Problem
You’ve been asked to provide some data analysis on SQL Server database tables to get a better understanding on how columns are used as well as how the different data types that were selected for a table have been used. In this tip we look at a script that you can use to get better insight on your database tables to help you make some decisions about the data and also the structure of the table. This is also a useful step before loading data into a machine learning process to get an understanding of what data columns are useful to use and which ones can be ignored.
Solution
With the script below, you only need to enter the SQL Server database, schema name and table name, and it takes care of gathering the most important statistics about the table for you. By performing the data analysis locally, you can determine the best approach to load the data, treat missing values, train a machine learning model, and provide insights to the business.
Script
USE [AdventureWorks2014] -- Your database goes here
--DBCC DROPCLEANBUFFERS
--SET STATISTICS TIME ON
DECLARE @schema SYSNAME, @table SYSNAME
SET @schema = 'HumanResources' -- Your schema goes here
SET @table = 'Employee' -- Your table goes here
CREATE TABLE #Info ([Column] SYSNAME, [SystemType] TINYINT, [UserType] INT, [Min] VARCHAR(MAX), [Max] VARCHAR(MAX), [Std] VARCHAR(MAX), [Var] VARCHAR(MAX), [Mean] VARCHAR(MAX), [Mode] VARCHAR(MAX), [DistinctRows] BIGINT, [MissingRows] BIGINT)
CREATE TABLE #Info2 ([Column] SYSNAME, [Std] VARCHAR(MAX), [Var] VARCHAR(MAX), [Avg] VARCHAR(MAX))
CREATE TABLE #Info3 ([Column] SYSNAME, [Mode] VARCHAR(MAX), [NA] BIGINT)
CREATE TABLE #Info4 ([Column] SYSNAME, [Dis] BIGINT)
DECLARE @count BIGINT, @cmd VARCHAR(MAX)
-- Number of rows
SELECT @count = SUM([row_count])
FROM [sys].[dm_db_partition_stats]
WHERE [object_id] = OBJECT_ID(@schema+'.'+@table)
-- Min, Max
SET @cmd = ''
SELECT @cmd = @cmd + 'MIN('+[name]+') [Min'+[name]+'],MAX('+[name]+') [Max'+[name]+'],'
FROM [sys].[columns]
WHERE [object_id] = OBJECT_ID(@schema+'.'+@table)
AND [user_type_id] NOT IN (104, 189, 258) --BIT, TIMESTAMP, FLAG
SET @cmd = LEFT(@cmd, LEN(@cmd)-1)
SELECT @cmd = 'SELECT ' + @cmd + ' INTO [tmp] FROM ['+@schema+'].['+@table+']'
EXEC (@cmd)
SET @cmd = ''
SELECT @cmd = @cmd + 'SELECT '''+[name]+''','+CAST([system_type_id] AS VARCHAR(MAX))+','+CAST([user_type_id] AS VARCHAR(MAX))+',CAST([Min'+[name]+'] AS VARCHAR(MAX)),CAST([Max'+[name]+'] AS VARCHAR(MAX)) FROM [tmp]
UNION ALL
'
FROM [sys].[columns]
WHERE [object_id] = OBJECT_ID(@schema+'.'+@table)
AND [user_type_id] NOT IN (104, 189, 258) --BIT, TIMESTAMP, FLAG
SET @cmd = 'INSERT #Info([Column],[SystemType],[UserType],[Min],[Max]) ' + LEFT(@cmd, LEN(@cmd)-10)
EXEC (@cmd)
-- Delete null columns
DELETE
FROM #Info
WHERE [Min] IS NULL
AND [Max] IS NULL
-- STDEV, VAR, AVG
SET @cmd = ''
SELECT @cmd = @cmd + 'STDEV('+[Column]+') [Std'+[Column]+'],VAR('+[Column]+') [Var'+[Column]+'],AVG('+[Column]+') [Avg'+[Column]+'],'
FROM #Info
WHERE [UserType] IN (48, 52, 56, 59, 60, 62, 106, 122, 127)
SET @cmd = LEFT(@cmd, LEN(@cmd)-1)
SELECT @cmd = 'SELECT ' + @cmd + ' INTO [tmp2] FROM ['+@schema+'].['+@table+']'
EXEC (@cmd)
SET @cmd = ''
SELECT @cmd = @cmd + 'SELECT '''+[Column]+''',CAST([Std'+[Column]+'] AS VARCHAR(MAX)),CAST([Var'+[Column]+'] AS VARCHAR(MAX)),CAST([Avg'+[Column]+'] AS VARCHAR(MAX)) FROM [tmp2]
UNION ALL
'
FROM #Info
WHERE [UserType] IN (48, 52, 56, 59, 60, 62, 106, 122, 127)
SET @cmd = 'INSERT #Info2 ' + LEFT(@cmd, LEN(@cmd)-10)
EXEC (@cmd)
UPDATE [i]
SET [i].[Mean] = [i2].[Avg], [i].[Std] = [i2].[Std], [i].[Var] = [i2].[Var]
FROM #Info [i]
INNER JOIN #Info2 [i2] ON [i2].[Column] = [i].[Column]
-- Mode, missing rows
SET @cmd = ''
SELECT @cmd = @cmd + '(SELECT TOP 1 CAST(['+[Column]+'] AS VARCHAR(MAX))+'' (''+CAST([cn] AS VARCHAR(MAX))+'')'' FROM (
SELECT ['+[Column]+'], COUNT(1) [cn]
FROM ['+@schema+'].['+@table+']
WHERE ['+[Column]+'] IS NOT NULL
GROUP BY ['+[Column]+']) [a]
ORDER BY [cn] DESC) [Mode'+[Column]+'],
(SELECT COUNT(1)
FROM ['+@schema+'].['+@table+']
WHERE ['+[Column]+'] IS NULL) [NA'+[Column]+'],'
FROM #Info
SET @cmd = LEFT(@cmd, LEN(@cmd)-1)
SELECT @cmd = 'SELECT ' + @cmd + ' INTO [tmp3]'
EXEC (@cmd)
SET @cmd = ''
SELECT @cmd = @cmd + 'SELECT '''+[Column]+''',CAST([Mode'+[Column]+'] AS VARCHAR(MAX)),[NA'+[Column]+'] FROM [tmp3]
UNION ALL
'
FROM #Info
SET @cmd = 'INSERT #Info3 ' + LEFT(@cmd, LEN(@cmd)-10)
EXEC (@cmd)
UPDATE [i]
SET [i].[Mode] = [i2].[Mode], [i].[MissingRows] = [i2].[NA]
FROM #Info [i]
INNER JOIN #Info3 [i2] ON [i2].[Column] = [i].[Column]
-- Count distinct
SET @cmd = ''
SELECT @cmd = @cmd + 'COUNT(DISTINCT ['+[Column]+']) [Dis'+[Column]+'],'
FROM #Info
SET @cmd = LEFT(@cmd, LEN(@cmd)-1)
SELECT @cmd = 'SELECT ' + @cmd + ' INTO [tmp4] FROM ['+@schema+'].['+@table+']'
EXEC (@cmd)
SET @cmd = ''
SELECT @cmd = @cmd + 'SELECT '''+[Column]+''',[Dis'+[Column]+'] FROM [tmp4]
UNION ALL
'
FROM #Info
SET @cmd = 'INSERT #Info4 ' + LEFT(@cmd, LEN(@cmd)-10)
EXEC (@cmd)
UPDATE [i]
SET [i].[DistinctRows] = [i2].[Dis]
FROM #Info [i]
INNER JOIN #Info4 [i2] ON [i2].[Column] = [i].[Column]
-- Return results
SELECT [i].[Column], [t].[name] [Type], [i].[Min], [i].[Max], [i].[Std], [i].[Var], [i].[Mean], [i].[Mode], @count [Rows], [i].[MissingRows], [i].[DistinctRows]
FROM #Info [i]
INNER JOIN [sys].[types] [t] ON [t].[system_type_id] = [i].[SystemType] AND [t].[user_type_id] = [i].[UserType]
DROP TABLE #Info
DROP TABLE #Info2
DROP TABLE #Info3
DROP TABLE #Info4
DROP TABLE [tmp]
DROP TABLE [tmp2]
DROP TABLE [tmp3]
DROP TABLE [tmp4]
Script Description
The script is divided into the following sections:
1 – Preparation (lines 1 to 10)
- We will use four temporary tables and internally it is going to use another four tables that will get dropped at the end.
2 – Get number of rows (lines 11 to 14)
- This will be useful when counting the missing values, the mode, and the unique value count.
3 – Get min and max values (lines 15 to 32)
- Since these functions are independent of the data type, we can get these for all columns except TIMESTAMP. We calculate this for all columns in parallel and load the results into a new table named [tmp] with a dynamic query that looks like this:
SELECT MIN(ColumnA) [MinColumnA], MAX(ColumnA) [MaxColumnA], MIN(ColumnB) [MinColumnB], MAX(ColumnB) [MaxColumnB], … MIN(ColumnZ) [MinColumnZ], MAX(ColumnZ) [MaxColumnZ] INTO [tmp] FROM ['YourTable']
- Because the results are in a single row, we separate them column by column and load them into the temporary table #Info with a dynamic query that looks like this:
INSERT #Info (Column, SystemType, UserType, Min, Max) SELECT 'ColumnA', system_type_id, user_type_id, MinColumnA, MaxColumnA FROM [tmp] UNION ALL SELECT 'ColumnB', system_type_id, user_type_id, MinColumnB, MaxColumnB FROM [tmp] UNION ALL … UNION ALL SELECT 'ColumnZ', system_type_id, user_type_id, MinColumnZ, MaxColumnZ FROM [tmp]
4 – Delete columns with null values (lines 33 to 37)
- If there are several columns with null values, we can save on CPU and memory by excluding them from further analysis.
5 – Get standard deviation, statistical variance, and mean (lines 38 to 57)
- We use only the columns that are not null, and only the ones with numerical data types, that’s why we didn’t include these functions in the section where it calculates min and max values. We calculate this for all columns in parallel and load the results into a new table named [tmp2] with a dynamic query that looks like this:
SELECT STDEV(ColumnA) [StdColumnA], VAR(ColumnA) [VarColumnA], AVG(ColumnA) [AvgColumnA], STDEV(ColumnB) [StdColumnB], VAR(ColumnB) [VarColumnB], AVG(ColumnB) [AvgColumnB], … STDEV(ColumnZ) [StdColumnZ], VAR(ColumnZ) [VarColumnZ], AVG(ColumnZ) [AvgColumnZ] INTO [tmp2] FROM ['YourTable']
- Because the results are in a single row, we separate them column by column and load them into the temporary table #Info2 with a dynamic query that looks like this:
INSERT #Info2 SELECT 'ColumnA', StdColumnA, VarColumnA, AvgColumnA FROM [tmp2] UNION ALL SELECT 'ColumnB', StdColumnB, VarColumnB, AvgColumnB FROM [tmp2] UNION ALL … UNION ALL SELECT 'ColumnZ', StdColumnZ, VarColumnZ, AvgColumnZ FROM [tmp2]
- And finally, we update #Info with these values.
6 – Mode and missing rows (lines 58 to 83)
- Again, we use only the columns that are not null, but this time we need to use a subquery to calculate the values for each column; however, we’re still able to calculate this for all columns in parallel and load the results into a new table named [tmp3] with a dynamic query that looks like this:
SELECT
(SELECT TOP 1 CAST([ColumnA] AS VARCHAR(MAX))+' ('+CAST([cn] AS VARCHAR(MAX))+')' FROM (
SELECT [ColumnA], COUNT(1) [cn]
FROM [YourTable]
WHERE [ColumnA] IS NOT NULL
GROUP BY [ColumnA]) [a]
ORDER BY [cn] DESC) [ModeColumnA],
(SELECT COUNT(1)
FROM [YourTable]
WHERE [ColumnA] IS NULL) [NAColumnA],
(SELECT TOP 1 CAST([ColumnB] AS VARCHAR(MAX))+' ('+CAST([cn] AS VARCHAR(MAX))+')' FROM (
SELECT [ColumnB], COUNT(1) [cn]
FROM [YourTable]
WHERE [ColumnB] IS NOT NULL
GROUP BY [ColumnB]) [a]
ORDER BY [cn] DESC) [ModeColumnB],
(SELECT COUNT(1)
FROM [YourTable]
WHERE [ColumnB] IS NULL) [NAColumnB],
…
(SELECT TOP 1 CAST([ColumnZ] AS VARCHAR(MAX))+' ('+CAST([cn] AS VARCHAR(MAX))+')' FROM (
SELECT [ColumnZ], COUNT(1) [cn]
FROM [YourTable]
WHERE [ColumnZ] IS NOT NULL
GROUP BY [ColumnZ]) [a]
ORDER BY [cn] DESC) [ModeColumnZ],
(SELECT COUNT(1)
FROM [YourTable]
WHERE [ColumnZ] IS NULL) [NAColumnZ]
INTO [tmp3]
- Because the results are in a single row, we separate them column by column and load them into the temporary table #Info3 with a dynamic query that looks like this:
INSERT #Info3 SELECT 'ColumnA', ModeColumnA, NAColumnA FROM [tmp3] UNION ALL SELECT 'ColumnB', ModeColumnB, NAColumnB FROM [tmp3] UNION ALL … UNION ALL SELECT 'ColumnZ', ModeColumnZ, NAColumnZ FROM [tmp3]
- And finally, we update #Info with these values.
7 -Distinct rows (lines 84 to 101)
- One more time, we use only the columns that are not null. We didn’t include this in the previous section (mode and missing rows) because these are not subqueries that we calculate on all table rows (note how we included the table name). We calculate this for all columns in parallel and load the results into a new table named [tmp4] with a dynamic query that looks like this:
SELECT COUNT(DISTINCT ColumnA) [DisColumnA], COUNT(DISTINCT ColumnB) [DisColumnB], … COUNT(DISTINCT ColumnZ) [DisColumnZ] INTO [tmp4] FROM ['YourTable']
- Because the results are in a single row, we separate them column by column and load them into the temporary table #Info4 with a dynamic query that looks like this:
INSERT #Info4 SELECT 'ColumnA', DisColumnA FROM [tmp4] UNION ALL SELECT 'ColumnB', DisColumnB FROM [tmp4] UNION ALL … UNION ALL SELECT 'ColumnZ', DisColumnZ FROM [tmp4]
- And finally, we update #Info with these values.
8 – Return results and delete tables (lines 102 to 113)
- We join the #Info table with [sys].[types] to get the data type of each column, return the exploratory results, and then delete the temporary tables used.
Results
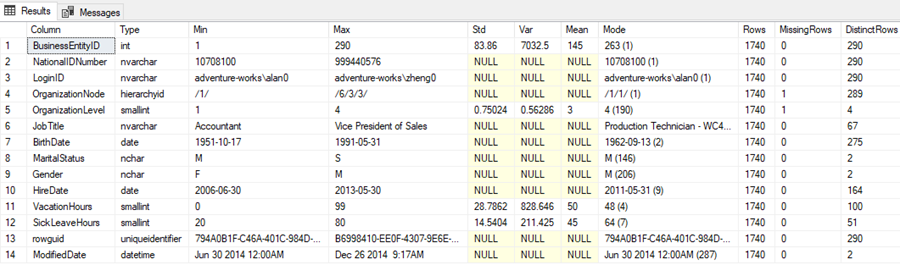
After running the script, here are the results obtained from the Adventures2014.HumanResources.Employee table:
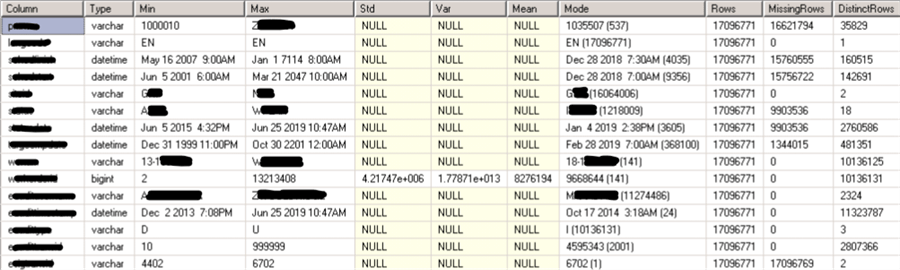
Here is another example of one of my tables that has over 17 million rows in the table.
From the results of my table, we can get the following insights:
- From the 241 columns, only 15 contain useful data, so we can reduce a lot those 20 GB of data when performing the machine learning process.
- There are two columns using a varchar data type but are numeric; we will have to perform a transformation on them after loading into the machine learning process.
- There is a column using a bigint data type but fits perfectly into an int; using a smaller data type will reduce the time to train a machine learning algorithm.
- There are five datetime columns that may need to be split on their components, but very interesting is the fact that the max values contain dates in the future as far as year 7114, so probably three of these columns will need to be excluded since the data is not reliable.
- There is a column with only 1 possible value, so it can be safely excluded.
- There are six columns where more than 50% of the rows have missing values, so those will probably need to be excluded.
- There is one column where 7.8% of the rows have missing values, we will have to replace those with the mean, median, mode, a custom value, a random value between a range, or using any of the algorithms (MICE, PCA, etc.). However, the mode is used only in 2.1% of the rows, so better not to use it as this will create class imbalance.
- There are three columns with more than 50% unique values, so those need to be evaluated if are correlatives and thus won’t give any insight to the analysis.
For the large table, it was run on a computer with 8 CPUs and 95 GB of RAM, and the query statistics tell us the following:
- It took 59 seconds to calculate min and max. For 17 million rows, this is 287 rows per millisecond. For 20 GB, this is 347 MB per second. This was possible thanks to parallelism.
- It took 2.4 seconds to calculate stdev, var and avg, mainly because there was only one numeric column.
- It took 102 seconds to calculate median and missing values, so the statistics are similar as for the first part of the query, thanks to parallelism.
- It took 56 seconds to calculate the count distinct values, so the statistics are similar as for the first part of the query, thanks to parallelism.
- In total it took 3 minutes and 56 seconds to run the script, which is a lot faster than loading the data into a machine learning tool and analyzing it there.
Next Steps
- Please give it a try and let us know your comments.
- Here is the link related to parallelism.
- Here is the official documentation about exploratory data analysis.

Pablo Echeverria has worked for more than 10 years as a software programmer and analyst, during which time I studied parallel programming and became a senior programmer specialist. Afterward, he switched to a DBA position implementing new processes and creating better monitoring tools, while growing his data scientist skills to improve my customer’s businesses. Check out Pablo’s most recent book, “Hands-on Data Virtualization with Polybase“. This book brings exciting coverage on establishing and managing data virtualization using Polybase. It teaches how to configure Polybase on almost all relational and nonrelational databases, to setup a test environment for any tool or software instantly without any hassle, and to rapidly design and build high performing data warehousing solutions.
- MSSQLTips Awards: Rising Star (50+ tips) – 2024 | Author Contender – 2018, 2022, 2023 | Rookie Contender – 2017


Note if you get error 8115 “Arithmetic overflow” this is due to small integer datatypes, in this case change the line calculating “stdev, var and avg” as follows:
SELECT @cmd = @cmd + ‘STDEV(‘+[Column]+’) [Std’+[Column]+’],VAR(‘+[Column]+’) [Var’+[Column]+’],AVG(‘+(CASE WHEN [UserType] IN (48, 52, 56) THEN ‘CAST(‘ ELSE ” END)+[Column]+(CASE WHEN [UserType] IN (48, 52, 56) THEN ‘ AS BIGINT)’ ELSE ” END)+’) [Avg’+[Column]+’],’