Problem
There are certain business workloads that might need a SQL Server database for a limited period of time. After data processing, the need for having the database online declines.
One use case that comes to mind is the payment of vendors for raw goods. A medium size manufacturing company might receive multiple shipments from a vendor during the month. However, calculating the total bill for a given period and making one payment to the vendor might happen twice a month.
How can we create an Azure SQL database that keeps in mind cost for an intermittent relational database need?
Solution
Microsoft has a new virtual core offering of Azure SQL database called serverless. This offering optimizes the price-performance tradeoff and simplifies performance management for databases with intermittent and unpredictable usage. Since this offering allows for auto-scaling, workloads with CPU usage that peaks and valleys can benefit for this offering.
Business Problem
Our boss has asked us to look into the new virtual core offerings of Azure SQL database. Since we have a couple internal workloads that have intermittent usage patterns, we are going to start our investigation with the serverless offering.
We need to choose a simple problem that can be solved on our local laptop and in the cloud. This will give a performance comparison of the new offering. This proof of concept will use the math database schema which calculates prime numbers from 1 to N. In our case, we want to know how many primes numbers exist between 1 and 5 million. We want to execute 20 asynchronous jobs to accomplish this task as fast as possible.
The rest of the article will show you how to deploy an Azure SQL database (serverless edition) using the math database schema. Comparing cloud to on premise execution times allows us to gauge how fast the Azure virtualized environment is.
Deploy Server and Database
The deployment of the server and database is almost the same as the database transaction unit (DTU) version that we are accustomed to. I will point out the differences and highlight any key points in the screen shot images shown below.
First, we need to deploy an Azure SQL database using the Azure portal. I will be using a subscription that I only have full rights to a resource group named jfm_x_001. Clicking the add button when viewing the resource group will allow me to search the Azure Market place for the database service.

The above image shows that a new database server named svr4tips2019 will be deployed in the East US region. I might want to have other Azure services such as Azure Data Factory work with this data. Click the appropriate check box to make this happen.
Second, we need to choose the settings of the db4tips2019 database. By default, Microsoft wants all customers to start using the new v-Core offerings. Click on the configure database to see the full set of available options.

The original offerings of Azure SQL database using the Basic, Standard and Premium tier can be found by clicking the topmost left button. The image below shows the screen that most Data Architects have seen for the last 5 years. To see the new offerings, click v-Core purchasing topmost right button.
What is the main different between the offerings?
The historical offerings are a shared architecture in which you are not provisioned any dedicated CPU and memory. The new offerings allow for the selection of the number of CPUs. Memory is allocated as a multiplier of the cores depending upon the generation of the central processing unit (CPU). I will go into more details in my next article on the General Purpose offering of Azure SQL database.

There are three new offerings under the v-Core based purchasing model. For our proof of concept, we want to choose the General purpose offering and the serverless compute tier.

We will be using four cores to match the processing power on my laptop. Please notice that the image below shows the ability to choose the min and max values for cores used by service. This is where scaling comes into play.
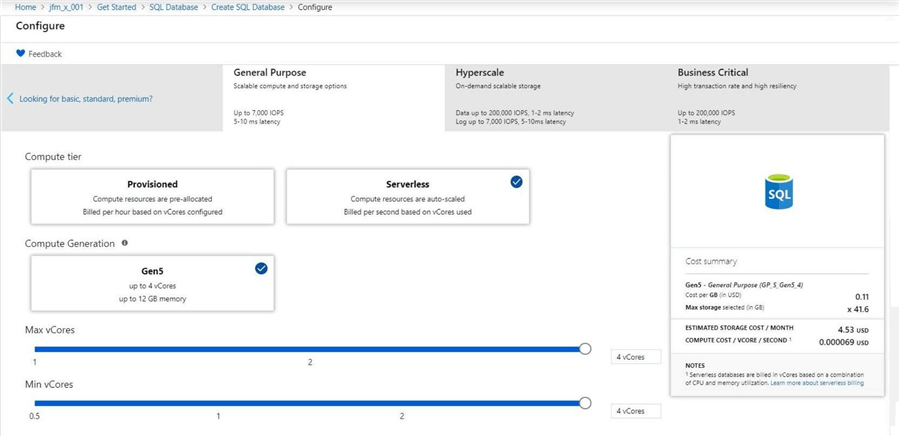
Like all v-Core offerings, the amount of memory is dictated by the number of cores and the size of the log file is dictated by the data file size. One key observation is that the service can be paused after a given amount of time.

It is import to note that the above image shows this service is in preview. When the images were taken for the article about 6 months ago, this was true. Today, the service has general availability. Also, the limitations of 4 cores and 1 TB of file space has been increased to a maximum of 16 cores, 48 GB of memory and 3 TB of file space.

Most deployments from the portal have a review and create pane. This allows the user to go back to various options if they are incorrect. Click the create button to deploy the serverless database.
I do like the new deployment details pane. It shows what is being deployed and the status of the deployment. From the image below, we can see a server, database and firewalls were deployed. What is interesting is the storage account which was deployed to support vulnerability assessments and alert policies. For some reason, it is listed three times in our deployment log.
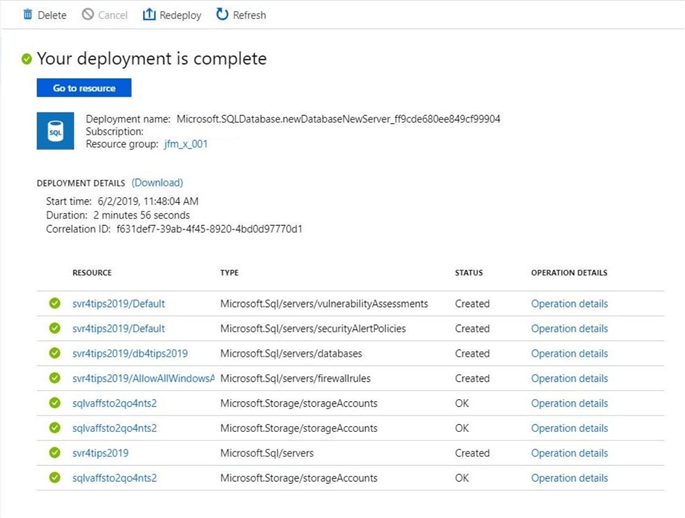
At the end of the day, we are just interested in the components that were deployed. We have listed below an Azure logical SQL Server named svr4tips2019 and an Azure Serverless database named db4tips2019.

In a nutshell, deploying the new serverless offering requires a few more choices from the user to complete than the older offerings.
Math database schema
One of the nice things about Azure SQL database is that it is secured during deployment. That means we have to enable the firewall to allow our database tool of choice to connect. Please see image below for details.

I am still using SQL Server Management Studio (SSMS) for DBA tasks. You might be using either Visual Studio database projects, Azure Data Studio, or a third-party product. The image below shows a typical login using the account I created during deployment of the logical server.

The enclosed T-SQL script named “make-prime-number-database.sql” will create the math database schema. Inside the script is a statement that displays the objects that were created. Your results should match the image below.

The code below is extracted from a T-SQL file named “calculate-prime-numbers.sql“. It will find and store primes numbers with a range of a given N to N + 250000 – 1.
-- Local table variable
DECLARE @MY_TABLE TABLE ( [MY_ID_VALUE] [int] );
-- Create a new control card record
INSERT INTO [DBO].[TBL_CONTROL_CARD]
OUTPUT INSERTED.MY_ID_VALUE
INTO @MY_TABLE
VALUES ('Look for prime numbers.', default);
-- Find start/end points
DECLARE @VAR_ALPHA, @VAR_OMEGA BIGINT;
SELECT @VAR_ALPHA = MY_ID_VALUE - 250000 FROM @MY_TABLE;
SELECT @VAR_OMEGA = MY_ID_VALUE - 1 FROM @MY_TABLE;
-- Find prime numbers based on control card record
EXEC [DBO].[SP_STORE_PRIMES] @VAR_ALPHA, @VAR_OMEGA;
To finish our proof of concept, we need a way to call this T-SQL script 20 times in a asynchronous manor. We can use a plain batch file named “run.cmd” to accomplish this task. The code inside the batch file is shown below.
-- Change directory
CD "C:\Azure SQL Database\"
-- Execute file via sqlcmd
FOR /L %%A IN (1,1,20) DO (
start cmd /c sqlcmd -S tcp:svr4tips2019.database.windows.net^
-U jminer -P InsertPasswordHere -d db4tips2019 -i "calculate-prime-numbers.sql"
Execute the batch command to search for prime numbers now.
Remote Database Results
Many of the components of the SQL Server stack have been split into separate install programs. If you have an older version of SQL Server Management Studio, you might see the following error message.

This means the software does not recognize the new v-Core offerings for Azure SQL database. Please download and install the latest version of the software to eliminate this issue.
The rows in the table named TBL_CONTROL_CARD keep track of all the separate executions. We can see that 20 threads (command windows) were executed from the batch file within 3 seconds. See image below for details.

Our prime numbers are stored in a table called TBL_PRIMES and a summary query is seen below.

Each record has a time of discover. If we aggregate the data, we can calculate the start time, the end time, the total elapsed time and the total number of prime numbers found. Looking at the results from the above image, we can see that the execution took 6 minutes and 12 seconds to complete.

Billing for an Azure Serverless Database is a combination of storage and compute. It is important that the auto pause feature be set to a low value if possible, for best savings.
In the above image, we can see that 13.56K v-Core seconds have been used. The subscription only gets charged when processing occurs. Once the CPU is paused, only the storage cost is charged. Using the cost numbers from the deployment window (see 5th image) times the number of v-Core seconds, we can see a charge of 94 cents was incurred during this hour. Let us turn our attention now to a similar test using on premise hardware.
Local Database Results
If no one let you in on the secret, hardware is the king when it comes to speed. Many of the Azure offerings are using remote storage. These offerings can’t compete with the raw power of unabstracted solid-state disks.

The above image shows a similar execution of the command windows for 20 jobs.

There are some major differences in the results. At least we have found the same number of PRIME numbers in both executions. This result shows that our algorithm is executing the calculations correctly.
However, we can start 20 command windows in 2 seconds using an on-premise local server. It takes an additional 1 second when we use an Azure remote server. This is due to the network delay between the source and target. The total execution time is now 3 minutes and 55 seconds. That is a savings of 2 minutes and 17 seconds. The local server is 45.14% faster in executing the same code.

The above image shows the configuration of my laptop that was used in the bake off. Both the local and remote databases have 4 processors that are hyper threaded. The laptop has 16 GB of memory for all processes including the operating system. The Azure Serverless database is capped at 12 GB of memory. The major difference between the two systems is the speed of the attached disk versus the remote disk.
My laptop is 2 years old using a Samsung SSD 850 EVO local SSD. The chart below was copied from a white paper authored by Calypso Systems CEO, Eden Kim and published by SNIA SSSI. I did a quick disk speed check using the tech net utility named diskspd.exe. The laptop clocked in at 60K IOPS for the read test. I am sure the write test will be around 40K IOPS. Attached storage in Azure has performance that range from 120 to 5000 IOPS for premium SSD for given the database size.
To recap, attached storage in Azure has lower IOPS than a typical SSD that might be found in your computer. The fastest storage is one that is directly attached to the motherboard. We can see that the PCIe disks have impressive speeds.

One last observation to mention is the new Azure v-Core database have three files. Typically, we see a log and data file per each database. Something extra is going on here to support the implementation of the General Purpose, serverless tier database.

The bake off between in-cloud and on-premise is now complete. If you do not mind managing your own hardware and software, then a bare metal install of the database engine will give the best performance. If you have a database with intermittent and unpredictable usage, an Azure Serverless database might meet your needs at a reasonable price.
Summary
There are many business cases in which a relational database needs to be available intermittently. If your application can handle a slow startup of the server from a paused condition, then the Serverless offering might be a fit. This will save you money since no compute charges will be incurred during inactivity. Please review the Azure Serverless documentation closely. Certain features such as geo-replication cancel out the ability to pause the server.
Other applications might experience a peak in usage during a busy time of year. For instance, an online pizza delivery business might see a major uptick in business during Super Bowl weekend. If you are using Azure Serverless database, the load balancer will scale the number of CPUs to handle the unexpected load. Just remember, there will be a momentary drop of connections when resources are added or subtracted. This means your application must be able to handle retries for a downed database service.
Both auto scaling and auto pausing are nice features of the Azure Serverless database offering.
I believe that Azure SQL database is cost effective for small to medium size work loads that do not need to low latency and high performance. For large work loads, there are other offerings to consider. I will be talking about the Business Critical offering of Azure SQL database in the future. It has attractive performance at an unattractive price. Unfortunately, you will pay a lot of money for a database service that is capped at a storage size of 4 TB.
If you really need extreme performance and have a team to manage both the infrastructure and the database, some amazing numbers can be seen with today’s hardware in a hosted data center.
In summary, I spend most of my time deploying and managing Azure SQL databases because they are cost effective for over 90% of the use cases that I see. For the other 10%, consider the other alternatives. This includes using memory like Apache Spark or distributing data like No SQL. Next time, I will be talking about the General purpose version of Azure SQL database.
Next Steps
- General purpose version of Azure SQL Database
- Business critical version of Azure SQL Database
- Going hyperscale with Azure SQL Database
- Why choose Managed Instance over other SQL offerings?

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023


Hi Dan, that is a good question. Databases have been around since Codd created the relational calculus model in 1970s. While the cloud is new compared to databases, there are some pieces that are still required for creating a database. The server used to be physical hardware that contained one or more databases. Since thousands of Azure SQL databases exist in the cloud, there still has to be a logical container (server) that holds all your databases vs someone else’s. This container has the web URL entry point into your logical server and Azure SQL databases. As for cost, you always have to pay for storage. Use the Azure Pricing Calculator for estimates. But with serverless, you pay for compute when you use the database. Just remember that waking up a database takes some time. Therefore, code appropriately for the application that uses the serverless database. Sincerely John
How come, when you choose serverless, you have to also create a server? How can it be serverless if I have to select or create a server, and if so, then surely that also comes at a cost, but is that cost in addition to the vcore per second + storage cost we have to pay?