By: Aaron Bertrand | Comments (3) | Related: > Functions User Defined UDF
Problem
I’ve written here about two known limitations of the STRING_SPLIT function, added in SQL Server 2016.
The first issue is that the output order is not guaranteed to match the input order (so a string bob,mack,foo may get split apart and come out of the function in the order mack, foo, bob); I suggested some ways to work around that in Solve old problems with SQL Server’s new STRING_AGG and STRING_SPLIT functions.
The second is that the separator you split by is limited to a single character; I addressed this in Dealing with the single-character delimiter in SQL Server's STRING_SPLIT function.
A third limitation that I recently discovered is that not all single characters are valid input to the separator argument of the function. This can be important to know if you are struggling to find a delimiter that can’t possibly exist inside the source data you’re concatenating and splitting.
Solution
Before we talk about any kind of workaround, let’s start with how I got here, since I stumbled upon this issue accidentally. I was actually reworking a split function I wrote, long before STRING_SPLIT existed, so that it could now handle a space as the separator. So I re-wrote the function as follows, changing LEN() to DATALENGTH()/2 so that the “trailing” space would be ignored:
CREATE FUNCTION dbo.SplitString
(
@List nvarchar(max),
@Delim nvarchar(255)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH n(n) AS (SELECT 1 UNION ALL SELECT n+1
FROM n WHERE n <= LEN(@List)
)
SELECT [Value] = SUBSTRING(@List, n, CHARINDEX(@Delim, @List + @Delim, n) - n)
FROM n
WHERE n <= LEN(@List)
AND SUBSTRING(@Delim + @List, n, DATALENGTH(@Delim)/2) = @Delim
);
I tested the function, to make sure spaces now work, and that all the other characters I had tested before continue to work:
SELECT [value] FROM dbo.SplitString(N'mack,foo,bob', N','); SELECT [value] FROM dbo.SplitString(N'mack|foo|bob', N'|'); SELECT [value] FROM dbo.SplitString(N'mack~foo~bob', N'~'); SELECT [value] FROM dbo.SplitString(N'mack foo bob', N' ');
These all worked correctly, as I suspected. Then I thought, let’s try some crazy characters from the upper bounds of the character set, to make sure that other delimiters would also be supported (screenshot because I know a web page won’t support all of these characters):
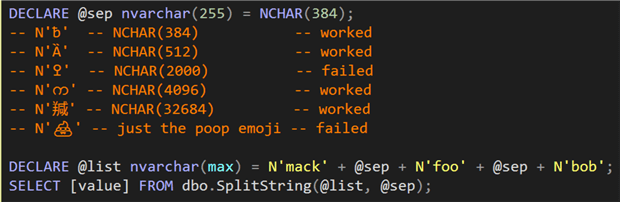
As indicated in the comments, some worked, but some failed. When they failed, it was always with the following error message:
Msg 537, Level 16, State 3
Invalid length parameter passed to the LEFT or SUBSTRING function.
So I tried reverse engineering the function, and determined that even though these troublesome characters had the same datalength and similar varbinary conversion to those that worked, they were failing to get parsed correctly by CHARINDEX (the function would return the wrong location within the string). I thought, that is interesting, and immediately wondered two things: (1) how could I compile a list of all the troublesome characters, and (2) does the same problem affect the built-in function, STRING_SPLIT?
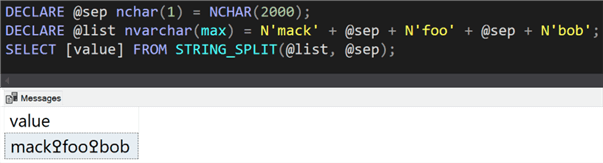
I quickly assembled a test to tackle both simultaneously. First, I checked the behavior of STRING_SPLIT with one of the troublesome characters (again, using a screenshot to avoid translation issues):
The real test would be checking all of the characters (well, from NCHAR(0) through NCHAR(65536), anyway):
SET NOCOUNT ON; CREATE TABLE #stuff
(
i int PRIMARY KEY,
c nchar(1),
result int,
details nvarchar(2048)
); DECLARE @sep nchar(1), @list nvarchar(max), @i int = 0; WHILE @i <= 65536
BEGIN SET @sep = NCHAR(@i); SET @list = N'mack' + @sep + N'foo' + @sep + N'bob'; BEGIN TRY INSERT #stuff(i,c,result) SELECT @i, NCHAR(@i),
CASE (SELECT COUNT(*) FROM STRING_SPLIT(@list,@sep))
WHEN 3 THEN 1 -- success! 3 is expected
WHEN 1 THEN 0 -- failure! 1 means the string was not split
ELSE -1 -- neither 3 nor 1! Something else happened
END; END TRY BEGIN CATCH INSERT #stuff(i,c,result,details) SELECT @i, NCHAR(@i),
-2, -- a real exception, so let's find out why:
ERROR_MESSAGE(); END CATCH SET @i += 1; END
First thing I wanted to inspect: how many characters worked?
SELECT result, breakdown = COUNT(*)
FROM #stuff
GROUP BY result
ORDER BY result DESC;
Results:
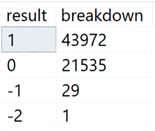
The good news? 43,927 characters worked! The bad news? 21,535 characters did not work. (Note that your result may differ if you are not using the default instance collation from SQL Server setup.) In addition, 29 had some other issue and 1 caused an error in the script.
Let’s look at the outright failure first:
SELECT i, c, result, details FROM #stuff WHERE result = -2;
Results:

I’m okay with this. I was pushing the upper bound anyway, and should have realized that NCHAR(65536) would yield NULL.
Next up, the ones that didn’t yield the correct count or a single value:
SELECT i, c FROM #stuff WHERE result = -1;
Results:
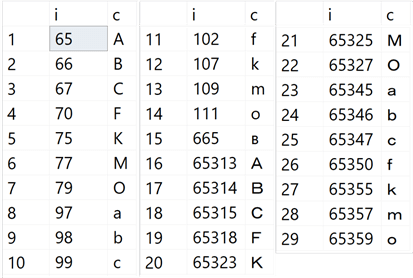
Of course, these are the regular alphanumeric characters (or their codepage equivalents in some way) that appear in the data, so of course if you’re splitting on a separator that is also in the data, you’re going to end up with more segments than you would have expected.
And finally, the ones that didn’t split at all (WHERE result = 0), were a whole mix of things. NCHAR(0) was no surprise, same with all the characters that yield empty boxes or question marks. But there are others I can’t explain, like NCHAR(173) (-), NCHAR(706) (), and NCHAR(1421) (which is some kind of pinwheel character). Ranges that are safe to use: 506 – 535, 1377 – 1414, and 63744 - 64045.
I talked to some other folks about this, and Erland suggested trying a different (newer) collation, since more code points are defined there. So I changed the code to the following:
SET NOCOUNT ON; CREATE TABLE #stuff2
(
i int PRIMARY KEY,
c nchar(1),
result int,
details nvarchar(2048)
); DECLARE @sep nchar(1), @list nvarchar(max), @i int = 0; WHILE @i <= 65535
BEGIN SET @sep = NCHAR(@i); SET @list = N'mack' + @sep + N'foo' + @sep + N'bob'; BEGIN TRY INSERT #stuff2(i,c,result) SELECT @i, NCHAR(@i),
CASE (SELECT COUNT(*) FROM STRING_SPLIT(@list COLLATE Latin1_General_100_CI_AI,@sep))
WHEN 3 THEN 1 -- success! 3 is expected
WHEN 1 THEN 0 -- failure! 1 means the string was not split
ELSE -1 -- neither 3 nor 1! Something else happened
END; END TRY BEGIN CATCH INSERT #stuff2(i,c,result,details) SELECT @i, NCHAR(@i),
-2, -- a real exception, so let's find out why:
ERROR_MESSAGE(); END CATCH SET @i += 1; END
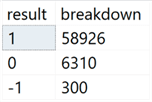
This was better, but not perfect. We still have over 6,300 characters that can’t be reliably used as a separator to split at all, and 300 characters that now yield more than 3 results in their output:
Summary
The short version of this cautionary tale: don’t pick random separators; do your research, and make sure you pick a separator that will both behave as you expect and cannot possibly appear in the data. This holds true whether you are using the built-in STRING_SPLIT (with or without COLLATE) or, as I have also demonstrated, a custom T-SQL split function. And this isn’t a solution, of course; it’s just my way of dealing with the problem – identifying characters that can or can’t be used as delimiters – without obtaining a PhD in Unicode, collations, and code pages to help me understand why.
Next Steps
Read on for related tips and other resources:
- Dealing with the single-character delimiter in SQL Server's STRING_SPLIT function
- Solve old problems with SQL Server’s new STRING_AGG and STRING_SPLIT functions
- SQL Server 2016 STRING_SPLIT Function
- Identify SQL Server Instance and Database Collation Using T-SQL and SSMS
- How column COLLATION can affect SQL Server query performance
- How to change server level collation for a SQL Server Instance
- Comparing string splitting / concatenation methods






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
