Problem
Is there a difference between using the T-SQL IN operator or the EXISTS operator in a WHERE clause to filter for specific values in SQL queries and stored procedures? Is there a logical difference, a performance difference or are they exactly the same? And what about NOT IN and NOT EXISTS?
Solution
In this SQL tutorial we’ll investigate if there are any differences between the EXISTS and the IN operator. This can either be logical, i.e. they behave different under certain circumstances, or performance-wise, meaning if using one operator has a performance benefit over the other. We’ll be using the AdventureWorks DW 2017 sample database for our test queries for the Microsoft SQL Server DBMS.
SQL IN vs EXISTS Syntax
The IN operator is typically used to filter a column for a certain list of values. For example, review this SELECT statement:
SELECT
[ProductSubcategoryKey]
,[EnglishProductSubcategoryName]
,[ProductCategoryKey]
FROM [AdventureWorksDW2017].[dbo].[DimProductSubcategory]
WHERE [ProductCategoryKey] IN (1,2);
This query searches for all the product subcategories which belong to the product categories Bikes and Categories (ProductCategoryKey 1 and 2).

You can also use the IN operator to search the values in the result set of a subquery with the following SQL commands:
SELECT
[ProductSubcategoryKey]
,[EnglishProductSubcategoryName]
,[ProductCategoryKey]
FROM [AdventureWorksDW2017].[dbo].[DimProductSubcategory]
WHERE [ProductCategoryKey] IN
(
SELECT [ProductCategoryKey]
FROM [dbo].[DimProductCategory]
WHERE [EnglishProductCategoryName] = 'Bikes'
);
This query returns all subcategories linked to the Bikes category.

The benefit of using a subquery is that the query becomes less hard-coded; if the ProductCategoryKey changes for some reason, the second query will still work, while the first query might suddenly return incorrect results. It’s important though the subquery returns exactly one column for the IN operator to work.
The EXISTS operator doesn’t check for values, but instead checks for the existence of rows. Typically, a subquery is used in conjunction with EXISTS. It actually doesn’t matter what the subquery returns, as long as rows are returned.
This query will return all rows from the ProductSubcategory table, because the inner subquery returns rows (which are not related to the outer query at all).
SELECT
[ProductSubcategoryKey]
,[EnglishProductSubcategoryName]
,[ProductCategoryKey]
FROM [AdventureWorksDW2017].[dbo].[DimProductSubcategory]
WHERE EXISTS (
SELECT 1/0
FROM [dbo].[DimProductCategory]
WHERE [EnglishProductCategoryName] = 'Bikes'
);
As you might have noticed, the subquery has 1/0 in the SELECT clause. In a normal query, this would return a divide by zero error, but inside an EXISTS clause it’s perfectly fine, since this division is never calculated. This demonstrates that it’s not important what the subquery returns, as long as rows are returned.
To use EXISTS in a more meaningful way, you can use a correlated subquery. In a correlated subquery, we pair values from the outer query with values from the inner (sub)query. This effectively checks if the value of the outer query exists in the table used in the inner query. For example, if we want to return a list of all employees who made a sale, we can write the following query:
SELECT
[EmployeeKey]
,[FirstName]
,[LastName]
,[Title]
FROM [AdventureWorksDW2017].[dbo].[DimEmployee] e
WHERE EXISTS (
SELECT 1
FROM dbo.[FactResellerSales] f
WHERE e.[EmployeeKey] = f.[EmployeeKey]
);
In the WHERE clause inside the EXISTS subquery, we correlate the employee key of the outer table – DimEmployee – with the employee key of the inner table – FactResellerSales. If the employee key exists in both tables, a row is returned and EXISTS will return true. If an employee key is not found in FactResellerSales, EXISTS returns false and the employee is omitted from the results:

We can implement the same logic using the IN operator with the following SQL statement:
SELECT
[EmployeeKey]
,[FirstName]
,[LastName]
,[Title]
FROM [AdventureWorksDW2017].[dbo].[DimEmployee] e
WHERE [EmployeeKey] IN (
SELECT [EmployeeKey]
FROM dbo.[FactResellerSales] f
);
Both queries return the same result set, but maybe there is an underlying performance difference? Let’s compare the execution plans.
This is the plan for EXISTS:
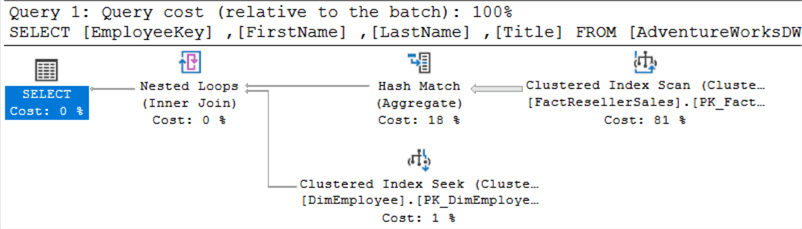
This is the plan for IN:
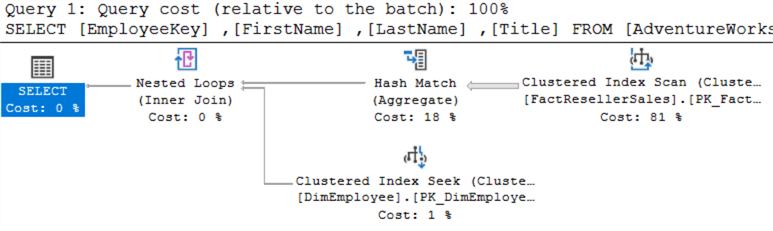
They look exactly the same. When executing both queries at the same time, you can see they get assigned the same cost:

The top execution plan is for EXISTS, the bottom one for IN.
Let’s take a look at the IO statistics (you can show these by running the statement SET STATISTICS IO ON). Again, everything is exactly the same:

So, there’s no performance difference that we can prove and both return the same result sets. When would you choose to use one or the other? Here are some guidelines:
- If you have a small list of static values (and the values are not present in some table), the IN operator is preferred.
- If you need to check for existence of values in another table, the EXISTS operator is preferred as it clearly demonstrates the intent of the query.
- If you need to check against more than one single column, you can only use EXISTS since the IN operator only allows you to check for one single column.
Let’s illustrate the last point with an example. In the AdventureWorks data warehouse, we have an Employee dimension. Some employees manage a specific sales territory:

Now, it’s possible that a sales person also makes sales in other territories. For example, Michael Blythe - responsible for the Northeast region - has sold in 4 distinct regions:
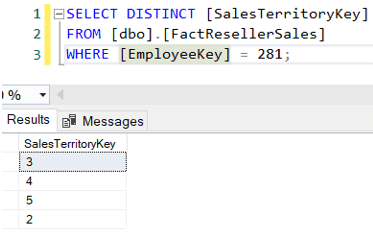
Let’s suppose we now only want to find the sales amounts for the sales territory managers, but only for their own region. A possible SQL query could be:
SELECT
f.[EmployeeKey]
,f.[SalesTerritoryKey]
,SUM([SalesAmount])
FROM [dbo].[FactResellerSales] f
WHERE EXISTS
(
SELECT 1
FROM [dbo].[DimEmployee] e
WHERE f.[EmployeeKey] = e.[EmployeeKey]
AND f.[SalesTerritoryKey] = e.[SalesTerritoryKey]
AND e.[SalesTerritoryKey] <> 11 -- the NA region
)
GROUP BY f.[EmployeeKey]
,f.[SalesTerritoryKey];
The result is as follows:

Inside the EXISTS clause, we retrieve the sales territories managers by filtering out all employees linked to the NA region. In the outer query, we get all sales per sales territory and employee, where the employee and territory is found in the inner query. As you can see, EXISTS allows us to easily check on multiple columns, which is not possible with IN.
SQL Server NOT IN vs NOT EXISTS
By prefixing the operators with the NOT operator, we negate the Boolean output of those operators. Using NOT IN for example will return all rows with a value that cannot be found in a list.

There is one special case though: when NULL values come into the picture. If a NULL value is present in the list, the result set is empty!

This means that NOT IN can return unexpected results if suddenly a NULL value pops up in the result set of the subquery. NOT EXISTS doesn’t have this issue, since it doesn’t matter what is returned. If an empty result set is returned, NOT EXISTS will negate this, meaning the current record isn’t filtered out:

The query above returns all employees who haven’t made a sale. Logically, NOT IN and NOT EXISTS are the same – meaning they return the same result sets – as long as NULLS aren’t involved. Is there a performance difference? Again, both query plans are the same:

The same goes for the IO statistics:
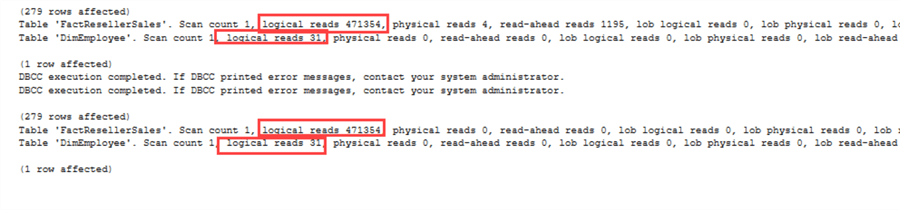
There is one gotcha though. The EmployeeKey is not-nullable in FactResellerSales. As demonstrated before, NOT IN can have issues when NULLs are involved. If we change EmployeeKey to be nullable, we get the following execution plans:

Quite a difference this time! Because SQL Server now has to take NULL values into account, the execution plan changes. The same can be seen in the IO statistics:

Now there’s an actual performance difference between NOT IN and NOT EXISTS. When to use which operator? Some guidelines:
- The same guidelines as for IN and EXISTS can be applied. For checking against a small static list, NOT IN is preferred. Checking for existence in another table? NOT EXISTS is the better choice. Checking against multiple columns, again NOT EXISTS.
- If one of the columns is nullable, NOT EXISTS is preferred.
Using Joins Instead of IN or EXISTS
The same logic can be implemented with joins as well. An alternative for IN and EXISTS is an INNER JOIN, while a LEFT OUTER JOIN with a WHERE clause checking for NULL values can be used as an alternative for NOT IN and NOT EXISTS. The reason they are not included in this tip – even though they might return the exact same result set and execution plan – is because the intent is different. With IN and EXISTS, you check for the existence of values in another record set. With joins you merge the result sets, which means you have access to all columns of the other table. Checking for existence is more of a "side-effect". When you use (NOT) IN and (NOT) EXISTS, it’s really clear what the intent of your query is. Joins on the other hand can have multiple purposes.
Using an INNER JOIN, you can also have multiple rows returned for the same value if there are multiple matches in the second table. If you want to check for existence and if a value exist you need a column from the other table, joins are preferred.
Next Steps
- You can find more T-SQL tips in this overview.
- Long-time MVP Gail Shaw has a nice series on EXISTS vs IN vs SQL JOINS. If you’re interested in comparing EXISTS/IN versus the JOINS, you can read the following blog posts:
- IN vs INNER JOIN
- LEFT OUTER JOIN vs NOT EXISTS
- SQL Server Join Tips
- Tip: SQL Server Join Example
- Learn more about the SQL SELECT statement
- Learn more about the SQL LIKE command

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025

![SQL IS [NOT] DISTINCT FROM predicate in SQL Server 2022](https://www.mssqltips.com/wp-content/uploads/8195_s.webp)
Hi Jeff,
a little bit about the query, I explain how the employee table looks like and that each sales employee is responsible for a specific region. Then I explain that some sales persons have made sales for different regions, not just the ones the person is responsible for. In the final query, we use EXISTS to check if a sale was made for a sales person on the region they are responsible for. This is done by the following condition:
f.[EmployeeKey] = e.[EmployeeKey] AND f.[SalesTerritoryKey] = e.[SalesTerritoryKey]
–> meaning the employeekey from the fact table must match an employeekey in the employee table, but also the sales territory key from the fact table must match with the sales territory key in the employee table (this is the sales territory the employee is responsible for)
Hope this helps.
Koen
It’s not just INNER JOIN that can return duplicate results. Any JOIN could do that. Great article! I use both EXISTS and IN in my queries. Fortunately for me, I tend to use them the exact way you suggested. Thank you for the detailed explanation and comparisons.
Very good point showing difference between IN vs. EXISTS/JOIN. However the example and the query (esp. group by and amount one) is not easy to understand, appreciate if showing the details of all involving tables, or choose an easier example or query to demonstrate.
Thanks, nice post