Problem
This is the fifth article in the series about differences in the three Relational Database Management Systems (RDBMS). This time we will focus on the differences in terminology between Microsoft SQL Server, Oracle and PostgreSQL and the different possibilities in working with Instances, Databases, Schemas, Linked Servers, etc.
Solution
As any DBA who has had to work with different RDBMS knows there are big differences in terminology about databases and what can be done for querying data coming from different instances as well as the different syntax in the SQL programming language. In this tip we will analyze the different terminology and try to clarify what are the main differences between the three RDBMS regarding database concepts.
Databases and Schemas
First of all, we know that on an instance of Microsoft SQL Server we can have multiple databases and then inside each database multiple schemas. This is not true in Oracle and only partially true in PostgreSQL.
First of all, in Oracle you can have only one database per instance, unless you are working with PDBs that’s to say Pluggable Databases (more on that later). So, what we commonly use to differentiate inside the same database are schemas, but in Oracle they are basically Users! Let me clarify a little bit, as per Oracle documentation: “A schema is a collection of logical structures of data, or schema objects. A schema is owned by a database user and has the same name as that user. Each user owns a single schema.”
So, in practice the concepts of user and schema in Oracle overlap, let’s look at an example using the github freely downloadable open source database sample Chinook, as it is available in multiple RDBMS formats. It is a simulation of a digital media store, with some sample data, all you have to do is download the version you need and you have all the scripts for the data structure and all the inserts for data. I am using for SQL Server, Microsoft SSMS 18.8; for Oracle, Oracle SQL Developer Version 20.2 and for PostgreSQL, Pgadmin 4 Version 5.0. All these tools are freely downloadable, there are links at the end of the tip.
In SQL Server we can see that we have a database named Chinook with all the objects under it, like tables, views, stored procedures etc.:

In Oracle the same structure is used for Schema/User:

But inside of the Schema/User we have all the objects that we normally find under a SQL Server database and some more:

So, in practice the concept of database in SQL Server is very similar to that of Schema/User in Oracle, with the notable differences that it is still a User, there is a Password for this user:
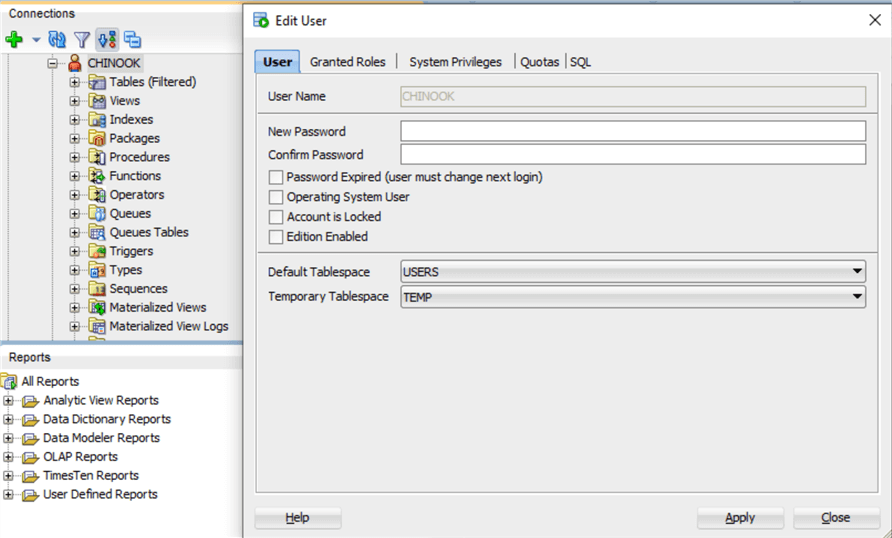
You can authenticate and connect to the database with this user, provided you have the connect Role assigned, you also have to assign a default and a temporary Tablespace for this Schema/User and you can grant privileges and Roles to it. The default tablespace will be the one in which all the tables and indexes will be physically stored on the disk by default: for example, when you will create a table by default it will be created in this tablespace unless you specify another.
As written in the documentation, the user owns all the objects in the schema, it is referred in system views as the Owner, so by default it has all privileges on tables, indexes, views, procedures, etc.
Let’s make an example and see all tables owned by Chinook and privileges on tables associated with user Chinook, then we will connect to the database using this same user. To begin we will issue a Structured Query Language (SQL) query the system view DBA_ALL_TABLES. Note that to query it you must have DBA privileges, thus I am connected to the database with such a user:
SELECT OWNER, TABLE_NAME, tablespace_name FROM dba_all_tables WHERE OWNER='CHINOOK';

The query returns all tables owned by CHINOOK. Then we check all the privileges explicitly granted on these tables using again the owner as filter and querying the DBA_TAB_PRIVS system view with this SQL statement:
select * from dba_tab_privs where OWNER='CHINOOK';

There are no results, so no privileges have been explicitly granted on the tables owned by CHINOOK.
Let’s try now to connect to the database using the CHINOOK user:

First of all, you notice that all the objects owned by this User/Schema are immediately displayed and they are not under the Other Users:

And obviously if we ran a query on one of the tables, we see that we are able to get all the data, because we have all privileges as user Chinook is the Owner of the schema Chinook. Even if there is no explicit grant and we do not have to specify the schema in querying it, as we are already connected with this Schema/User:
select * from genre;

PostgreSQL
Let’s see these same concepts in PostgreSQL, here we have a situation that has similarities to both SQL Server and Oracle. First of all, we can have multiple databases under the same Instance, but in PostgreSQL this is called a Cluster!
As per PostgreSQL documentation: “A small number of objects, like role, database, and tablespace names, are defined at the cluster level and stored in the pg_global tablespace. Inside the cluster are multiple databases, which are isolated from each other but can access cluster-level objects. Inside each database are multiple schemas, which contain objects like tables and functions. So, the full hierarchy is: cluster, database, schema, table (or some other kind of object, such as a function).”
So, checking our Cluster using PGAdmin 4 we see that we have 2 Databases, Chinook and the default postgres one:

And inside the Database we can have multiple Schemas, in this case of Chinook it is just one schema in which we have all the objects owned by that schema:

So, we see that in this case PostgreSQL is very similar to SQL Server, but there is one big difference between SQL Server and PostgreSQL and it is in queries between different databases.
Querying from Multiple Databases
SQL Server
In the SQL Server DBMS if you want to execute a query between one database and another under the same instance it’s extremely easy you just need to specify the database.schema.table, separated by periods for the different tables. For this example, I have used the script for creating the Chinook SQL database and renamed it, creating a new database named Apache and added and deleted some rows in the table we need in our example:

Now let’s do the cross-database query imagining that we need to check the customers that are present only in Apache:
USE Apache GO SELECT CustomerId, FirstName,LastName FROM dbo.Customer EXCEPT SELECT CustomerId, FirstName,LastName FROM Chinook.dbo.Customer

Easily done with a simple set-based query with EXCEPT.
PostgreSQL
Let’s try now to do the same thing in PostgreSQL, I’ve created the same Apache database, adding and deleting some rows from the Customer table exactly as I did in SQL Server:

Now let’s run the same query we’ve used on SQL Server, launching it from Apache database:
SELECT "CustomerId", "FirstName","LastName" FROM "Customer" EXCEPT SELECT "CustomerId", "FirstName","LastName" FROM "Chinook"."Customer"

Unfortunately, we have an error, because this notation doesn’t work in PostgreSQL, you could have already guessed from this part of the documentation that was written above: “Inside the cluster are multiple databases, which are isolated from each other but can access cluster-level objects.”. In order to query data from another database, even in the same Cluster, we need to use a Foreign Data Wrapper which is very similar to the concept of a Linked Server in SQL Server or a DB Link in Oracle.
Foreign Data Wrapper PostgreSQL
The first step we need to do is install the extension postgres_fdw in order to query another PostgreSQL:
CREATE EXTENSION postgres_fdw;

Then we need to create a Foreign Server to connect to, in this case it is the same host:
CREATE SERVER "Chinook db"
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '192.168.10.152', port '5432', dbname 'chinook');

Then we create a User Mapping in order to access this database using a user present in that host/database, in this case we use the same postgres user identified by password:
CREATE USER MAPPING FOR postgres SERVER "Chinook db"
OPTIONS ("user" 'postgres', password 'password');

Now that we have completed the Foreign Data Wrapper functionality to connect to the other database, we need one last step in order to query it: we need to create a Foreign Table. This is different from the other two RDBMS in which when we complete the DB Link or Linked Server, we can directly access the catalog and query all the tables granted with our user.
With the following code we create a Foreign Table called Customer_Fo under the schema public with numerous columns and various data types:
CREATE FOREIGN TABLE public."Customer_Fo"(
"CustomerId" integer NOT NULL,
"FirstName" character varying(40) COLLATE pg_catalog."default" NOT NULL,
"LastName" character varying(20) COLLATE pg_catalog."default" NOT NULL,
"Company" character varying(80) COLLATE pg_catalog."default",
"Address" character varying(70) COLLATE pg_catalog."default",
"City" character varying(40) COLLATE pg_catalog."default",
"State" character varying(40) COLLATE pg_catalog."default",
"Country" character varying(40) COLLATE pg_catalog."default",
"PostalCode" character varying(10) COLLATE pg_catalog."default",
"Phone" character varying(24) COLLATE pg_catalog."default",
"Fax" character varying(24) COLLATE pg_catalog."default",
"Email" character varying(60) COLLATE pg_catalog."default" NOT NULL,
"SupportRepId" integer
)
SERVER "Chinook db"
OPTIONS (schema_name 'public', table_name 'Customer');

Finally, we are able to run our SQL query across database tables:
SELECT "CustomerId", "FirstName","LastName" FROM "Customer" EXCEPT SELECT "CustomerId", "FirstName","LastName" FROM "Customer_Fo"

Obviously, it is a lot more simpler in PostgreSQL to create a new Schema instead of a new Database under the same cluster!
In a future tip we will explore more in depth the concepts of DBLink and Linked Servers not only in the same RDBMS, but we will see how to create links between different platforms such as from Oracle to SQL Server and vice versa and the same with PostgreSQL FDW.
Oracle Multitenant Container Database and Pluggable Databases
As mentioned before, in Oracle it is not possible to have more than one database under the same instance, unless we use the so-called Multitenant architecture introduced with Oracle 12c. In this case it is possible to create multiple PDBs under the same CDB (container). They can be easily separately, started and stopped. Like in PostgreSQL, if you’d like to execute a cross database query you need to create a DB Link pointing to the other database.
Moreover, PDBs can be plugged and unplugged from one container and also easily cloned, in fact I have used this architecture in all the Oracle examples that I have done so far as I created Chinook Database as a PDB under a container!
The Multitenant architecture must be specified when the Oracle Instance is installed and then creating, modifying, plugging/unplugging (or attaching/detaching if we use SQL Server terminology) and cloning PDB is quite easy.
Very important: starting from Oracle 21 this multitenant architecture will be the only one supported, so from this version of Oracle database it is possible to have by default multiple databases under the same instance.
Here is a very comprehensive explanation of the Multitenant architecture (better than the standard Oracle doc!).
I will follow up in a separate tip with practical examples on PDB/CDB as it is a very wide topic (architecture, scalability, etc.) on its own!
Next Steps
- In this tip we have seen the different terminologies and similarities between the Database concept in the three RDBMS. It is clear that what we know as a Database in SQL Server is much more similar and it is preferably done by the Schema concept in both Oracle and PostgreSQL.
- PostgreSQL Documentation on Databases
- PostgreSQL Documentation on Foreign Data Wrappers
- Oracle Official Documentation on Database concepts
- Some terminology comparisons between Oracle and SQL Server
- Download SSMS
- Download Oracle SQL Developer
- Download PGAdmin

Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
His expertise ranges from SQL Server to Oracle and Postgres for database administration and from SAP BO to SSIS, SSRS and Power BI regarding BI and ETL.
He has worked both in SQL Server and Oracle mostly in multinational environments with very high transaction volumes and large datasets. Performance tuning, indexing techniques and in general Database administration are his hot topics. Ensuring a 24/7 uptime of the various databases in shop is his main responsibility, as well as the best possible performances of all queries run on the databases. He has started working with PostgreSQL two years ago loving many of the features of this RDBMS.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2024 | Rookie of the Year – 2021