Problem
I would like to know the number of rows affected by my SQL Server query. I know this is displayed as a message in SQL Server Management Studio, but I have to check the number of rows in an IF statement to verify if everything went alright. How can I do this in SQL Server?
Solution
The T-SQL language provides us with the @@ROWCOUNT system variable. This variable returns the number of rows affected by the last executed statement in the batch. In this tip, we’ll demonstrate how to use this variable and point out some caveats.
Using SQL Server @@ROWCOUNT
The usage of the variable is straight forward. You simply select if after the statement you wish to check as shown below:

The statement can be anything that affects rows: SELECT, INSERT, UPDATE, DELETE and so on. It’s important that @@ROWCOUNT is called in the same execution as the previous query.
Suppose I would run the SELECT statement first from the previous example, and then run SELECT @@ROWCOUNT separately. This will return 1 instead of 1,000 as shown below:
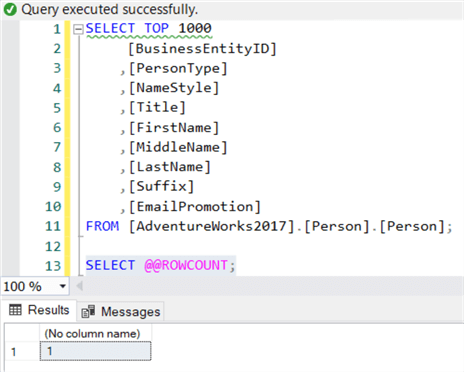
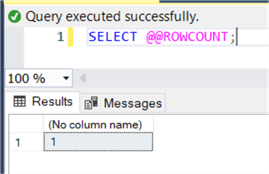
This is because executing SELECT @@ROWCOUNT by itself returns 1. If you open a new query window (and thus a new session) and you fetch @@ROWCOUNT, the value of 1 will be returned:
Using SQL Server @@ROWCOUNT for Error Handling and Checking a Business Rule
Typically, @@ROWCOUNT is used for error handling or for checking a business rule. You can access @@ROWCOUNT like any other variable in an IF statement. For example:

In this script, we perform an UPDATE statement. After the statement is done, we check if any rows were updated at all. If not, a message will be printed. In reality, you can take other actions such as throwing an error message with RAISERROR, send an e-mail or kick of some stored procedure. The transaction is used in the example to roll back the update, so we don’t mess with our sample database.
Here’s the script if you want to run it yourself:
BEGIN TRAN
UPDATE [Sales].[SalesOrderHeader]
SET [SubTotal] = [SubTotal] * 1.1; -- 10% increase
IF @@ROWCOUNT = 0
PRINT 'Something went wrong!'
ELSE PRINT 'Rows were updated...'
--COMMIT
ROLLBACKSQL Server ROWCOUNT_BIG function
The data type of @@ROWCOUNT is integer. In the cases where a higher number of rows are affected than an integer can handle (meaning more than 2,147,483,647 rows!), you need to use the ROWCOUNT_BIG function. This function returns the data type bigint.
Here is an example of how to use this function:

SQL Server @@ROWCOUNT with Try Catch
Sometimes it can be a bit confusing as what the last executed statement will be. Take the following script for example:
BEGIN TRY
SELECT TOP 100 * FROM [AdventureWorks2017].[Person].[Person];
END TRY
BEGIN CATCH
SELECT TOP 50 * FROM [AdventureWorks2017].[Person].[Person];
END CATCH
SELECT @@ROWCOUNT;What will @@ROWCOUNT return if the catch block isn’t executed? What if it is? Let’s try executing the query:

@@ROWCOUNT returns zero! This is because the last statement is not the SELECT statement from the TRY block (which has been executed), it’s also not the one from the CATCH block as it’s the last SELECT in the script. It’s the TRY/CATCH block itself! @@ROWCOUNT returns the affected rows from any statement, even if it’s not DML or a SELECT query.
To avoid this kind of scenario, you can store the row count in a local variable. The script would then look like this:
DECLARE @rowcount INT;
BEGIN TRY
SELECT TOP 100 * FROM [AdventureWorks2017].[Person].[Person];
SET @rowcount = @@ROWCOUNT;
END TRY
BEGIN CATCH
SELECT TOP 50 * FROM [AdventureWorks2017].[Person].[Person];
SET @rowcount = @@ROWCOUNT;
END CATCH
SELECT @rowcount;SQL Server SET NOCOUNT AND SET ROWCOUNT
Although the name, SET ROWCOUNT is very similar, it doesn’t impact @@ROWCOUNT directly. SET ROWCOUNT simply tells SQL Server to stop processing a query after the specified number of rows have been returned, which makes it kind of a “global TOP clause”.
In the following example, we’re limiting the rows to 500. The SELECT query itself should return 1,000 rows, but as you can see @@ROWCOUNT tells us only 500 were returned.

SET NOCOUNT ON also doesn’t affect @@ROWCOUNT. SET NOCOUNT tells SQL Server to stop displaying the message with the number of rows affected by a query. However, @@ROWCOUNT is still updated.
Let’s illustrate with an example. First the default configuration where NOCOUNT is off.

When we set NOCOUNT to ON, the Messages tab will not display the value.

If we look at the Results, the row count however is still correct.

Using SQL Server @@ROWCOUNT with the MERGE statement
The MERGE statement is a bit special, as it can perform insert, updates and deletes at the same time. What does @@ROWCOUNT return in such a case? Let’s try it out.
The following script creates two temporary tables with some sample data:
DROP TABLE IF EXISTS #Source;
DROP TABLE IF EXISTS #Target;
SELECT ID = 1, TestValue = 'Bruce'
INTO #Target
UNION ALL
SELECT ID = 2, TestValue = 'Selina'
UNION ALL
SELECT ID = 3, TestValue = 'Richard';
SELECT * FROM #Target;
SELECT ID = 1, TestValue = 'Bruce'
INTO #Source
UNION ALL
SELECT ID = 2, TestValue = 'Cat'
UNION ALL
SELECT ID = 4, TestValue = 'Jason';
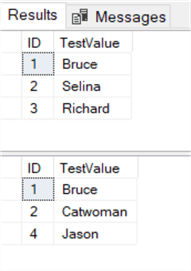
SELECT * FROM #Source;Here is what the data looks like.
We’re going to run the following MERGE statement:
MERGE [#Target] AS TARGET
USING (SELECT * FROM [#Source]) AS SOURCE
ON [SOURCE].[ID] = [TARGET].[ID]
WHEN MATCHED AND [SOURCE].[TestValue] <> [TARGET].[TestValue] THEN
UPDATE SET [TARGET].[TestValue] = [SOURCE].[TestValue]
WHEN NOT MATCHED BY SOURCE THEN DELETE
WHEN NOT MATCHED THEN
INSERT (ID,[TestValue])
VALUES ([SOURCE].ID,[SOURCE].TestValue);
SELECT @@ROWCOUNTThis statement will:
- delete the row with ID 3 from the target
- it will insert one new row
- and update row ID 2.
When the statement is executed, @@ROWCOUNT will return the value 3.
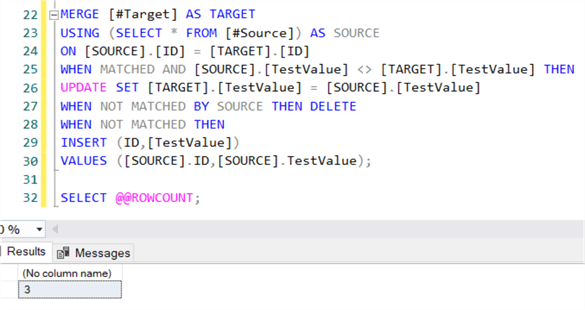
@@ROWCOUNT returns the total number rows affected by the MERGE statement which is correct, but this might make debugging or troubleshooting a bit more difficult, since you do not know how many rows were deleted, updated or inserted.
Using SQL Server @@ROWCOUNT with the MERGE statement and OUTPUT clause
A possible work around is to include the OUTPUT clause.
First, we need to create a logging table:
CREATE TABLE #LoggingTable
(ExistingID INT,
ExistingTestValue VARCHAR(50),
ActionTaken NVARCHAR(10),
[NewID] INT,
NewTestValue VARCHAR(50)
);We need to reset the data to rerun the example, so run the script above that creates the temporary tables and inserts the sample data.
Then we append the OUTPUT clause to the MERGE statement and insert the results into the logging table.
MERGE [#Target] AS TARGET
USING (SELECT * FROM [#Source]) AS SOURCE
ON [SOURCE].[ID] = [TARGET].[ID]
WHEN MATCHED AND [SOURCE].[TestValue] <> [TARGET].[TestValue] THEN
UPDATE SET [TARGET].[TestValue] = [SOURCE].[TestValue]
WHEN NOT MATCHED BY SOURCE THEN DELETE
WHEN NOT MATCHED THEN
INSERT (ID,[TestValue])
VALUES ([SOURCE].ID,[SOURCE].TestValue);
OUTPUT deleted.*, $action, inserted.* INTO #LoggingTable;
After the MERGE statement has been executed, we can inspect the results in the logging table:
SELECT * FROM #LoggingTable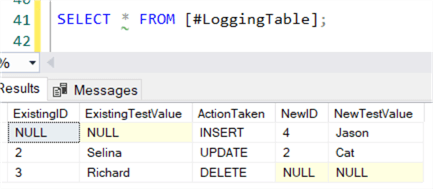
We now have a detailed view of what the MERGE statement has done.
A downside of this approach is the data duplication into the logging table, which can be troublesome when the MERGE statement has to handle large amounts of data.
Next Steps
- See these related articles:

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025



Hi Toby,
you’re absolutely correct, thanks for pointing it out!
I’ll have it adjusted.
Greetings,
Koen
I think there might be a minor mistake in this text: “This is because the last statement is not the SELECT statement from the TRY block (which has been executed), it’s also not the one from the TRY block as it’s the last SELECT in the script. It’s the TRY/CATCH block itself!”
I think you meant to write “it’s also not the one from the CATCH block as it’s the last SELECT in the script.” I figured it out, but thought you’d want to know. Excellent article!
THANK YOU!!
Excellent article. Just when you think you’ve learned everything about a Merge statement, along comes an article like this that makes you say WOW! I didn’t know that! I bookmarked it as well.