Problem
One person writes a query to filter some records on a particular day. Another person writes another query to filter some records in a month. One index may not be effective for both search modes and this article provides insight into optimizing query performance when clustered index seek operation is slow.
Solution
For some tables, using an ID is not an ideal choice as a clustering key because users search for records based on a date range. We can ask the development team which column is used in the predicates frequently for a given table. Using the date as the leftmost column in the clustered index key makes sense if the answer is a date column, but that might not be enough. The attributes that make up an efficient clustered index key are Narrow, Unique, Static, and Ever-increasing. For these tables, a composite key is a great choice. For example, combining CreationDate and ID would be a good choice. CreationDate is an ever-increasing date value. It is static, meaning it is rarely updated. We need to choose small-sized data types for date and Id. Using Datetime2 for the date and Int for the Id is a good choice, but it depends on how many rows you want to store in your table. The Int data type is an integer value from -2,147,483,648 to 2,147,483,647 and we use the Id to make the clustered index key unique.
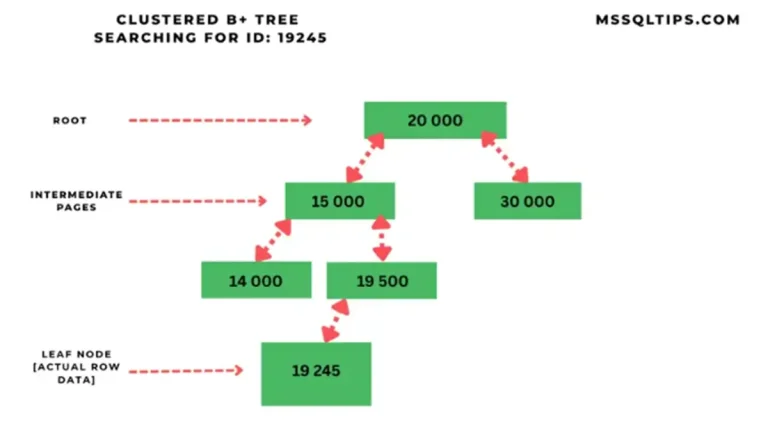
Let’s consider the scenario where a unique clustered index has been created on the table using a combination of CreationDate and ID. If we write a query to filter some records based on CreationDate, SQL Server will perform a clustered index seek operation to show the result. At first glance, it looks good, but it’s not always fast enough. Based on my experience, I have noticed that many tables have two columns frequently used in user search queries, for example, the Date and DeviceId columns. When you want to view the information of a device in a month, the clustered index seek operation will not be fast. Assume that the data distribution is approximately the same for all devices. I’m going to show you this with a simulation.
Set Up Test Environment
I’ll use the StackOverflow database for the examples.
The Users table has a clustered primary key on the Id column, so I load the original contents of the Users table into a new table.
DROP TABLE IF EXISTS [dbo].[Users_new];GO
CREATE TABLE [dbo].[Users_new](
[Id] [int] IDENTITY(1,1),
[AboutMe] [nvarchar](max) NULL,
[Age] [int] NULL,
[CreationDate] [datetime] NOT NULL,
[DisplayName] [nvarchar](40) NOT NULL,
[DownVotes] [int] NOT NULL,
[EmailHash] [nvarchar](40) NULL,
[LastAccessDate] [datetime] NOT NULL,
[Location] [nvarchar](100) NULL,
[Reputation] [int] NOT NULL,
[UpVotes] [int] NOT NULL,
[Views] [int] NOT NULL,
[WebsiteUrl] [nvarchar](200) NULL,
[AccountId] [int] NULL)
GO
SET IDENTITY_INSERT dbo.Users_new ON;
GO
INSERT INTO dbo.Users_new With (Tablock) ([Id], [AboutMe], [Age], [CreationDate], [DisplayName], [DownVotes], [EmailHash], [LastAccessDate], [Location], [Reputation], [UpVotes], [Views], [WebsiteUrl], [AccountId])
SELECT [Id],[AboutMe], [Age], [CreationDate], [DisplayName], [DownVotes], [EmailHash], [LastAccessDate], [Location], [Reputation], [UpVotes], [Views], [WebsiteUrl], [AccountId]
FROM dbo.Users;
GO
SET IDENTITY_INSERT dbo.Users_new OFF;
GO
The new table is a heap table and I will create a unique clustered index on it.
CREATE UNIQUE CLUSTERED INDEX IX_CreationDate_Id ON dbo.Users_new (CreationDate, Id) WITH (DATA_COMPRESSION = PAGE)
GO
The following script creates a temporary table, inserts some values, and then joins it with the Users table based on the Reputation column. We want to show the details of the records in one day. To view the actual execution plan, press ctrl + m.
SET STATISTICS IO ON
GO
<br />DROP TABLE IF EXISTS #Reputation_1
CREATE TABLE #Reputation_1
(Reputation INT NOT NULL)
INSERT INTO #Reputation_1 VALUES (6), (11), (3), (8), (14), (21), (4), (18), (10), (20)
SELECT u.* FROM dbo.Users_new u INNER JOIN #Reputation_1 r ON r.Reputation = u.Reputation
WHERE CreationDate BETWEEN '2016-10-01' AND '2016-10-02'
GO
To get IO statistics, we use the command below:
SET STATISTICS IO ON
GO
The following image shows the IO statistics:

As you can see, the number of logical reads is 31, meaning SQL Server read 31 8KB pages to show the result. We wrote a query to find details of some reputation values on a particular day. SQL Server performed a clustered index seek operation, as you see in the following image:

So far, so good. I want to write a query to find some records in a month:
DROP TABLE IF EXISTS #Reputation_2
CREATE TABLE #Reputation_2(R(Reputation INT NOT NULL)
INSERT INTO #Reputation_2 VALUES (215),(680)
SELECT U.* FROM dbo.Users_new u INNER JOIN #Reputation_2 r ON r.Reputation = u.Reputation
WHERE CreationDate Between '2016-10-01' And '2016-11-01'
GO
The following image shows the number of logical reads is 1505:

To find only four rows, SQL Server read 1505 pages. Look at the number of rows read:

In October 2016, over 183,000 users were added to the StackOverflow Users table. If you want to find a user with a reputation of 680, SQL Server must read all records in October 2016. One of the users created in October 2016 has a reputation of 680. Imagine a table that has 100 million records per month. Even if you’re querying just a few records for a given month, the query will still need to scan through 100 million rows. At this point, we need to create a non-clustered index to decrease logical reads and improve query performance.
I’m going to create a non-clustered index on the reputation column:
CREATE INDEX IX_Reputation ON dbo.Users_new(Reputation)
WITH (DATA_COMPRESSION = PAGE)
GO
I will run the query again:
SELECT U.* FROM dbo.Users_new u
INNER JOIN #Reputation_2 r ON r.Reputation = u.Reputation
WHERE CreationDate Between '2016-10-01' And '2016-11-01'
GO
The following image shows that the number of logical reads has been reduced to 18:

The query execution plan shows that SQL Server utilized a non-clustered index seek followed by a key lookup operation, as depicted in the image below:

Summary
Clustered index seek operations are not always fast. In a table where users write queries to find records based on a date column, using the date as the leftmost column in the clustered index key makes sense. However, you cannot rely on it for all queries. In some tables, there are two columns where users perform most searches based on, like date and DeviceId. It may be necessary to create a non-clustered index to optimize query execution speed.
Next Steps
- SQL Server Clustered Indexes
- SQL Server non-Clustered Indexes
- Different Approaches to Correct SQL Server Parameter Sniffing

Mehdi Ghapanvari is an SQL Server database administrator with 6+ years of experience. His main area of expertise is improving database performance. He is skilled at managing high-performance servers that can handle several terabytes of data and hundreds of queries per second, ensuring their availability and reliability. To enhance the performance of the database, he has implemented various performance-tuning techniques, including query optimization and index tuning. He has also developed backup and recovery strategies to protect critical data in case of disasters. Mehdi currently manages the SQL Server databases for a large organization. Mehdi is actively seeking new opportunities to apply his expertise and contribute to impactful projects. You can reach him at SQLDBA.Mehdi@Gmail.com.
- MSSQLTips Awards: Rookie of the Year – 2023
- MSSQLTips Trendsetter Award: 2026


From Mehdi…
In this article, the first query filters some records in a day. The second query filters some records within a month. The conditions are not the same, but your question is perfectly valid. In general, non-clustered indexes are narrower than clustered indexes. A clustered index includes all columns at the leaf level. But the non-clustered index contains one or several columns at the leaf level.
Hello Mehdi,
Awesome article. However, can you explain why the clustered index seek performed more logical reads versus a non clustered index?