Problem
Full wild card searches (e.g., SQL LIKE ‘%search_term%’) in Microsoft SQL Server can be slow and inefficient because they guarantee a scan on all the rows in the table. Are there any options to optimize SQL LIKE operator queries?
Solution
Optimizing case-insensitive, full wildcard searches with leading and trailing wildcards is challenging in SQL databases—these LIKE patterns do not benefit from indexing. This tutorial explores potential options to optimize these searches and examines common misconceptions.
Demo Setup
We will use the StackOverflow2013 database built on the SQL_Latin1_General_CP1_CI_AS collation as it fits our test requirement. The SQL tutorial will focus on the [dbo].[Comments] table, which contains 24,534,730 rows.
Benchmarking the Initial SQL LIKE Query
To establish the initial baseline, we will execute the SQL SELECT statement below that searches for the word “until” in the Text column of the [dbo].[Comments] table as specified in the WHERE clause.
SELECT COUNT(*)
FROM [dbo].[Comments]
WHERE Text LIKE '%until%'
OPTION (MAXDOP 8)
GOThis query is executed on a workstation with an Intel i7-13700 processor (2.1 GHz, 16 cores), 128 GB of RAM, and SQL Server 2019 Developer Edition. The Windows power option is set to Best Performance; otherwise, the query is seen to take double the benchmark duration.
The query is executed several times to ensure the table is loaded into the SQL Server buffer pool and the duration isn’t dependent on the storage subsystem.
The baseline query completes in 17 seconds consistently and returns a row count of 129,484 matching rows.

Wildcard Search Optimization Options
With the benchmark established, we will explore two options to improve the performance of this wildcard search. To ensure accuracy, the StackOverflow2013 database is restored from backup prior to each test to avoid interference from the previous test changes. Similarly, the query will be executed several times until the execution duration is consistent.
Utilizing Binary Collation
Binary collation affects how text data is compared and sorted. When binary collation is used, the comparison is done at the byte level rather than the character level, possibly leading to faster search performance.
Although the StackOverflow2013 database uses a non-binary, case-insensitive collation, we can achieve binary comparison by using the COLLATE clause in our queries without altering the table design.
To make the query case-insensitive, we apply the LOWER() or UPPER() function to both the Text column and the search term in the LIKE statement. Here is the SQL syntax:
SELECT COUNT(*)
FROM [dbo].[Comments]
WHERE LOWER(Text) COLLATE Latin1_General_100_BIN2 LIKE LOWER('%until%')
OPTION (MAXDOP 8)
GOThe execution duration drops to just 2 seconds and returns 129,484 rows, matching the baseline query result.

Outcome:
- The query completes in 2 seconds, returning the same row count as the benchmark query.
- No changes to the database collation are required; adding COLLATE to the column suffices.
Binary collations are based on the numeric values of characters (byte values) and thus avoid additional processing associated with linguistic collations. The documentation on the COLLATE clause also discusses how binary collations are case-sensitive and accent-sensitive, which can lead to faster comparisons due to their simplicity.
While binary collation improves performance, ensure that the case sensitivity requirement is maintained appropriately, as this could exclude relevant results if done incorrectly.
Utilizing Full-Text Search
Full-Text Search (FTS) is another good option in SQL Server for efficient text-based queries. FTS indexes are optimized for searching large text columns, dramatically speeding up wildcard searches.
The FTS query syntax has its own clauses, but is straightforward and easy to use. The asterisks are equivalent to the wildcard or percent sign as shown in this SQL statement:
SELECT COUNT(*)
FROM [dbo].[Comments]
WHERE CONTAINS(Text, '*until*')
OPTION (MAXDOP 8)
GOThe command below creates and populates the FTS index on the Text column of the [dbo].[Comments] table. You would want to allow a few minutes for the FTS population to complete before running the benchmark query.
USE StackOverflow2013
GO
CREATE FULLTEXT CATALOG FC_MSSQLTips_Demo AS DEFAULT;
GO
CREATE FULLTEXT INDEX ON dbo.Comments (Text LANGUAGE 1033)
KEY INDEX PK_Comments_Id
ON FC_MSSQLTips_Demo
WITH STOPLIST = SYSTEM;
GO
ALTER FULLTEXT INDEX ON dbo.Comments START FULL POPULATION;
GOThe FTS query completes in a sub-second, a major improvement. However, it returns 127,935 rows. This is 1,549 fewer rows than the original query.
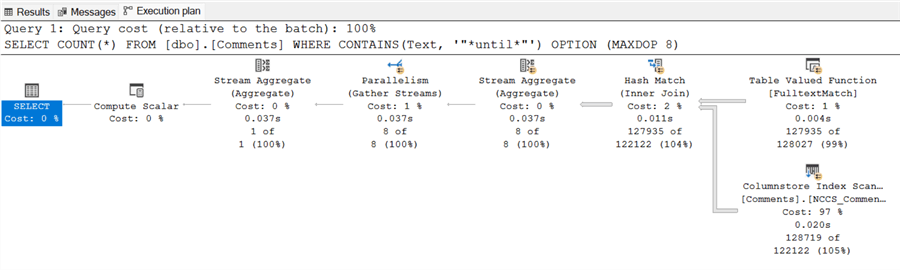
Outcome:
- The query execution finishes in 37 ms, a substantial improvement over the original 17 seconds.
- However, this speed came at a cost. The query returned 127,935 rows, 1,549 fewer than the original query.
FTS can significantly enhance performance; however, it may come at the cost of accuracy, depending on your requirements. FTS does not seem to get the leading wildcard unless the search term is a full word following the wildcard.
In the screenshot below, the search term “until” is not the leading word, causing the query to miss it and highlighting a limitation of FTS. This limitation may be acceptable in some cases. For example, if users want to search within product descriptions and expect results to contain the search word regardless of word placement, then FTS might not be a good option.

Wildcard Searches and Indexes
A common misconception is that indexes can help optimize wildcard searches. Let’s examine two types of indexes to see if they offer any performance benefits.
Non-clustered Index
A non-clustered index is a smaller, separate structure of the indexed column that is not part of the main table. There is a partial truth that indexes can help with wild card search performance. It will only work when the wildcard is placed at the end of the search term.
CREATE NONCLUSTERED INDEX IX_Comments_Text ON dbo.Comments (Text)
GO
The ad-hoc query below is adjusted to maintain only the wild card at the tail of the search term:
SELECT COUNT(*)
FROM [dbo].[Comments]
WHERE Text LIKE 'until%')
OPTION (MAXDOP 8)
GO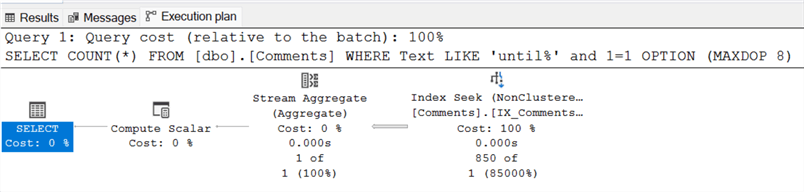
Outcome:
- The non-clustered index offers no performance improvement for full wild card searches.
Column Store Index
Another test is to create a non-clustered column store index, which is often beneficial in large-scale data warehousing environments. The main benefit of column store index is on large aggregations, not so much on text columns, especially searches.
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCS_Comments_Text ON dbo.Comments (Text)
GO
Outcome:
- The query took 4 seconds longer to complete execution than it did on the row store index.
- Column store indexes are generally not well-suited for wild card searches, especially on text-heavy columns.
Conclusion
Optimizing wildcard searches in SQL Server is complex and highly dependent on the specific use case. Techniques such as binary collation and Full-Text Search can yield significant performance improvements, but each has trade-offs. Testing and profiling SQL queries are crucial to determine the most effective approach.
While non-clustered and column store indexes are generally useful, they offer limited benefit for text-heavy wildcard searches.
Next Steps
- COLLATE
- CONTAINS
- SQL Server Collation Overview and Examples
- Collation and International Terminology
- Guidelines for Using BIN and BIN2 Collations
- Full-Text Search
- Collation and Unicode support

Simon Liew is an independent SQL Server Consultant in Sydney, Australia. He is a Microsoft Certified Master for SQL Server 2008 and holds a Master’s Degree in Distributed Computing.
- MSSQLTips Awards: Trendsetter (25+tips) – 2017 | Author of the Year Contender – 2016, 2017

on a wide table (with many columns) a nonclustered index on the text column will help.
Simply assume, that you have 60 columns (including a few varchar) and are searching in the comment column, resulting in an average row size of 1200 bytes (with AVG(LEN(comment)) = 300).
Without a nonclustered index SQL server has to read all 60 columns / 1200 bytes of every row, even if it needs just the longer or shorter comment column (that may even be empty). With a nonclustered index it just needs to read the 300 bytes of the comment (and can skip all empty ones) plus the few bytes of the clustered index column (often an ID column), so it would reduce the pages read by ~75%
While I agree that things like the Tri-Gram solution are much more effective for anything that will need to be permanent and used often, this method makes a one-off search a lot easier. It may also make things like the Tri-Gram solution quicker, as well.
What else that I find interesting is your proof that that Full Text Search misses things. I’ve never liked FTS and now I have another reason.
With all that, thanks for the time you spent on the code and with writing this article.
I tested it with ‘COLLATE Latin1_General_100_BIN2’ on a text column in a table with 3 million records, but it had no effect, the same number of READs.
Mario, binary collation in SQL Server ends with the suffixes _BIN or _BIN2. The reference below would have more details for you
https://learn.microsoft.com/en-us/sql/relational-databases/collations/collation-and-unicode-support?view=sql-server-ver16#Binary-collations
Thank you for the article.
How can I know which collations are binaries?
All “solutions” in the article result in full scans. Which means bad solution. They do not scale with db size at all. Every day this search will get slower, and server will probably “die” if many users start searching.
Solution that scales and is super-fast is TRIGRAM SEARCH: https://sqlperformance.com/2017/09/sql-performance/sql-server-trigram-wildcard-search
I have implemented it (with some modifications, not exactly as in article but a bit improved) with a great success.
Firstly thank you for a helpful article, and interesting and surprising result using binary collation.
A couple of minor points: firstly the difference in results when using FTS I wouldn’t really characterise as a “limitation” but rather by design given the purpose of full text indexing. Secondly, where a column is not huge, but will be the subject of two tailed wildcard searches, then an NC index on that column may help because the index rather than the table, will be scanned, reducing the reads needed. (Given that usually the data are unlikely to be already cached.)