By: Aaron Bertrand | Updated: 2023-11-01 | Comments | Related: More > Database Administration
Problem
If there has been one constant throughout my career, it's change. As applications become more complex and we continue improving reliability, there will always be the next patch, upgrade, new replica, new cluster, and even new cloud region – or moving to the cloud in general. For complex architectures, multiple teams are often actively involved, and even more who want to be "in the know" during any changes.
We use tickets (JIRA) to track and document the work, and incidents (FireHydrant) to expose the status to internal and external customers. But these are complex systems to keep current in real-time. And while nearly everything we do is scripted, broad audiences can't consume code – even when saturated with comments. Since multiple teams are involved, the code is scattered across disparate things like runbooks, which are not easy or desirable to combine. How can a wide range of people stay coordinated during a major change?
Solution
Enter deployment documents containing simple checklists. Checklists have been around longer than I have, but I think that because they're such a low-tech solution, they're overlooked and undervalued. While they are not the primary script or source of record, they can be a very useful way to keep everybody on the same page – regardless of role or technical level.
We use Google Docs, but any collaborative platform will do. One of my favorite features in Docs specifically is a list that you can check off as you go. For example:
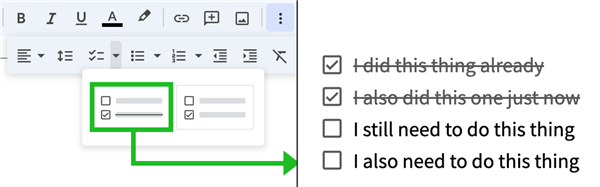
We go a step further, like using sections for operational phases and primary/secondary personnel, and color coding to indicate task ownership and estimated timing. We are also generous with links to the overarching JIRA ticket, any relevant pull requests in GitHub, the maintenance incident in FireHydrant, and the incident Slack channel. Below is a more specific, but still fictitious, example (which you can see in real life here, in case you want to borrow it):
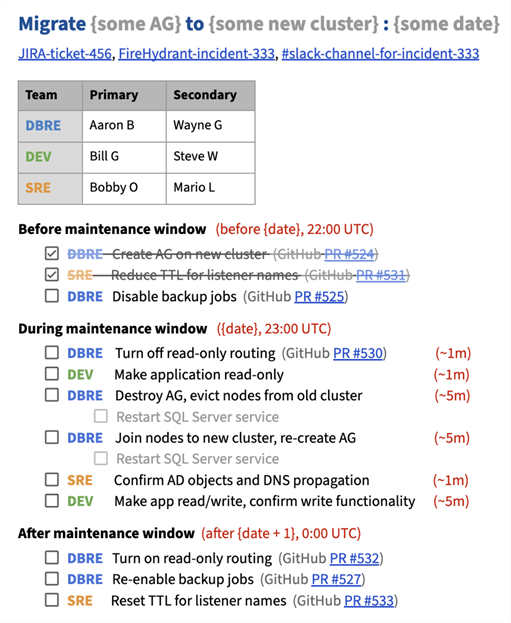
Some important things to note about the checklist in general include:
- Headline: The headline should answer, "What is this maintenance, and when is it happening?"
- Links: There
should be prominent links for easy access to:
- Any epics, stories, or Slack conversations describing or justifying the work.
- The incident, incident channel, meeting, and rollback document.
- (The rollback document is just as important – don't assume happy path is guaranteed.)
- Members: Always indicate who is involved from each relevant team and who else may fill in or help.
- Milestones: You should have a section for each "chunk of work" and indicate when that starts.
- Assignments:
Each item should be "assigned" to a team, not a specific person.
- Secondary should be able to fill in at a moment's notice.
- Scripts: Where
relevant, items should point to the PR/script that will be used.
- This lets each item be high-level but provides access to more technical details.
- Duration: Estimate time to completion, particularly for items during the maintenance window.
- Completion: Check off each completed item and mark it with completion time. (I'm not sure if Google Docs can capture who checked a checkbox).
What I love about this technique is that everyone can follow along in a single, living document and knows what's been done, whether they're up next, and even if a task ran (or is running) longer than expected. Overruns are not always easy to relay, but transparency can help temper expectations during the incident, enabling us to come up with better estimates next time and make post-mortem analysis more accurate than someone's memory.
Pros and Cons
This approach isn't perfect – it can take some effort to put together, and it's not the source technical people will want to use for any deep details on the actual work.
| Pros | Cons |
|---|---|
|
|
Next Steps
Start using checklists to better organize the operation and keep other teams informed. You can borrow this one as an example template.
See these tips and other resources:
- SQL Server Code Deployment Best Practices
- SQL Server Code Review Checklist
- Defining and Establishing SQL Server Policies and Procedures
- Common SQL Server Development and Administrative Issues
- SQL Server Test Environment Benefits
- SQL Server Disasters with Preventive Measures






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-11-01
