By: Aaron Bertrand | Updated: 2022-03-01 | Comments | Related: 1 | 2 | 3 | 4 | 5 | > Functions System
Problem
In Part 1, I demonstrated how the FORMAT function can be detrimental to performance when compared to equivalent expressions involving non-CLR built-ins like CONVERT and DATEPART. At the end of that tip, I said that we would look at other ways to expose specialized date formats without the FORMAT function, without user-defined functions, and without elaborate expressions complicating our queries.
Solution
As a reminder, the methods I wanted to compare in the previous tip were FORMAT with the D parameter:
DECLARE @d date = '20220114'; SELECT FORMAT(@d, 'D', 'en-us');
And an equivalent expression involving CONCAT_WS, DATENAME, CONVERT, and DATEPART (which, for analysis in this article, I'll simply refer to as "convert"):
SET LANGUAGE us_english;
DECLARE @d date = '20220114';
SELECT CONCAT_WS(', ',
DATENAME(WEEKDAY, @d),
DATENAME(MONTH, @d) + ' ' + CONVERT(varchar(2), DATEPART(DAY, @d)),
DATEPART(YEAR, @d)
);
Both of which produce the following output:
Friday, January 14, 2022
Since we already know that FORMAT is much slower, it can be advantageous to use the more tedious expression, but also useful to hide it away. Two methods I have used to hide away complex expressions like this:
- Computed columns
- Materialized columns, pre-populated (either manually or with a trigger)
Let's look at these approaches and the impact they might have on a workload.
Computed Column
We can add a computed column definition to any table like this:
ALTER TABLE dbo.t1 ADD PrettyDate AS
(
CONVERT(varchar(50), FORMAT(modify_date, 'D', 'en-us'))
);
And we could do the same with the more complex expression. Unfortunately, a computed column that involves the output of FORMAT or certain built-ins like DATENAME can't be deterministic, because the output can vary based on language settings (and FORMAT is blocked explicitly even though, in some cases, language can't become a factor).
The end result is that this column can't be persisted or indexed, so we can't shift the workload impact from the read side of the workload to the write side. Predictably, these workloads all have runtimes equivalent to those without computed columns, since the bulk of the work is still done at query time.
We can set up these three tables:
SELECT o.*, column_name = c.name
INTO dbo.Columns_Base
FROM sys.all_objects AS o
INNER JOIN sys.all_columns AS c
ON o.[object_id] = c.[object_id]
WHERE 1 = 0; CREATE CLUSTERED INDEX cix ON dbo.Columns_Base(name, column_name); SELECT * INTO dbo.Columns_Computed_Convert FROM dbo.Columns;
SELECT * INTO dbo.Columns_Computed_Format FROM dbo.Columns; ALTER TABLE dbo.Columns_Indexed_Convert ADD PrettyDate AS
(
CONVERT(varchar(50),
CONCAT_WS(', ',
DATENAME(WEEKDAY, modify_date),
DATENAME(MONTH, modify_date) + ' '
+ CONVERT(varchar(2), DAY(modify_date)),
YEAR(modify_date)
)
); ALTER TABLE dbo.Columns_Indexed_Format ADD PrettyDate AS
CONVERT(varchar(50), FORMAT(modify_date, 'D', 'en-us')); CREATE CLUSTERED INDEX cix ON dbo.Columns_Computed_Format (name, column_name);
CREATE CLUSTERED INDEX cix ON dbo.Columns_Computed_Convert(name, column_name);
Then we can do time population from the write side of the application:
TRUNCATE TABLE dbo.Columns_Base; INSERT /* insert_base */ dbo.Columns_Base
(
name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name
)
SELECT o.*, column_name = c.name
FROM sys.all_objects AS o
INNER JOIN sys.all_columns AS c
ON o.[object_id] = c.[object_id]; GO 50 -- repeat for other two tables
We can then see that Query Store found these activities roughly equivalent:
SELECT query = CASE
WHEN qt.query_sql_text LIKE N'%insert_base%'
THEN 'insert_base'
WHEN qt.query_sql_text LIKE N'%insert_convert%'
THEN 'insert_convert'
WHEN qt.query_sql_text LIKE N'%insert_format%'
THEN 'insert_format'
END,
executions = rs.count_executions,
rs.avg_duration
FROM sys.query_store_query AS q
INNER JOIN sys.query_store_query_text AS qt
ON q.query_text_id = qt.query_text_id
INNER JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs
ON rs.plan_id = p.plan_id
WHERE qt.query_sql_text LIKE N'%/* insert_% */%'
AND qt.query_sql_text NOT LIKE N'%sys.query%'
ORDER BY query;
Results (microseconds):
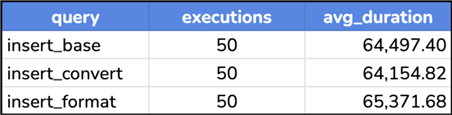
And if we run a read workload like last time, but this time relying on the computed column:
SET NOCOUNT ON;
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO DECLARE @d varchar(50); SELECT /* select_base */ @d = CONCAT_WS(', ',
DATENAME(WEEKDAY, modify_date),
DATENAME(MONTH, modify_date) + ' '
+ CONVERT(varchar(2), DATEPART(DAY, modify_date)),
CONVERT(char(4), DATEPART(YEAR, modify_date)))
FROM dbo.Columns_Base;
GO 50 DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO DECLARE @d varchar(50); SELECT /* select_convert */ @d = PrettyDate
FROM dbo.Columns_Computed_Convert;
GO 50 DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO DECLARE @d varchar(50); SELECT /* select_format */ @d = PrettyDate
FROM dbo.Columns_Computed_Format;
GO 50
With slight adjustments to the Query Store query, we will see remarkably similar results as before:
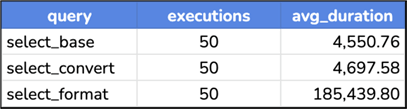
And if we look at the space used:
EXEC sys.sp_spaceused @objname = N'dbo.Columns_Base';
EXEC sys.sp_spaceused @objname = N'dbo.Columns_Computed_Convert';
EXEC sys.sp_spaceused @objname = N'dbo.Columns_Computed_Format';
The storage footprint is identical:

We can see that the computed column allows us to take the complication out of the end user query, without a significant impact on either the write side of the workload or the read side, and without incurring any additional storage. However, the computed column does not help us escape the impact of FORMAT on the read query, it only makes the syntax less cumbersome.
Materialized column, pre-populated
Another way we can shift the complexity away from the select query is to have a column on the table that stores the actual calculated value. We can do this by either changing our insert statements (when feasible) or using a trigger when it isn't convenient to change our existing code.
To keep things simple for this article, we'll assume modify_date is immutable and can't be changed after insert.
This time we'll create four tables:
SELECT o.*, column_name = c.name,
PrettyDate = CONVERT(varchar(50), NULL)
INTO dbo.Columns_Insert_Convert
FROM sys.all_objects AS o
INNER JOIN sys.all_columns AS c
ON o.[object_id] = c.[object_id]
WHERE 1 = 0; CREATE CLUSTERED INDEX cix ON dbo.Columns_Insert_Convert(name, column_name); SELECT * INTO dbo.Columns_Insert_Format FROM dbo.Columns_Insert_Convert;
SELECT * INTO dbo.Columns_Trigger_Convert FROM dbo.Columns_Insert_Convert;
SELECT * INTO dbo.Columns_Trigger_Format FROM dbo.Columns_Insert_Convert; CREATE CLUSTERED INDEX cix ON dbo.Columns_Insert_Format (name, column_name);
CREATE CLUSTERED INDEX cix ON dbo.Columns_Trigger_Convert (name, column_name);
CREATE CLUSTERED INDEX cix ON dbo.Columns_Trigger_Format (name, column_name);
And for the tables with trigger in the name, we'll create these instead of insert triggers:
CREATE TRIGGER dbo.PreCalcDate_Convert
ON dbo.Columns_Trigger_Convert
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON; INSERT dbo.Columns_Trigger_Convert
(
name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name,
PrettyDate
)
SELECT name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name,
CONCAT_WS(', ',
DATENAME(WEEKDAY, i.modify_date),
DATENAME(MONTH, i.modify_date) + ' '
+ CONVERT(varchar(2), DATEPART(DAY, i.modify_date)),
CONVERT(char(4), DATEPART(YEAR, i.modify_date)))
FROM inserted AS i;
END
GO CREATE TRIGGER dbo.PreCalcDate_Format
ON dbo.Columns_Trigger_Format
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON; INSERT dbo.Columns_Trigger_Format
(
name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name,
PrettyDate
)
SELECT name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name,
FORMAT(i.modify_date, 'D', 'en-us')
FROM inserted AS i;
END
GO
Then we can do time population using the following script:
SET NOCOUNT ON;
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO TRUNCATE TABLE dbo.Columns_Insert_Convert; INSERT /* insert_convert */ dbo.Columns_Insert_Convert
(
name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name,
PrettyDate
)
SELECT o.*, column_name = c.name, CONCAT_WS(', ',
DATENAME(WEEKDAY, o.modify_date),
DATENAME(MONTH, o.modify_date) + ' '
+ CONVERT(varchar(2), DATEPART(DAY, o.modify_date)),
CONVERT(char(4), DATEPART(YEAR, o.modify_date)))
FROM sys.all_objects AS o
INNER JOIN sys.all_columns AS c
ON o.[object_id] = c.[object_id];
GO 50 DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO TRUNCATE TABLE dbo.Columns_Insert_Format; INSERT /* insert_format */ dbo.Columns_Insert_Format
(
name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name,
PrettyDate
)
SELECT o.*, column_name = c.name, FORMAT(modify_date, 'D', 'en-us')
FROM sys.all_objects AS o
INNER JOIN sys.all_columns AS c
ON o.[object_id] = c.[object_id];
GO 50 DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO TRUNCATE TABLE dbo.Columns_Trigger_Convert; INSERT /* trigger_convert */ dbo.Columns_Trigger_Convert
(
name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name
)
SELECT o.*, column_name = c.name
FROM sys.all_objects AS o
INNER JOIN sys.all_columns AS c
ON o.[object_id] = c.[object_id];
GO 50 DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO TRUNCATE TABLE dbo.Columns_Trigger_Format; INSERT /* trigger_format */ dbo.Columns_Trigger_Format
(
name, object_id, principal_id, schema_id, parent_object_id,
type, type_desc, create_date, modify_date, is_ms_shipped,
is_published, is_schema_published, column_name
)
SELECT o.*, column_name = c.name
FROM sys.all_objects AS o
INNER JOIN sys.all_columns AS c
ON o.[object_id] = c.[object_id];
GO 50
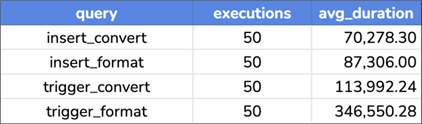
The insert timings look like this, showing substantial overhead for triggers in general and the FORMAT versions even more so:
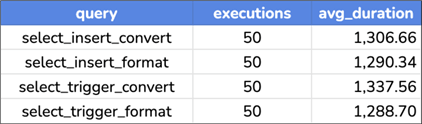
But in all four cases, taking this performance hit on the write side leads to much more consistent select performance across the board:
One additional side effect of the trigger is that it produces a little more fragmentation, so the tables aren't identical immediately:

But they are after a rebuild:

So, triggers are a convenient way to avoid having to change either insert code or select queries, and keep select queries efficient, but they do have an impact on the write side of the workload - and may require more index maintenance to keep them slim.
Conclusion
Here we can compare the computed column and trigger approaches to see the worst performers for each operation as well as for cumulative duration:
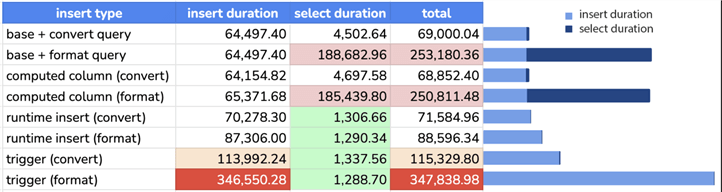
This should make it clear that you should:
- Avoid FORMAT except in the case where you can add a column, are not inserting very often, and can put the format calculation in the insert statements.
- Avoid triggers if possible.
- Store the data and use CONVERT at insert time for a good balance of write workload impact and optimal read performance.
I still like the idea of FORMAT, I just wish the implementation didn't come with crippling overhead. The nice thing about SQL Server is you can choose whether or not to use this specific function and, as I've demonstrated here, exactly where you can take the lesser performance hit of any expression you use as an alternative.
Next Steps
See these tips and other resources:
- FORMAT is a convenient but expensive SQL Server function - Part 1
- FORMAT() is nice and all, but…
- Format SQL Server Dates with FORMAT Function
- SQL Server Date and Time Functions with Examples
- Determine SQL Server Date and Time Parts with DATEPART and DATENAME Functions
- SQL Convert Date to YYYYMMDD






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-03-01
