Problem
Identity columns are a widely used technique to provide a table with an automatically generated (AKA auto-increment surrogate key), but this technique has its caveats in terms of performance and there are some interesting differences between Microsoft SQL Server, Oracle and PostgreSQL.
Solution
In this tutorial, we will review the various differences of identity columns, the various parameters and functions involved and the importance of properly sizing the cache parameter in identity columns (and sequences).
As always, we will use the GitHub freely downloadable database sample Chinook, as it is available in multiple RDBMS formats at this link: https://github.com/cwoodruff/ChinookDatabase. It is a simulation of a digital media store, with some sample data, all you have to do is download the version you need and you have all the scripts for the data structure and all the inserts for data.
SQL Identity Column Syntax Overview
SQL Server
In SQL Server, identity columns are widely used, they can be defined when a table is created or added later to a table.
So, let’s create a new table in a SQL Server database that will hold Supplier data with an identity column with the CREATE TABLE statement below. The identity column is an INT data type, with a starting value of 1 and a seed value of 1. Here is the T-SQL code:
CREATE TABLE Supplier( SupplierId int identity (1,1) NOT NULL, CompanyName nvarchar(80) NULL, VATCode nvarchar(25) null, Address nvarchar(70) NULL, City nvarchar(40) NULL, State nvarchar(40) NULL, Country nvarchar(40) NULL, PostalCode nvarchar(10) NULL, Phone nvarchar(24) NULL, Fax nvarchar(24) NULL, Email nvarchar(60) NOT NULL, CONSTRAINT PK_Supplier PRIMARY KEY CLUSTERED ( SupplierId ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) )

In this script, I created a column SupplierId as an identity giving it a seed (first number) of 1 as the first parameter and an increment of 1 as the second parameter. That’s it, very easy!
As I mentioned before an identity column can be added to a table after it’s been created and that’s easy if we add it as a new column. If we add it to an existing column, it’s not so simple if the column is not empty and we’d like to preserve values, I will return to this later.
Oracle
In Oracle, identity columns were introduced for the first time in Oracle 12 C. Before that release, sequences were used to obtain a number to insert into the column.
Let’s create table Supplier in Oracle, here we have slightly different syntax and more parameters than SQL Server.
CREATE TABLE CHINOOK.SUPPLIER
(SUPPLIERID NUMBER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 CACHE 50) NOT NULL ENABLE,
COMPANYNAME VARCHAR2(80 BYTE) NOT NULL ENABLE,
VATCODE VARCHAR2(25),
ADDRESS VARCHAR2(70 BYTE),
CITY VARCHAR2(40 BYTE),
STATE VARCHAR2(40 BYTE),
COUNTRY VARCHAR2(40 BYTE),
POSTALCODE VARCHAR2(10 BYTE),
PHONE VARCHAR2(24 BYTE),
FAX VARCHAR2(24 BYTE),
EMAIL VARCHAR2(60 BYTE) NOT NULL ENABLE,
CONSTRAINT PK_SUPPLIER PRIMARY KEY (SUPPLIERID));

As you may have noticed, we have different syntax, GENERATED ALWAYS AS IDENTITY.
The three possibilities are:
- ALWAYS – a value is created with every insert and it is not possible to insert a value into this column. This is behavior is similar to SQL Server.
- BY DEFAULT – in this case the number is generated as a default so a value can always be inserted.
- BY DEFAULT ON NULL – the number is generated only in case a NULL value is used for that column.
We have some interesting parameters which are directly inherited from Oracle sequences and that is a clear clue of what’s going on under the hood with identity columns in Oracle. The parameters are START WITH, INCREMENT BY and CACHE. The first one is equivalent to the SEED of SQL Server, as well as INCREMENT BY. A really interesting parameter here is CACHE, which has no equivalent in SQL Server. In fact, there is a cache for identity numbers for SQL Server, but you cannot specify how many numbers are cached. In Oracle, this is inherited from sequences and it is possible to assign a specific range, in this case we have 50, the default is 20 like in Oracle sequences. That is very important for performance, but also tricky as it can lead to gaps in the identity column values. I will return to this subject later.
PostgreSQL
In PostgreSQL we have syntax and parameters almost identical to Oracle. Also, in PostgreSQL it is inherited from sequences and in particular before version 10 it was accomplished using the SERIAL parameter, anyway here’s the syntax.
CREATE TABLE SUPPLIER
(SUPPLIERID int GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 CACHE 50) NOT NULL,
COMPANYNAME VARCHAR(80) NOT NULL,
VATCODE VARCHAR(25),
ADDRESS VARCHAR(70),
CITY VARCHAR(40),
STATE VARCHAR(40),
COUNTRY VARCHAR(40),
POSTALCODE VARCHAR(10),
PHONE VARCHAR(24),
FAX VARCHAR(24),
EMAIL VARCHAR(60) NOT NULL,
CONSTRAINT PK_SUPPLIER PRIMARY KEY (SUPPLIERID))

All the considerations made for Oracle are also valid here, plus a difference in cache handling that makes the possibility of gaps even greater. In PostgreSQL, multiple sessions that insert values in the table each use their own cache pool. This is very important and different from the other two RDBMS.
Let’s check it out with the following example of two INSERT statements. If we have 2 sessions inserting data with the cache set to 50 this is what is going to happen.
Session 1
insert into supplier(companyname,vatcode,address,city,country,email)
VALUES ('TEST1','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com')
Session 2
insert into supplier(companyname,vatcode,address,city,country,email)
VALUES ('TEST2','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com')
Let’s see what new records we have in the table.
select * from supplier

You can see that the second session started from 51, as the first batch of 50 numbers were already assigned to the first session. That can obviously lead to some huge gaps in the numbers assigned to the identity column. For some applications that can be a problem. It is important to note that that this behavior in PostgreSQL is valid true for both identity columns and sequences.
Manually Assign SQL Identity Value
SQL Server
First of all, we tackle the GENERATED ALWAYS AS IDENTITY which is a parameter not present in SQL Server, in fact, this is the default behavior of SQL Server. An identity column in SQL Server always generates a number.
But is it possible to manually insert a value in that column? The answer is yes, let’s demonstrate it.
First, we try to insert a new row in the table Supplier that we created before, trying to add the SupplierId value.
insert into supplier (SupplierId,companyname,vatcode,Address,city,country,email) values (1,'TEST1','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com')

The following error is expected, since this is an identity column and we cannot insert a value since it is always automatically generated. We see that the error already gives us a hint on what to do.
So now let’s turn on the IDENTITY_INSERT property that will enable us to insert the value.
set identity_insert supplier on
And repeat the insert.
insert into supplier (SupplierId,companyname,vatcode,Address,city,country,email) values (1,'TEST1','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com')

Let’s check the data.
select *from Supplier

This property can be turned off if we do not need it anymore and we want to prevent accidental inserts.
set identity_insert supplier off

Oracle
Let’s try it on Oracle. In order to allow the possibility to insert a value in the identity column in Oracle we must issue an ALTER TABLE and modify the column, but first let’s try to insert a new row in the table as is.
insert into chinook.supplier (SupplierId,companyname,vatcode,Address,city,country,email) values (1,'TEST1','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com');

Now let’s issue the ALTER TABLE modifying the column.
alter table chinook.supplier modify SupplierId GENERATED BY DEFAULT AS IDENTITY INCREMENT BY 1 START WITH 1 CACHE 50 NOORDER NOCYCLE NOKEEP NOSCALE NOT NULL;
And retry the insert.
insert into chinook.supplier (SupplierId,companyname,vatcode,Address,city,country,email) values (1,'TEST1','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com'); commit;

Let’s check the data.
select * from chinook.supplier;

Pretty much the same thing as in SQL Server even though it is done a little differently.
PostgreSQL
Let’s try on PostgreSQL. Here we have a similar approach as in Oracle, but with a different syntax in order to modify the column.
Let’s start by trying to insert a new row with the SupplierId column value specified.
insert into supplier (SupplierId,companyname,vatcode,Address,city,country,email) values (3,'TEST1','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com');

Now let’s do the ALTER TABLE in order to modify the column, please note that the syntax in PostgreSQL is different than Oracle.
alter table supplier alter column SupplierId set GENERATED BY DEFAULT;

And reissue the insert.
insert into supplier (SupplierId,companyname,vatcode,Address,city,country,email) values (3,'TEST1','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com');

Let’s check again the contents of the table.
SELECT * FROM SUPPLIER

Please notice that PostgreSQL was suggesting to use OVERRIDING SYSTEM VALUE, so let’s try it!
First, we go back to the initial state of the table modifying the supplierid column.
alter table supplier alter column SupplierId set GENERATED ALWAYS;

Now let’s try to insert using the OVERRIDE option.
insert into supplier (SupplierId,companyname,vatcode,Address,city,country,email) OVERRIDING SYSTEM VALUE values (4,'TEST1','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com');

Let’s check the data.
select * from supplier

So, we’ve seen that there is also another possibility to insert data in an identity column in PostgreSQL.
Setting Start Value for SQL Identity Value
SQL Server
In SQL Server it is possible to define both the number on which an identity column starts and the increment, the first is referred to as the SEED of the identity column and by default is set to 1, but it can be another number, even a negative number. That is a common trick to double the numbers available for the identity column.
But is it possible to change the seed after the identity column is created? Of course, yes! For this purpose, commonly referred to as “reseed”, we use DBCC CHECKIDENT. Let’s do an example modifying the SupplierId column and letting it start from 10.
dbcc checkident('Supplier',reseed,10)

Let’s check the setting, introducing an important function that returns the last inserted value in an identity column, IDENT_CURRENT. Please notice that in all these functions the identifying parameter is always the table name, that’s because in SQL Server (and also on the other two RDBMS) you can define only one identity column for a table.
select IDENT_CURRENT('Supplier')

The same could also be done using DBCC CHECKIDENT, but this time with the option NORESEED that reports only the current value of the identity column.
dbcc checkident('Supplier',noreseed)

Oracle
As I wrote above in Oracle the parameter START WITH option defines the number on which the identity column should start, this can be defined when the column is created and also changed afterwards issuing ALTER TABLE.
alter table chinook.supplier modify SupplierId GENERATED BY DEFAULT AS IDENTITY START WITH 50;

Now let’s try to see the value of the identity column. In Oracle, unfortunately there is no equivalent to the IDENT_CURRENT function, but we can use a workaround. First we need to obtain the name of the sequence used by the identity column, that can be done with the following query.
select column_name, data_default from dba_tab_cols where owner='CHINOOK' AND table_name = 'SUPPLIER';

Now that we have the sequence we can easily check the current value.
SELECT CHINOOK.ISEQ$$_85607.currval FROM DUAL;

Note that if the sequence has not been used in the session you will get this error.

As suggested by the error message you can fix this by using NEXTVAL instead of CURRVAL.
SELECT CHINOOK.ISEQ$$_85607.nextval FROM DUAL;

PostgreSQL
In PostgreSQL we have basically two ways to change the value that an identity column starts. One is to issue an ALTER TABLE and modify the column as in Oracle, the other is to use the SETVAL function as in a normal sequence in PostgreSQL.
I want to show this later method so in order to modify the Supplierid column like with the two other RDBMS we need to get the name of the sequence using the PG_GET_SERIAL_SEQUENCE function and then issue SETVAL all in the same SELECT.
select setval(pg_get_serial_sequence('supplier','supplierid'),100)
from supplier

Please note that the SELECT returns results for each row currently in the table, but the value of the Supplierid column in those rows has not been changed.
Now we can check the current value of the identity column using function CURRVAL in a way similar to what we did in Oracle.
select currval(pg_get_serial_sequence('supplier','supplierid'))

Setting Increment Value for SQL Identity Value
SQL Server
As we have seen that the increment in SQL Server is defined when the identity column is created, is it possible to change it afterwards? The easy answer to this question for SQL Server is no, there is no native method to change the increment of an identity column in SQL Server.
However, there is a very nice workaround using SWITCH partition between the old table with the identity column and a new table, bearing in mind that all tables are partitioned: at least they each have one partition! This technique is also very useful for other modifications especially on large tables. I will not explain it here because there is already an article with examples here: How do I change the increment of an identity column.
Oracle
In Oracle we can use ALTER TABLE MODIFY COLUMN like we used for the START parameter, let’s change the increment of supplierid column to 3.
alter table chinook.supplier modify SupplierId GENERATED BY DEFAULT AS IDENTITY INCREMENT BY 3;

Let’s insert a new row.
insert into chinook.supplier (companyname,vatcode,Address,city,country,email)
values ('TEST5','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com');
commit;

And take a look at what is in the table.
select * from chinook.supplier;

Remember that in the last example we changed the start of the identity column to 100, so incrementing it 3 units counting the 100 gives us a value of 102.
To be extra sure this is the case, let’s insert another row and check the results. This time the supplierid is 105 as expected.
insert into chinook.supplier (companyname,vatcode,Address,city,country,email)
values ('TEST5','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','testemail.com');
commit;
select * from chinook.supplier;

PostgreSQL
In PostgreSQL we have a similar way to accomplish this task as in Oracle, we just issue an ALTER TABLE ATER COLUMN.
alter table supplier alter column supplierid set increment by 3

Let’s test it by inserting a new row.
insert into supplier (companyname,vatcode,Address,city,country,email)
values ('TEST5','12345678910','TEST ADDRESS','TEST CITY', 'TEST COUNTRY','test@email3.com');
And check the data.
select * from supplier
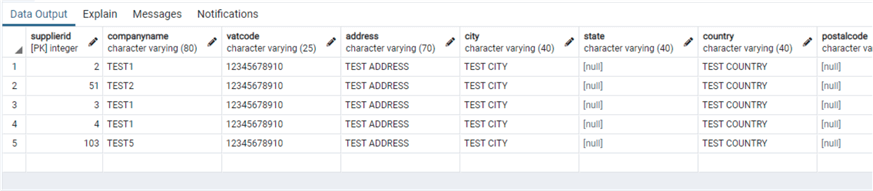
Note that in the last PostgreSQL example we changed the identity column to start from 100, that is why we have a value of 103.
Conclusion
In this article we have seen what an identity column is and the various ways to set it up and modify it in the three RDBMS: in particular, we have learned the various options with which an identity column could be set and various functions to see the state of the column.
Next Steps
- As usual links to the official documentation:
- SQL Server:
- Oracle
- PostgreSQL :
- Some links to other tips regarding Identity Columns:

Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
His expertise ranges from SQL Server to Oracle and Postgres for database administration and from SAP BO to SSIS, SSRS and Power BI regarding BI and ETL.
He has worked both in SQL Server and Oracle mostly in multinational environments with very high transaction volumes and large datasets. Performance tuning, indexing techniques and in general Database administration are his hot topics. Ensuring a 24/7 uptime of the various databases in shop is his main responsibility, as well as the best possible performances of all queries run on the databases. He has started working with PostgreSQL two years ago loving many of the features of this RDBMS.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2024 | Rookie of the Year – 2021
Hello Anne,
yes correct Oracle uses Sequences to manage Identity Columns, so every time that you create an Identity Column a new sequence is created.
Does that mean that Oracle identity column is actually using a sequence? when Oracle identity column is created, it is actually also creating a new sequence?
Thanks