Problem
A webinar about SQL Server Development best practices was hosted on MSSQLTips.com. In this webcast, several tips and tricks were shared which could save a lot of time and headaches when writing T-SQL code. At the end, there was room for questions, but since not every question could be answered in the allotted time frame, we will tackle them in this tip. Some questions are already answered in part 1.
Solution
Get your webcast questions and answers addressed in this tip.
Q: What is the best SQL Server data type for storing money?
Although there is a (small) money data type, I think the numeric/decimal data type is better suited for storing currency values. The main reason is the possibility for rounding errors. Let’s take a look at a small example:
DECLARE @Denominator MONEY = $301.00 DECLARE @Numerator MONEY = $189.50 SELECT Percentage =(@Numerator / @Denominator) * 100
SQL Server returns the following:
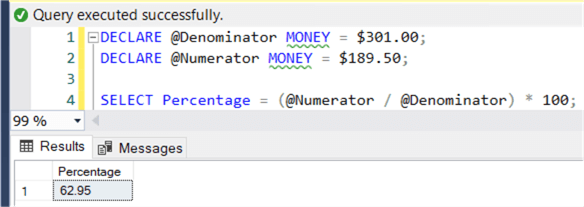
When we perform the same calculation in Excel, we get a slightly different result:

The main reason behind this is that the money data type is basically an integer data type (big int for money, int for smallmoney), which means it has limited precision, leading to the rounding errors. The numeric data type doesn’t have this issue. You can find more info in the article Avoid use of the MONEY and SMALLMONEY datatypes.
One notable exception might be when you’re using Analysis Services Multidimensional (SSAS MD) as your OLAP solution. When SQL Server is the source for SSAS MD, it might be an option to use the money data type instead of numeric or floats if you can live with the fixed precision. The reason is because SSAS MD doesn’t really handle numeric/floats really well. Because money is basically an integer data type, SSAS MD processing will be faster when money is used. A pattern might be to store the data as numeric in the tables, but convert them in a view to the money data type. SSAS MD will then read the view when processing. An example is given in the SQLBits session Optimising Cube Processing by Bob Duffy.
Q: Do you know any good resources to learn more about SQL Server database administration?
MSSQLTips.com obviously has a wealth of information: tutorials, articles and many webcasts. There’s a whole section on database administration alone. Another good resource is the book Troubleshooting SQL Server: A Guide for the Accidental DBA or the Accidental DBA series at SQLSkills.com. I learned about database administration by pursuing the Microsoft SQL Server certificates. They have changed a lot in the last years, but the MCSA – Database Administration certification should give you a good overview of how to manage SQL Server. Even if you’re not interested in taking the exam, the preparation materials are excellent material to get you started in the world of SQL Server.
Q: Why does column order matter for a SQL Server index?
In a SQL Server index, the data is sorted according to the columns specified in the index. Meaning, if the index specification states (column A ascending, column B descending), it means the data is first sorted by column A ascending. For the same values of A, the data is then sorted by column B descending. Since the data is first sorted by column A, you cannot easily find a specific value for column B without knowing the value of A. If you don’t know the value for A, you have to scan the entire index to find all the value of B you’re looking for.
Telephone Book Example
Let’s illustrate with an example. In a classic telephone book, the telephone numbers (the records of the table) are first sorted by city, then by family name and finally by street address (at least, that’s how it was done in Belgium). So let’s suppose we’re looking for the telephone number of the family Anderson in the city of Denver. First you look for Denver, then for Anderson. If there are a lot of Andersons in the city, you’d have to know the street address to find the correct telephone number.
Now suppose you’d want to find the telephone number of the Anderson family, but you don’t know which city they live in (you do know the street address though). This would mean you’d have skip to each city in the telephone book, then look for Anderson and check the street address. It’s easy to see this is a lot more work and the same is true for indexes in a database.
AdventureWorks Sample
We can demonstrate the behavior in the AdventureWorks sample database. The table Sales.SalesOrderDetail has the following primary key defined:

First SalesOrderID, then SalesOrderDetailID. When filtering on a specific SalesOrderID, we can see the index is being searched:
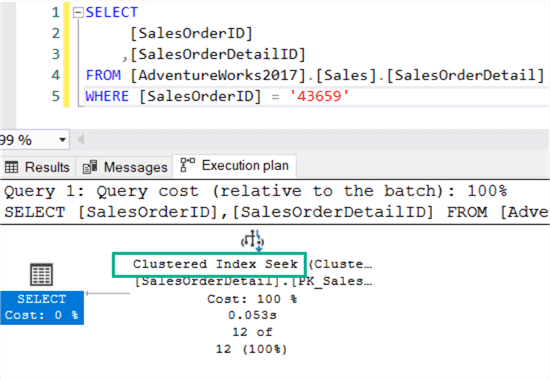
The same is true when filtering on a SalesOrderID and a SalesOrderDetailID:

However, when filtering on SalesOrderDetailID, the seek turns into a scan:

More data is being scanned, which means the query might be slower. If you’re wondering why in the first two queries the clustered index was used (which is the index implementing the primary key constraint) and in the last query a non-clustered index: because SQL Server knew it had to scan all the data, it’s a better idea to scan a smaller non-clustered index instead of the wider clustered index, minimizing the number of bytes that have to be read.
Next Steps
- There are many other webcasts available, on a variety of topics. You can find an overview here.
- Be sure to check out part 1 of this tip series, where other questions were covered.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025