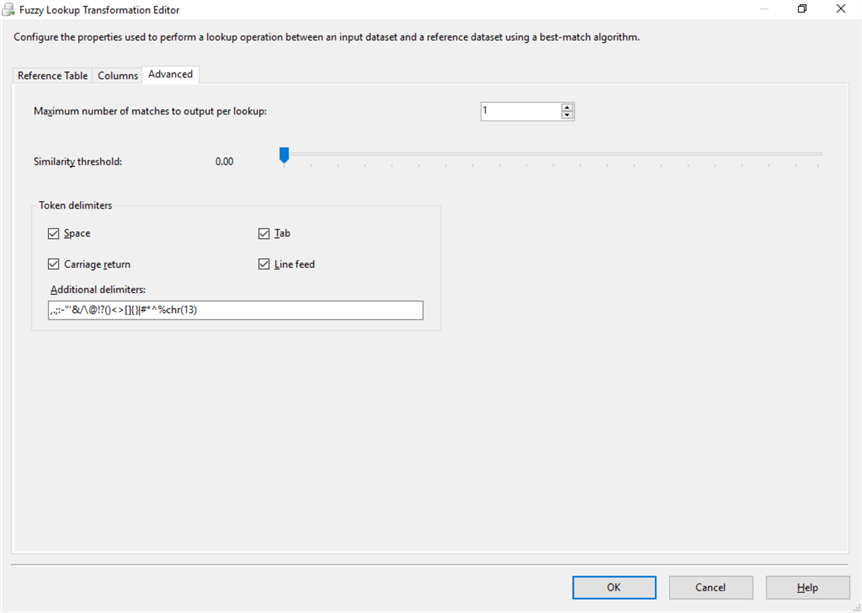
Fuzzy Lookup: Advanced
I need an output once per lookup, so I used 1 for Maximum number of matches to output per lookup. I keep similarity_threshold 0 for visibility of observing the output of the fuzzy lookup with respect to similarities. Also, I kept the default token delimiters.
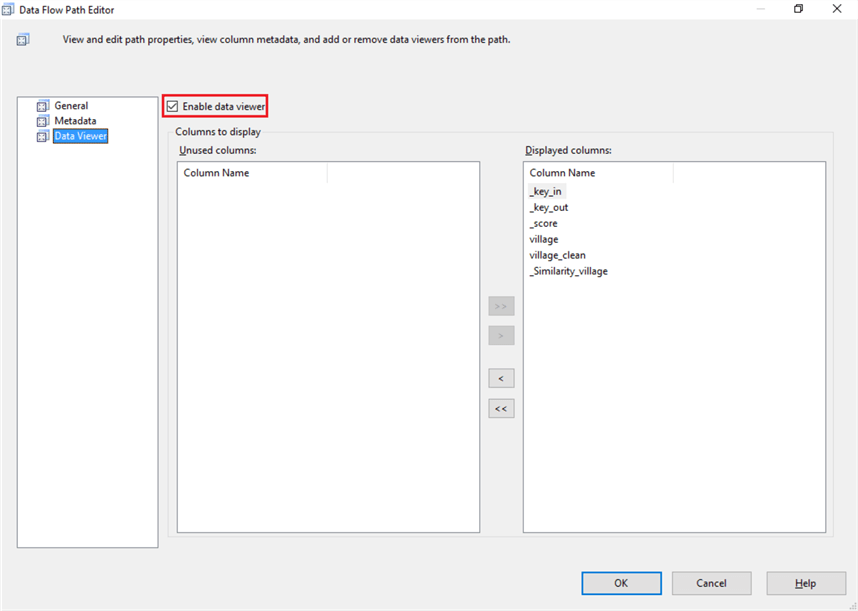
Add a Data Viewer to See Results
After applying the fuzzy transformation, I added a Data Viewer between the Fuzzy Lookup and Conditional Split so we can see what the data looks like. Below is the configuration for this.
I executed the package and the output for the data viewer is shown below.
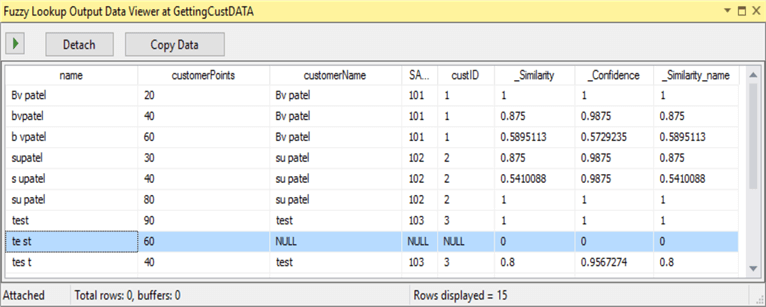
We can see the output columns for the Similarity and Confidence. Also, we can see for the “test” there is no match. So, to handle these different matches, I will add a conditional split as shown below.
Conditional Split
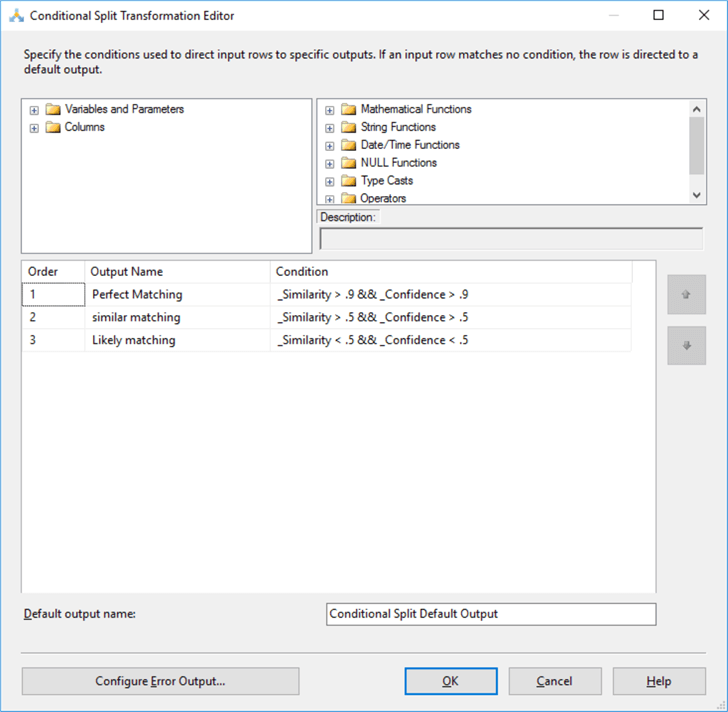
The transformation lets you route your data flow to different outputs, in this demonstration I have used the conditional split transformation in order to get different outputs based on the criteria defined within the transformation editor.
I have divided results into three parts based on the criteria below.
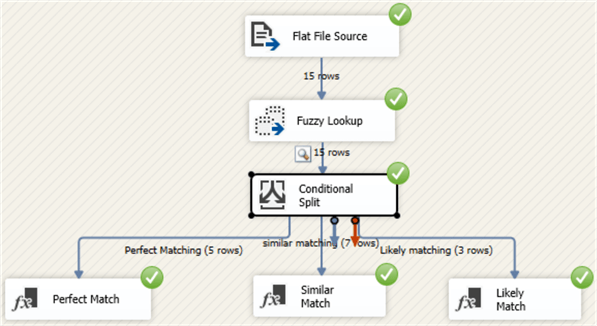
Finished Package
Here is what the finished package looks like. We can see 5 rows were perfect match, 7 rows were similar match and 3 rows a likely match.
Fuzzy Grouping Transformation
The Fuzzy Grouping transformation allows a single input from the data flow and it performs a comparison with itself to try to identify duplicate values from the data. This transformation does not require any reference table to correct the data. It will use the grouping technique to check for typing mistakes and correct them.
To configure the transformation, you must select the input columns to use when identifying duplicates and you must select the type of match; fuzzy or exact for each column.

How to controlling fuzzy grouping?
In the advanced parameters, the fuzzy grouping has the same kind control parameters: token delimiter and similarity threshold. Here I will mention the additional output columns.
- _key_in, a column that uniquely identifies each row.
- _key_out, a column that identifies a group of duplicate rows. The _key_out column has the value of the _key_in column in the canonical data row. Rows with the same value in _key_out are part of the same group. The _key_out value for a group corresponds to the value of _key_in in the canonical data row.
- _score, a value between 0 and 1 that indicates the similarity of the input row to the canonical row.
Fuzzy Grouping Example in SQL Server Integration Services
I have a CSV file which has a village column. I have many village duplicates and I need to refine this for unique villages.
Use Fuzzy Grouping in order to perform my scenario
Here is my CSV file “VillageData”.

On Data Flow task I configured the above as a flat file source.
Now, I am going to add a Fuzzy Group transformation and link to Flat File Source.

Fuzzy Grouping: Connection Manager
Here you can specify an OLE DB connection, but I am not using a database for this example.
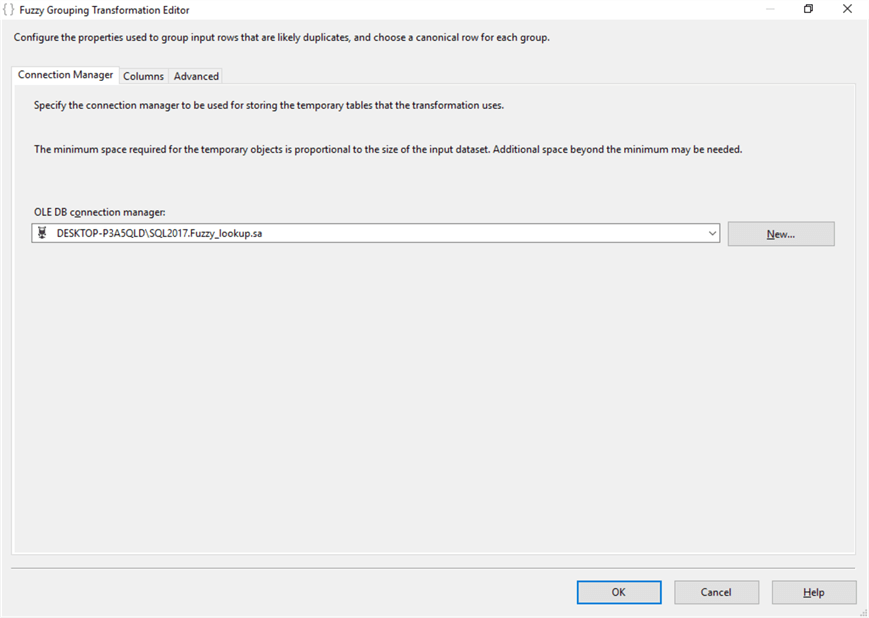
Fuzzy Grouping: Columns
I have selected the column village. There are two options available in the match type; Exact and Fuzzy. Rows are considered duplicates if they are similar with a Fuzzy match type. If you specify Exact, only rows that contain identical values are considered duplicates.

Fuzzy Grouping: Advanced
As mentioned above, the fuzzy grouping advanced tab we have; token delimiters, similarity threshold and other output columns. I set the similarity threshold to 0.35 for this example.

Add a Data Viewer to See Results
I added a data viewer between the Fuzzy Grouping and Derived Column and my package looks this.

I executed the package and we can see the data viewer below.

I have got the corrected village name in village_clean column. You can also review the _key_out versus _key_in.I marked the groups in the _key_out column where the data would be grouped.
Differences Between Fuzzy Lookup and Fuzzy Grouping in SSIS
Here are the differences between these two transformations.
| Fuzzy lookup | Fuzzy Grouping |
|---|---|
| Fuzzy Lookup performs data standardization, correcting and providing missing values. | Fuzzy Grouping performs a data cleaning task by identifying rows of data that are likely to be duplicates. |
| Fuzzy Lookup enables you to match input records with clean, standardized records in a reference table. | Fuzzy Grouping enables you to identify groups of records in a table where each record in the group potentially corresponds to the same real-world entity. |
| Fuzzy Lookup returns the closest match in order to perform the fuzzy join. | Fuzzy Grouping is useful for grouping together in order to perform two join options; Fuzzy and Exact. |
| For Fuzzy Lookup the comparison is made with a reference table. | For Fuzzy Grouping the comparison is done with input data itself. |
| This is blocking transformation. | This is blocking transformation. |
| Only input columns with the DT_WSTR and DT_STR data types can be used in fuzzy matching | Exact matching can be applied to columns of all data types except DT_TEXT, DT_NTEXT, and DT_IMAGE. The method for approximate matching of data is based on a user-specified similarity score. It provides fuzzy matching to columns DT_WSTR and DT_STR data types. |
Next Steps
- Check out the SQL Server Integration Services tutorial.
- Read more about Transformation in SQL Server Integration Services.
- Read more about Exact differences between Fuzzy Lookup and Fuzzy Grouping.

Bhavesh Patel is a SQL Server database professional with 10+ years of experience. Most of his career has been working on database development and administration. He has a strong interest in continuous learning and likes facing challenges to learn new things. In his spare time, he spends time with his family. Currently, his main role is query tuning with respect to optimization and server performance.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2019 | Rookie of the Year Contender – 2017



I have been using SSIS since it replaced DTS, and I have never needed this transform–until I did! Thanks for writing this up so clearly.
Hi Bhavesh, great post. I am using Fuzzy grouping transformation for some cleaning tasks but sometimes it fails and I don’t see the built-in output to handle errors, I am wondering if there is a way to redirect the problematic rows and leave the ones that are working to carry on with the transformation process, do you know a solution for this?