Problem
SSIS developers often build packages in such a way that increases package validation and compilation time, which is detrimental to performance. How can we understand SSIS bad practices and use better alternatives to improve performance?
Solution
This tip will explain some mistakes SSIS developers usually make when designing ETL and how they should be avoided.
Adding Useless SSIS Components
Before getting started, it is worth mentioning that each task or component added within an SSIS package is validated at runtime. This could be noted by checking the Progress tab when executing the package, as shown in the image below.

Tim Mitchell stated that the validation scope is concentrated mainly on data flow components, looking for unexpected changes in column metadata, missing tables, or invalid connections. Package validation will also check that a needed connection is present, though it will usually not indicate an error if that connection is offline. Package validation does not usually fail when a source file is missing or a directory path is invalid; each task or component added to a package increases the required validation time, especially when testing a connection, parsing an expression, or validating a script.
To illustrate this, we created a package with one data flow task that transfers the data from one SQL table to another. Then we added five derived column components, as shown below.

When executing the package, the elapsed validation time is 1.875 seconds.

Next, we tried to put all five derived column expressions within one derived column component and execute the package. The validation time decreased to 0.829 seconds.
As illustrated, adding four unnecessary components that require no external connection increased the validation time by one second. This amount of time may significantly increase when adding a component connecting to a database with considerable traffic. In that case, just reading the metadata of a table may take a considerable amount of time.
I agree that adding more components is mandatory in several cases. Still, it is worth double-checking your package design before deploying it.
Wrong Data Pipeline Configuration in SSIS
The second bad practice that may affect the package performance is related to the data flow task configuration. Let’s briefly discuss some essential properties that may be ignored or misused by SSIS developers and can affect package performance.
Suppose you are developing a package that transfers a small amount of data or the execution time is insignificant. In that case, it is unnecessary to adjust any data flow properties. In contrast, this is essential when developing a data warehousing job, working with massive data, or even with limited resources.
DefaultBufferMaxRows and DefaultBufferSize
Before starting, it is worth mentioning that a data buffer is a region of memory used to temporarily store data while it is being moved from one place to another (Wikipedia).
The DefaultBufferSize property indicates the default size of the data flow task's buffer. The default value is set to 10485760 bytes = 10 megabytes. The DefaultBufferMaxRows property indicates the maximum number of rows that can fit within the data buffer. The default value is set to 10000 rows.
As mentioned by Microsoft, the engine data flow engine uses the following rules to determine the buffer size:
- If the loaded data is more than the value of DefaultBufferSize, the engine reduces the number of rows.
- If the loaded data is less than the internally-calculated minimum buffer size, the engine increases the number of rows.
- Suppose the loaded data falls between the minimum buffer size and the value of DefaultBufferSize. In that case, the engine sizes the buffer as close as possible to the estimated row size times the value of DefaultBufferMaxRows.
To optimize those values, SSIS developers should run the package with the default values, then change those values and compare the performance until they reach the optimal ones. A great article was previously published by Koen Verbeeck explaining the optimization process: Improve SSIS data flow buffer performance.
AutoAdjustBufferSize
Since DefaultBufferMaxRows and DefaultBufferSize properties affect each other, Microsoft introduced a new property in SQL Server 2016 called AutoAdjustBufferSize. If this property is set to True (by default, it is set to False), the buffer size is calculated using the DefaultBufferMaxRows value, and DefaultBufferSize's value is ignored.
Another Koen Verbeeck article illustrates the impact of setting this property to True: Improve Data Flow Performance with SSIS AutoAdjustBufferSize.
RunInOptimizedMode
This property is fundamental. It removes unused columns, outputs, or even components at runtime, increasing the data flow performance and decreasing memory usage. An example of how several SSIS developers may be unaware of unused columns in the data buffer is illustrated in the following Stack Exchange answer: SSIS OLE DB Source Editor Data Access Mode: "SQL command" vs. "Table or view".
MaxConcurrentExcecutables and EngineThreads
MaxConcurrentExecutables is a control flow property defining the number of tasks that can be run simultaneously. The default value is -1, which means the number of physical or logical processors plus 2. This property may not be significant when all tasks run sequentially. In contrast, it highly affects package performance when some tasks run in parallel.
On the Data Flow level, the EngineThreads define how many components can be executed in parallel within the data flow—for example, reading from several sources simultaneously.
Developers should be careful when editing those values since running more threads than the number of available processors can decrease performance because of the frequent context-switching between threads.
Microsoft stated that the general rule is not to run more threads in parallel than the number of available processors.
SSIS Implicit Conversions
Flat file connection managers treat all columns in flat files as string (DS_STR) data types, including numeric and date columns. Before pushing data into the destination table, SSIS stores the whole data set in a buffer memory, as explained earlier, and applies the required transformations. String data types will require more buffer space, reducing ETL performance.
Thus, we should convert all the columns into the appropriate data type to avoid implicit conversion, which will help the SSIS engine to handle more rows in a single buffer. This can be done from the flat file connection manager advanced tab, as shown in the image below.
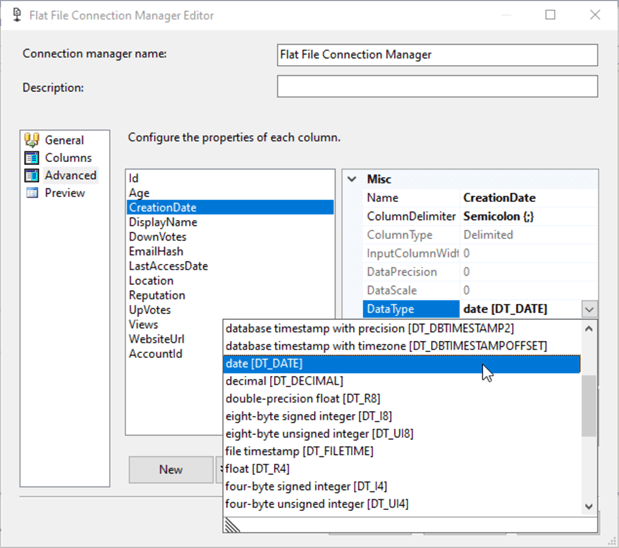
A "Suggest Types" button was recently added to the advanced tab.
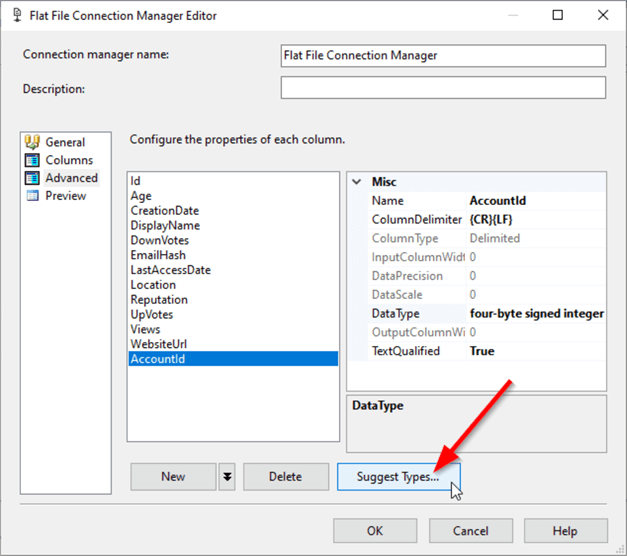
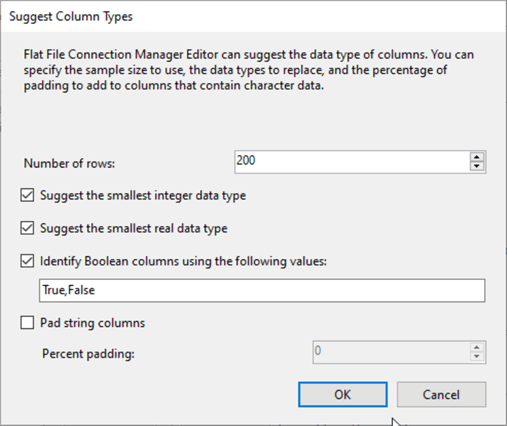
This button opens the Suggest Column Types dialog, which helps identify the data type and length of columns in a Flat File Connection Manager based on a sampling of the file content.
We created two packages to import a 75 MB flat file into SQL to test how implicit conversion can increase package performance. In the first package, we specified the appropriate data types within the flat file connection manager, while we left all columns as strings in the other one.
The execution results show that the first package execution finished after 15.539 seconds.
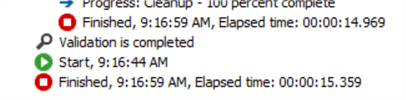
In contrast, the second package execution finished after 18.109 seconds.
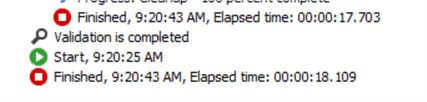
These results show that implicit conversion decreased the execution time by 2.8 seconds over a 75 MB flat file. This value will increase when handling larger files.
Next Steps
- Read more about the SSIS package performance optimization methods: SQL Server Integration Services SSIS Performance Tuning Techniques.
- For those interested in more details, there is an excellent article in the Microsoft documentation describing all Data Flow Task performance features: Data Flow Performance Features – SQL Server Integration Services (SSIS).
- As mentioned before, more details on optimizing SSIS data flow tasks can be found in the following articles:

Hadi Fadlallah is an SQL Server professional with more than 10 years of experience. His main expertise is in data integration. He’s one of Stackoverflow.com’s top ETL and SQL Server Integration Services contributors. Also, he is a university lecturer and writes scientific and technical articles on several blogs. On the academic level, he holds a Ph.D. degree in data science focusing on context-aware big data quality and two master’s degrees in computer science and business computing.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2025 | Author of the Year Contender – 2023 | Rookie of the Year – 2022


