Problem
I noticed that after rebuilding a clustered columnstore index the performance got worse. In this article, we look at what the problem was and how this was resolved.
Solution
Columnstore indexes are the standard for storing and querying large data warehouse fact tables. One of the benefits of using a columnstore index is that SQL Server can skip columns not requested by a query and it does not load data from those columns into memory. Moreover, the columnstore index achieves high performance and compression rates by dividing the table into rowgroups and compressing each rowgroup in a column-wise manner. Columnstore indexes should improve performance but after rebuild the index the performance was worse.
Before delving into the problem and solution, let’s review two important concepts:
- Rowgroups: The grouping of rows into rowgroups in SQL Server columnstore indexes is based on the sort order of the source table at the time the columnstore index is created. The maximum number of rows per rowgroup is 1,048,576 rows. To optimize query performance, it is essential to eliminate unnecessary rowgroups during query execution.
- Table Partitioning: Is a technique that allows a large table to be divided into smaller, more manageable sections without needing to create individual tables for each section.
After presenting the definitions, I will illustrate the utilization of data partitioning as a solution to prevent query performance degradation after rebuilding a clustered columnstore index.
Setup Test Environment
The following script creates a database and table and populates it with some values:
USE master
GO
CREATE DATABASE Test ON Primary (Name = Test, FileName = N'D:\Data\Test.mdf', Size = 2048 MB, FileGrowth = 512 MB)
LOG ON (Name = TestLog, FileName = N'D:\Data\TestLog.ldf', Size = 2048 MB, FileGrowth = 512 MB)
GO
USE Test
GO
DROP TABLE IF EXISTS Tbl_Test
;With Tbl_0(c) As
(Select 0 Union All Select 0),
Tbl_1 AS (Select t1.C From Tbl_0 t1 Cross Join Tbl_0 t2),
Tbl_2 AS (Select t1.C From Tbl_1 t1 Cross Join Tbl_1 t2),
Tbl_3 AS (Select t1.C From Tbl_2 t1 Cross Join Tbl_2 t2),
Tbl_4 AS (Select t1.C From Tbl_3 t1 Cross Join Tbl_3 t2),
Tbl_5 AS (Select t1.C From Tbl_4 t1 Cross Join Tbl_4 t2),
Tbl_6 AS (Select t1.C From Tbl_5 t1 Cross Join Tbl_3 t2)
Select DATEADD(SECOND, r * 2.63, '2016-01-01') As RegisterDate, r As Id Into Tbl_Test
From
( Select Top 12000000 ROW_NUMBER() Over(Order By (Select Null)) As r From Tbl_6 ) t
GO
The table has two columns: RegisterDate and Id. I’ll create a regular clustered index on the table:
CREATE CLUSTERED INDEX IX_RegisterDate on Tbl_Test (RegisterDate)
GO
In the next step, I will create another table with an identical structure and then a clustered columnstore index on this new table:
DROP TABLE IF EXISTS Tbl_CCI
CREATE TABLE Tbl_CCI
(RegisterDate DateTime Not Null, Id Int Not Null)
GO
CREATE CLUSTERED COLUMNSTORE INDEX IX_CCI On Tbl_CCI<br />GO
Note: The source table is organized by the RegisterDate column. I want to populate the second table using the source table data as follows:
INSERT INTO Tbl_CCI
SELECT * FROM Tbl_Test
GO
The following images show there are 12 rowgroups for each column. SQL Server knows the minimum and maximum values for each rowgroups.
The first image presents information about the RegisterDate column:

The second image presents information about the Id column:

I want to write a query that retrieves the maximum ID from 27th March 2016 to 28th March 2016.
SET STATISTICS IO ON
SELECT Max(Id)
FROM dbo.Tbl_CCI
WHERE RegisterDate BETWEEN '2016-03-27' AND '2016-03-28'
GO
To get IO statistics, I used the command below:
SET STATISTICS IO ON
The following image shows that SQL Server read one rowgroup and skipped 11 rowgroups:
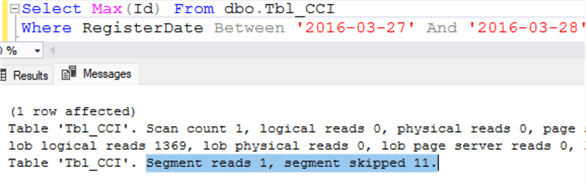
Also, you can see in the image that the number of lob logical reads is 1369.
Why Do We Need to Rebuild the Clustered Columnstore Index?
To remove the fragmentation, move all the delta store rows to columnstore and physically delete the rows marked for deletion, we need to rebuild the CCI. To maintain simplicity in this article, I will avoid delving into index fragmentation and assume we need to rebuild the CCI. I do this with the command below:
ALTER INDEX IX_CCI On Tbl_CCI Rebuild
GO
Once the Clustered Columnstore Index (CCI) has been rebuilt, I will rerun this query:
SELECT Max(Id)
FROM dbo.Tbl_CCI
WHERE RegisterDate BETWEEN '2016-03-27' AND '2016-03-28'
GO
The following image shows that SQL Server read seven rowgroups and skipped six rowgroups:

As shown in the image above, there has been an increase in the number of lob logical reads, totaling 8166.
To address the issue, I will employ data partitioning.
The script provided below demonstrates the creation of a Partition Function and Partition Scheme, followed by the partitioning of the table using the RegisterDate column as the partition key.
CREATE PARTITION FUNCTION PF_Monthly(dateTime)
AS RANGE RIGHT FOR VALUES
(
'2016-02-01', '2016-03-01', '2016-04-01', '2016-05-01',
'2016-06-01', '2016-07-01', '2016-08-01', '2016-09-01',
'2016-10-01', '2016-11-01', '2016-12-01'
)
GO
CREATE PARTITION SCHEME PS_Monthly
AS PARTITION PF_Monthly
ALL TO ([PRIMARY])
GO
DROP INDEX IX_CCI On Tbl_CCI
CREATE CLUSTERED INDEX IX_CCI On Tbl_CCI (RegisterDate)
On PS_Monthly (RegisterDate)
GO
CREATE CLUSTERED COLUMNSTORE INDEX IX_CCI On Tbl_CCI
With (Drop_Existing = On) On PS_Monthly (RegisterDate)
GO
The query below provides details about the partitioned table, including the partition number, the number of rows in each partition, and the compression type for each partition.
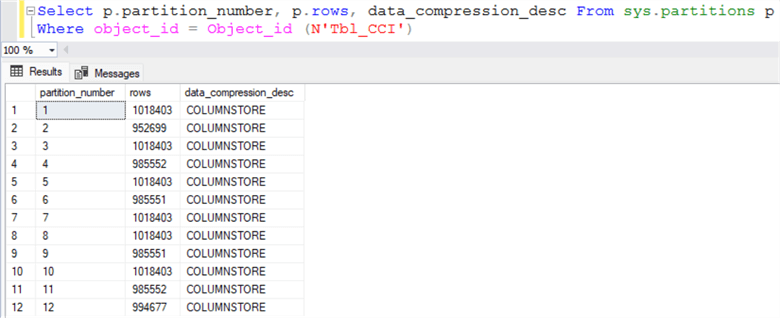
This table has been partitioned on a monthly basis, with the boundaries set at specific dates. The partition boundaries start from February 1, 2016, and continue sequentially until December 1, 2016.
Once the table has been partitioned, I will rerun the query to make a comparison of the number of lob logical reads:
SELECT Max(Id)
FROM dbo.Tbl_CCI
WHERE RegisterDate BETWEEN '2016-03-27' AND '2016-03-28'
GO
As depicted in the image below, the count of lob logical reads has been reduced to 1329.

Another advantage of data partitioning is the ability to rebuild individual partitions, which is more cost-effective than rebuilding the entire table.
Summary
As shown, rebuilding the Clustered Columnstore index reduced the number of row groups skipped. This reduction had a negative impact on query performance. Choosing the appropriate partitioning function ensures effective rowgroup elimination.
Next Steps
- SQL Server Columnstore Indexes
- How to Partition a SQL Server Table with a Columnstore Index
- How to Partition an Existing SQL Server Table

Mehdi Ghapanvari is an SQL Server database administrator with 6+ years of experience. His main area of expertise is improving database performance. He is skilled at managing high-performance servers that can handle several terabytes of data and hundreds of queries per second, ensuring their availability and reliability. To enhance the performance of the database, he has implemented various performance-tuning techniques, including query optimization and index tuning. He has also developed backup and recovery strategies to protect critical data in case of disasters. Mehdi currently manages the SQL Server databases for a large organization. Mehdi is actively seeking new opportunities to apply his expertise and contribute to impactful projects. You can reach him at SQLDBA.Mehdi@Gmail.com.
- MSSQLTips Awards: Rookie of the Year – 2023
- MSSQLTips Trendsetter Award: 2026


