Problem
The amount of data in data warehouses is growing rapidly. At the same time, the query performance against these same data warehouses is degrading. I heard SQL Server 2012 introduces a new way of creating/managing/storing indexes which improves the performance of these common data warehousing queries several fold, in some cases 10 to 100 times faster. So what is this new feature? How can you build it? How does it get stored by SQL Server and how does it improve the performance of common data warehousing queries? Read this tip to learn more.
Solution
ColumnStore Indexes are the functionality which was introduced with SQL Server 2012 which intends to improve the performance of common data warehousing queries. This new functionality includes ColumnStore Indexes and Batch mode (vector based) query processing/execution capabilities. The later one is used by the query optimizer internally to process the request in batches when the query execution plan uses at least one ColumnStore Index. The processing of a batch at a time speeds up joins, filtering and aggregations (in comparison with row at a time processing) and better utilizes today’s multicore/multi-processors hardware. The choice to use either batch mode query processing or traditional row mode query processing is determined by the query optimizer.
Understanding SQL Server ColumnStore Indexes
The syntax for creating a ColumnStore Index is not much different from creating traditional Row Store/B-Tree indexes, but the difference lies in the way data gets stored/accessed in the pages on disk. The traditional Row Store Index gets stored in a B-Tree structure and data from all the columns of the index (of the row) are stored continuously on the same page (applies to heap as well). This type of index is good in cases (OLTP) where you use predicates to filter the data or scan data from all the columns of the indexes, but for OLAP systems it poses some problems such as:
- In the case of a Row Store Index, data from all the columns of the rows are stored together on the same page and hence it has a small ratio of redundancy on each page (data from different columns normally would not be similar), meaning compression would not be beneficial.
- In the case of a Row Store Index, data from all the columns of the rows are stored together on the same page and no matter if you are selecting all the columns of the index or only few, it pulls out pages containing data of all the columns of the index into memory and yielding a significantly higher IO ratio, especially in case of a fact table which has dozens of columns and only few of them are normally referenced in the query.
ColumnStore Indexes also store each column data in separate pages (column wise fashion) rather than the traditional Row Store Index, which stores data from all the columns of a row together contiguously (row wise fashion), this way when you query. If your query only selects a few columns of the index, it reads less pages as it needs to read data of selected columns only and improves the performance by minimizing the IO cost.
Compression can be more effective for a ColumnStore index as data from each column is stored separately and redundancy (repetitive values) of the data in each column in each page is high. This means highly compressed pages takes less IO to bring the data into memory and effectively reduce query response time, especially for subsequent query execution.
As data gets stored in column wise fashion, your query selecting only few columns will reference only pages that contain data of those columns, which would normally be 10%-20% in a typical data warehouse scenario. This means you are reducing the IO by 80%-90%.
Please note, ColumnStore Indexes might be good when scanning and aggregating data in large fact tables involving star schema joins, whereas Row Store Indexes may offer better query performance for very selective queries, such as queries that lookup a single row or a small range of rows. In addition, ColumnStore Indexes are created to accelerate common data warehouse queries and would not be suitable for OLTP workloads.
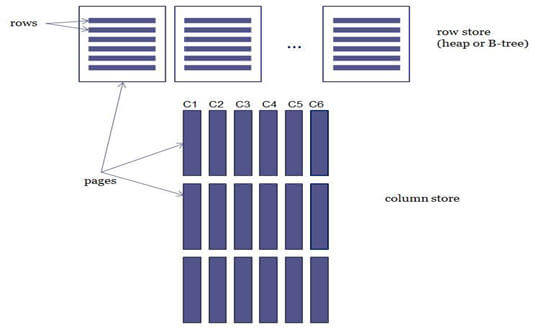
Row Store Index values from all the columns of the rows are stored together on the same page as shown in the top portion of the image whereas with ColumnStore Indexes values from a single column (multiple rows) are stored together as shown on the bottom portion of the image. Image source.
Benefits of using SQL Server ColumnStore Indexes
There are several benefits of using ColumnStore indexes over Row Store Indexes as outlined below:
- Faster query performance for common data warehouse queries as only required columns/pages in the query are fetched from disk
- Data is stored in a highly compressed form (Vertipaq technology) to reduce the storage space
- Frequently accessed columns (pages that contains data for these columns) remain in memory because a high ratio of compression is used in the pages and less pages are involved
- Enhanced query processing/optimization and execution feature (new Batch Operator or batch mode processing) improves common data warehouse queries’ performance
Limitations of SQL Server ColumnStore Indexes
There are several limitations of using SQL Server ColumnStore indexes over Row Store indexes including:
- A table with a ColumnStore Index cannot be updated
- ColumnStore index creation takes more time (1.5 times almost) than creating a B-tree index (on same set of columns) because the data is compressed
- A table can have only one ColumnStore Index and hence you should consider including all columns or at least all those frequently used columns of the table in the index
- A ColumnStore Index can only be non cluster and non unique index; you cannot specify ASC/DESC or INCLUDE clauses
- Not all data types (binary, varbinary, image, text, ntext, varchar(max), nvarchar(max), etc.) are supported
- The definition of a ColumnStore Index cannot be changed with the ALTER INDEX command, you need to drop and create the index or disable it then rebuild it
- You can create a ColumnStore index on a table which has compression enabled, but you cannot specify the compression setting for the column store index
- A ColumnStore Index cannot be created on view
- A ColumnStore Index cannot be created on table which uses features like Replication, Change Tracking, Change Data Capture and Filestream
Loading data into a SQL Server table with a ColumnStore Index
As I said before, a table with ColumnStore Index is not updatable, so you will need to work out a way to update it. Luckily we have couple of options, for example, dropping/disabling index, loading data and rebuilding index again or load the data in a table, create ColumnStore Index on the table and then switch in that table in the main table, if the main table is partitioned.
Creating a SQL Server ColumnStore Index
First of all, you can have only one column store index on each table. This index should be a non clustered index that should ideally include all the columns of the table. This is generally the best practice because all of the columns can be accessed independently from one another. The general syntax for creating ColumnStore Indexes has been provided below, but keep in mind you can also create ColumnStore Indexes using the Object Explorer in SSMS:
CREATE NONCLUSTERED COLUMNSTORE INDEX <IndexName>
ON <TableName>
(
Col1,
Col2,
….
….
Coln
)
GO
I am going to use the FactInternetSales fact table from the AdventureWorksDW2008R2 database for this demonstration. Please note, this table is not that large to demonstrate the performance gains possible with ColumnStore Indexes, but the idea is to start working with ColumnStore Indexes to understand how the query optimizer uses it for better performance and how to identify batch mode processing in the query plan. In the script below, I am creating a ColumnStore Index on the FactInternetSales table and including all of the frequently used columns from that table in the index. As I said before, you can choose to include all columns from the table and as the data gets stored in highly compressed form.
USE AdventureWorksDW2008R2
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX CSI_FactInternetSales
ON dbo.FactInternetSales
(
ProductKey,
OrderDateKey,
DueDateKey,
ShipDateKey,
CustomerKey,
PromotionKey,
CurrencyKey,
SalesTerritoryKey,
SalesOrderNumber,
SalesOrderLineNumber,
TotalProductCost,
SalesAmount
)
GO
Now its time to run some queries against the fact table on which we created the ColumnStore Index to see how the query optimizer uses it and how it improves the query performance. I have provided two sample queries below. For the first one, the query optimizer will by default use the column store index since all of the required columns’ data is available. The second query is same as the first one, but this time I am instructing query optimizer to ignore the ColumnStore Index with the OPTION clause as highlighted below and use the row store index instead (in this case cluster index):
SELECT F.SalesOrderNumber, F.OrderDateKey, F.CustomerKey, F.ProductKey, F.SalesAmount
FROM dbo.FactInternetSales AS F
INNER JOIN dbo.DimProduct AS D1 ON F.ProductKey = D1.ProductKey
INNER JOIN dbo.DimCustomer AS D2 ON F.CustomerKey = D2.CustomerKey
SELECT F.SalesOrderNumber, F.OrderDateKey, F.CustomerKey, F.ProductKey, F.SalesAmount
FROM dbo.FactInternetSales AS F
INNER JOIN dbo.DimProduct AS D1 ON F.ProductKey = D1.ProductKey
INNER JOIN dbo.DimCustomer AS D2 ON F.CustomerKey = D2.CustomerKey
OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX)
GO
Below are the execution plans for the two queries. As you can see for the first query, the query optimizer uses the ColumnStore Index Scan operator (a brand new operator introduced in this release) whereas the second query uses Clustered Index Scan operator (as we asked explicitly to ignore column store index). Now look at the total cost of each query relative to the other one. Even though both the queries are the same (and returns the same set of data to the client) the first one, which uses column store index, has 14% of the cost relative to the batch whereas the second one, which does not use column store index and uses cluster index instead, has 86% of the cost relative to the batch:

As I said before, SQL Server has one more operation specifically for ColumnStore Indexes and this is evident when you hover your mouse over the ColumnStore Index Scan icon in the above execution plan. It will display details about this operator as shown below, notice the estimated I/O Cost for this operator and compare it with the one for Clustered Index Scan of the second query:

We all know that the slowest part of a query execution is cost of IO (Input/Output), so the idea behind column store index, to reduce the IO cost by storing the data in column form, retrieving only those pages which contain data from the selected columns in the query and compressing the data on the page so that the total number of required pages can be reduced to a minimum. If you look at the image below, this is the IO statistics of the above two queries, the first query which uses ColumnStore Index has significantly less IO in comparison to the second query, which does not use column store index (instead it uses row store/clustered index):

Now let’s turn our attention to using aggregation. The two queries below are re-writes of the above queries, but this time I am using SUM function for summing up total sales for each day. The first query will use ColumnStore Index whereas the second query uses row store index (clustered) as we have specifically indicated to not use column store index by the query optimizer for the second query as highlighted:
SELECT F.OrderDateKey, SUM(F.SalesAmount) AS TotalSales
FROM dbo.FactInternetSales AS F
INNER JOIN dbo.DimProduct AS D1 ON F.ProductKey = D1.ProductKey
INNER JOIN dbo.DimCustomer AS D2 ON F.CustomerKey = D2.CustomerKey
GROUP BY F.OrderDateKey
SELECT F.OrderDateKey,SUM(F.SalesAmount) AS TotalSales
FROM dbo.FactInternetSales AS F
INNER JOIN dbo.DimProduct AS D1 ON F.ProductKey = D1.ProductKey
INNER JOIN dbo.DimCustomer AS D2 ON F.CustomerKey = D2.CustomerKey
GROUP BY F.OrderDateKey
OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX)
GO
This time, the execution plan of the first query indicates that it uses the ColumnStore Index rather than the Row Store Index of the second query and hence the cost of the first query is 26% relative to the batch and the cost of the second query is 74% relative to the batch. Once again the ColumnStore Index performance exceeds the traditional Row Store Indexes.

Please note the following items about ColumnStore Indexes
- Example shown above is based on a table which has far less records as compared to production data warehouses. The expectation is that the performance improvement would be much higher than the example above for common data warehouse queries where a large amount of data scanning, data filtering and aggregation is involved. One study of an aggregation query on a 1 TB fact table with 1.44 billion records resulted in a 16 times improvement in CPU cycle and 455 times improvement in elapsed time if the query uses the ColumnStore Index. For more information click here.
Next Steps
- Review ColumnStore Indexes article on MSDN.
- Review SQL Server ColumnStore Index FAQ.
- Download ColumnStore Indexes for Fast Data Warehouse Query Processing in SQL Server 11.0 technical article from Microsoft download center.
- Review all my previous tips.

Arshad specializes in Database, Data Warehousing and Business Intelligence application design, development and deployment, at enterprise level, with SQL Server, SSIS, SSRS, SSAS, Service Broker, MDS, DQS, SharePoint and PPS. He is a Microsoft Certified IT Professional in Microsoft SQL Server. He also has experience developing applications in VB/ASP/.NET/ASP.NET/C#, and is a Microsoft Certified Application Developer and Solution Developer for the .NET platform in Web/Windows/Enterprise. Arshad has Master’s degrees in Computer Applications and Business Administration in IT.
Disclaimer: Arshad worked for Microsoft and helped people and businesses make better use of technology to realize their full potential. The opinions mentioned in his tips and articles herein are solely his and do not reflect those of his current or previous employers.
- MSSQLTips Awards: Champion (100+ tips) – 2014